Principal @Atlassian | Helping engineers reach Staff/Principal | 1:1 Mentorship & Mock Interviews | 90+ System design fundamentals - https://t.co/Ots2nRhO5f
Jun 12 • 8 tweets • 7 min read
I've started a 25-day series on Scaling and Architecture.
One topic per day.
As a Principal Backend Engineer with 12+ years of building systems at scale, I want to break down every concept I wish someone explained to me earlier in my career.
Day 1 was Load Balancing.
Today is Day 2: CDN.
Follow along if you're serious about system design. This will be worth your time.
Day 1: x.com/system_monarch…
If you want all 90+ system design fundamentals in one place, I've put together a guide here → puneetpatwari.in
Jun 11 • 8 tweets • 6 min read
I've been a backend Engineer for 12+ years. Today, I'm a Principal Engineer at Atlassian.
I've designed systems that handle millions of requests. Sat on both sides of system design interviews.
Reviewed more architecture docs than I can count.
Starting today, I'm breaking down the fundamentals of scaling for the next 25 days.
If you're learning system design bookmark this thread, you're going to get a lot of learning from this.
LOAD BALANCING: Day 1/25
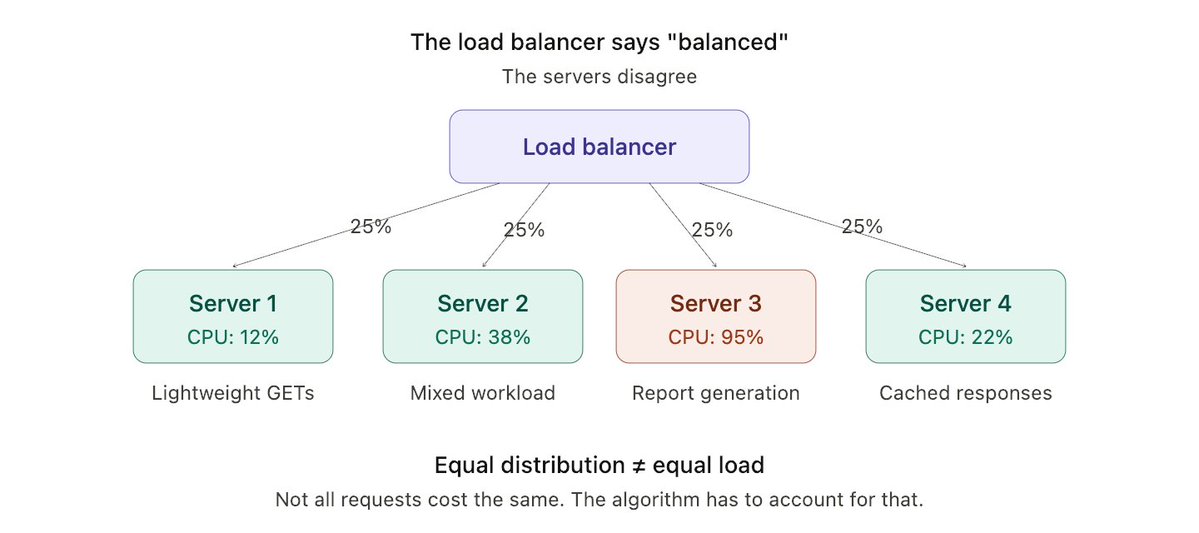
Your load balancer is lying to you.
It says traffic is "balanced." What it really means is: requests are being distributed. Whether they're distributed well is a completely different question.
I've seen a system with 4 servers where Server 3 was at 95% CPU while Server 1 sat at 12%. The load balancer said everything was fine.
A load balancer doesn't know what's happening inside your servers. It doesn't know one request takes 2ms and the next takes 12 seconds.
Your choice of algorithm, layer, and health check strategy is the difference between actual balance and the illusion of it.
Let me break it down. 🧵Your load balancer is lying to you.
May 25 • 7 tweets • 3 min read
30 AI system design problems that will teach you 80% of the important concepts that keep repeating across SD interviews for AI/ML roles at top companies.
AI system design gets a lot easier once you stop memorizing random architectures and start seeing the same building blocks everywhere.
Model serving.
Embeddings.
RAG.
Caching.
Evaluation.
Data pipelines.
Moderation.
Latency.
Safety.
Monitoring.
Feedback loops.
Learn these through problems and the whole field starts making more sense.
[1] Set 1: Core AI platforms
Design an AI Copilot
➸ Agent orchestration, tool calling, context windows, memory, permissions, evaluation
Design a GPT-like Model Training Platform
➸ Data ingestion, distributed training, GPU scheduling, checkpoints, experiment tracking, model registry
Design a Multi-Modal AI Search Engine
➸ Image embeddings, text embeddings, vector search, metadata filters, ranking, freshness
Design a Real-Time AI Translation System
➸ Streaming inference, latency budgets, batching, model routing, fallback models, quality checks
Design an Autonomous Agent Platform
➸ Planner executor loop, task queues, tool sandboxing, state management, human approval, guardrails
Design a Large-Scale AI Inference Serving System
➸ Model serving, dynamic batching, GPU utilization, autoscaling, request routing, SLOs
May 11 • 9 tweets • 3 min read
Idempotency has a dirty secret: the happy path always works. It's the weird ones that bankrupt you. The late retry. The payload that changed between attempts.
7 edge cases that break most implementations, and how to actually fix each one. 🧵
1. The retry has a different payload.
Client times out. User changes the amount from $50 to $75. Client retries with the same idempotency key but the new amount.
Most systems silently return the old $50 result. The user sees $75 on their screen but gets charged $50. Support ticket incoming.
Fix: Store a hash of the original request body alongside the idempotency key. When a retry arrives, compare hashes. If they differ, return a 422 with a clear error telling the client to generate a new key. Stripe does exactly this.
May 3 • 22 tweets • 6 min read
Message Queues & Event-Driven Patterns are the backbone of every scalable modern system - Netflix, Uber, and Atlassian all run on them.
Most engineers know the basics (“just throw a queue in there”), but interviewers destroy you with the deep follow-ups:
“How do you guarantee exactly-once processing when a Kafka broker dies mid-replay?”
“How do you handle poison messages without crashing your entire consumer fleet?”
“What happens to your Sagas during a partial failure at 50k events/sec?”
These 20 must-know Message Queues & Event-Driven Patterns take you from high-level overview to production-grade depth that actually ships reliably at scale.
Save this thread. Read till the end.
1) Producer-Consumer Pattern
The fundamental building block: producers publish messages to a queue/topic; consumers pull and process them asynchronously.
Decouples services, enables horizontal scaling, and smooths traffic spikes.
How to learn it: Implement a classic producer-consumer in Spring Boot + Kafka (or RabbitMQ). Use Locust to simulate 10x burst traffic and measure consumer lag with Kafka’s consumer lag exporter. You’ll see exactly why this pattern prevents cascading failures.
Apr 23 • 11 tweets • 5 min read
I have 12+ years of experience in backend engineering and now work as a Principal Engineer.
One thing I’ve noticed is this: A lot of engineers want to become “backend architects” because the title sounds cool.
But very few actually understand what that role requires.
It is not just:
- knowing Kafka
- drawing boxes in interviews
- saying “let’s use microservices”
- or memorizing CAP theorem
If you want to become one, here are 10 areas you need to learn well:
1) Microservices Design
Most people think microservices means:
split code into many services.
That is the easy part.
The hard part is deciding:
- where service boundaries should exist
- what belongs together
- what should stay in the monolith
- how much coupling is too much
- how failures propagate across services
Why it matters:
A badly split microservice system is worse than a monolith. Now you have network hops, distributed failures, ownership confusion, and deployment pain on top of bad design.
How to learn it:
Take one medium-sized monolith and try to break it into services on paper.
Then ask:
- which data now becomes cross-service?
- what APIs need to exist?
- what failures did I just introduce?
Apr 21 • 22 tweets • 5 min read
I have 12 years of experience and working as a Principal Engineer @Atlassian and I have seen concurrency scaring the hell out of a lot of junior engineers.
It’s one of the most feared topics in system design & backend interviews — race conditions, deadlocks, thread pools… you name it.
But once you internalize these 20 must-know concepts, everything clicks.
Save this thread. Read till the end.
Your future interviews and production systems will thank you.
1) Concurrency
Multiple tasks make progress by taking turns on one CPU (or across cores).
It’s about dealing with many things at once, even if not truly simultaneous.
Why it matters: Almost every modern backend, mobile, or distributed system is concurrent.
How to learn it: Take any single-threaded program and refactor it to handle multiple requests using threads or async. Visualize the timeline of execution.