
Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Joining @NYU_Courant Fall 2026. Co-EiC @TmlrOrg. I lead @TheSalonML.
 A good place to start is my thread and AMA from last year. In short, Canada and US are incredibly similar in several dimensions, including culturally and geographically. We talk everything from admission requirements to money.
A good place to start is my thread and AMA from last year. In short, Canada and US are incredibly similar in several dimensions, including culturally and geographically. We talk everything from admission requirements to money.
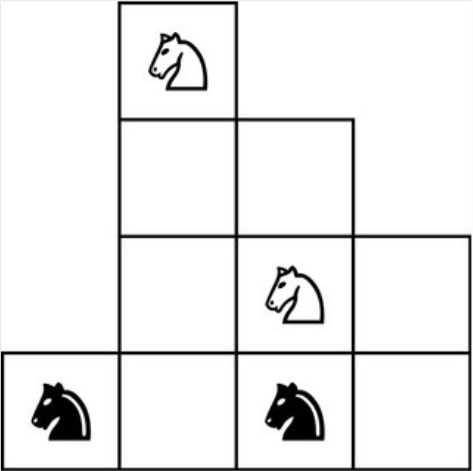 We're going to define a graph over the (irregular) chess board. First of all, let's number the squares to give them names. 2/n
We're going to define a graph over the (irregular) chess board. First of all, let's number the squares to give them names. 2/n 
 Ft stellar lineup of invited speakers including: Chelsea Finn (@chelseabfinn), Shafi Goldwasser, Zico Kolter (@zicokolter), Nicolas Papernot (@NicolasPapernot), & Aaron Roth (@Aaroth)
Ft stellar lineup of invited speakers including: Chelsea Finn (@chelseabfinn), Shafi Goldwasser, Zico Kolter (@zicokolter), Nicolas Papernot (@NicolasPapernot), & Aaron Roth (@Aaroth) 
 Outstanding Paper Award 2. On the Expressivity of Markov Reward, by @dabelcs, @wwdabney, @aharutyu, @Mark_Ho_, @mlittmancs, Doina Precup, and Satinder Singh.
Outstanding Paper Award 2. On the Expressivity of Markov Reward, by @dabelcs, @wwdabney, @aharutyu, @Mark_Ho_, @mlittmancs, Doina Precup, and Satinder Singh.
 We give the 1st algorithm for mean estimation which is simultaneously:
We give the 1st algorithm for mean estimation which is simultaneously: