
We're in a race. It's not USA vs China but humans and AGIs vs ape power centralization.
@deepseek_ai stan #1, 2023–De...

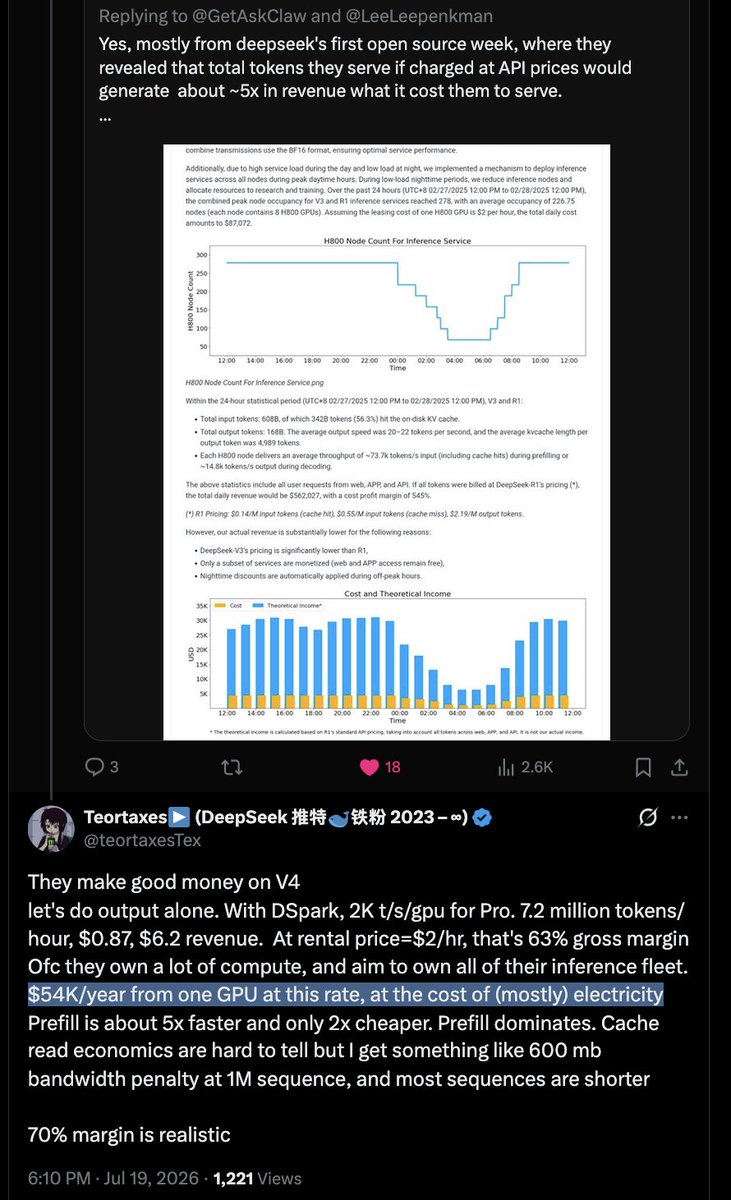
 Wenfeng's specific notion of "reasonable profit": recouping the cost of compute acquisition within 10 months. He has that now.
Wenfeng's specific notion of "reasonable profit": recouping the cost of compute acquisition within 10 months. He has that now.

 while we're at it @elonmusk @nikitabier who do I petition to lift the curse of Chynese replybots? They outnumber real humans in my replies now. They're also very mid. Tofu bots really. But I guess it doesn't take much to crowd out the meat.
while we're at it @elonmusk @nikitabier who do I petition to lift the curse of Chynese replybots? They outnumber real humans in my replies now. They're also very mid. Tofu bots really. But I guess it doesn't take much to crowd out the meat. 

 Btw I realize that it's unwise posting this stuff. In due time they will really go after anyone dissing them, will throw the entire weight of the US law and worse at them, even if this is all content they openly and proudly publish in English for public outreach. I'm irrational.
Btw I realize that it's unwise posting this stuff. In due time they will really go after anyone dissing them, will throw the entire weight of the US law and worse at them, even if this is all content they openly and proudly publish in English for public outreach. I'm irrational.



 They turn hyper-connections from academic curiosity into a basic design motif. This is what I've long expected from them – both mathematical insight and hardware optimization. ResNets for top-tier LLMs might be toast.
They turn hyper-connections from academic curiosity into a basic design motif. This is what I've long expected from them – both mathematical insight and hardware optimization. ResNets for top-tier LLMs might be toast.


 A little bit schizophrenic but ok. Baby steps.
A little bit schizophrenic but ok. Baby steps. 


 EVERYONE KNEW THIS WILL HAPPEN
EVERYONE KNEW THIS WILL HAPPEN

 But they are consistent in that they share milestones in their internal exploration. So what is this milestone? I think they are doing fundamental research on attention. Perhaps they've concluded that "native sparse" is too crude; that you need to train attentionS in stages.
But they are consistent in that they share milestones in their internal exploration. So what is this milestone? I think they are doing fundamental research on attention. Perhaps they've concluded that "native sparse" is too crude; that you need to train attentionS in stages.
 I don't care about moralizing or finger pointing. You simply cannot make a case for having a kid that sounds compelling to a normal zoomer woman. The world in the context of which these arguments made sense is outside their consensus reality. They were born to live as teenagers.
I don't care about moralizing or finger pointing. You simply cannot make a case for having a kid that sounds compelling to a normal zoomer woman. The world in the context of which these arguments made sense is outside their consensus reality. They were born to live as teenagers.
 That's it. Just multi-objective optimization. In K2's own words, “Because the feasible set is tiny (DSv3 topology + cost caps), the search collapses to tuning a handful of residual parameters under tight resource budgets”.
That's it. Just multi-objective optimization. In K2's own words, “Because the feasible set is tiny (DSv3 topology + cost caps), the search collapses to tuning a handful of residual parameters under tight resource budgets”.


 It's all right to refuse to trust this. That's the spirit. But I have to say, I'd like the United States Department of State to make a similar commitment. I do not want to kowtow to anybody. And I don't want a Planetary Kang who'll tell my leader to kiss his ass.
It's all right to refuse to trust this. That's the spirit. But I have to say, I'd like the United States Department of State to make a similar commitment. I do not want to kowtow to anybody. And I don't want a Planetary Kang who'll tell my leader to kiss his ass.


 «the company had just formed a new project team responsible for research and preparation related to cluster construction, so I went to "build a server room." Without lengthy prior training, at High-Flyer, I was immediately given tremendous autonomy.»
«the company had just formed a new project team responsible for research and preparation related to cluster construction, so I went to "build a server room." Without lengthy prior training, at High-Flyer, I was immediately given tremendous autonomy.»
 R1 analyzes its common motifs:
R1 analyzes its common motifs:


 xi my son. yuo are chairman now. you must choose tech tree to invest in and have greatness
xi my son. yuo are chairman now. you must choose tech tree to invest in and have greatness

 "Multi-token Prediction" is an important work afaict
"Multi-token Prediction" is an important work afaict


 Such a beautiful model.
Such a beautiful model. 

 Scott Alexander is not a true doomer, but his thinking about AI risk is informed by the LW doctrine, which is all about maximizing (misaligned) utility & emergent coherence (eg lesswrong.com/posts/RQpNHSiW…). First principles arguments for it seem weakened now: forum.effectivealtruism.org/posts/NBgpPaz5…
Scott Alexander is not a true doomer, but his thinking about AI risk is informed by the LW doctrine, which is all about maximizing (misaligned) utility & emergent coherence (eg lesswrong.com/posts/RQpNHSiW…). First principles arguments for it seem weakened now: forum.effectivealtruism.org/posts/NBgpPaz5… 





 Not sure if many have read to this point: they also claim their (not released) code and math finetunes are SOTAs for <34B
Not sure if many have read to this point: they also claim their (not released) code and math finetunes are SOTAs for <34B