Looking for AI work. DMs open. ML discord: https://t.co/2J63isabrY projects: https://t.co/6XsuoK4lu0

 That's more like it. Hello, 65B.
That's more like it. Hello, 65B.

 The goal is to statistically verify whether Caleb's luck is worse than 8%. There might be something else going on. For example, FF7 uses a separate RNG for enemy encounter rate, and you can manipulate it by walking a certain number of steps in certain rooms.
The goal is to statistically verify whether Caleb's luck is worse than 8%. There might be something else going on. For example, FF7 uses a separate RNG for enemy encounter rate, and you can manipulate it by walking a certain number of steps in certain rooms.

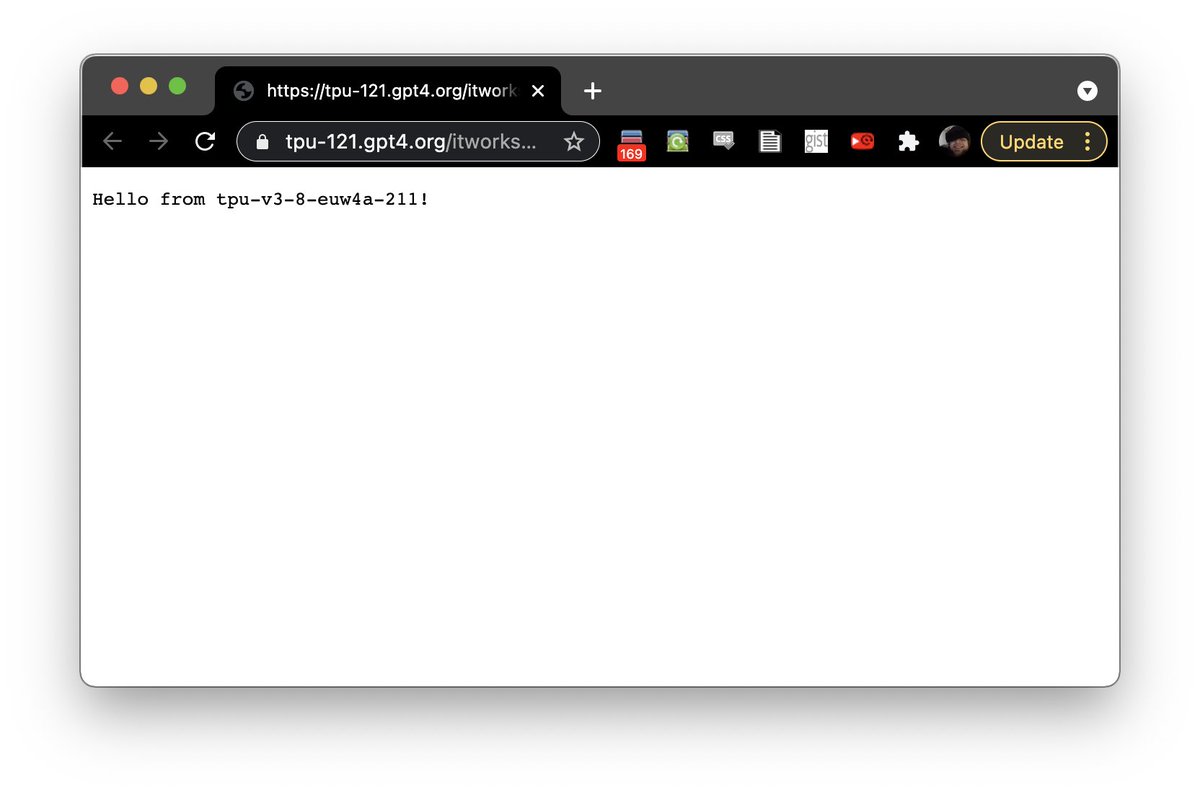 If you haven't heard about SSH'ing into TPU VMs, it's a new feature! @jekbradbury's team recently released it:
If you haven't heard about SSH'ing into TPU VMs, it's a new feature! @jekbradbury's team recently released it:
 I wrote up some details here: github.com/soskek/bookcor…
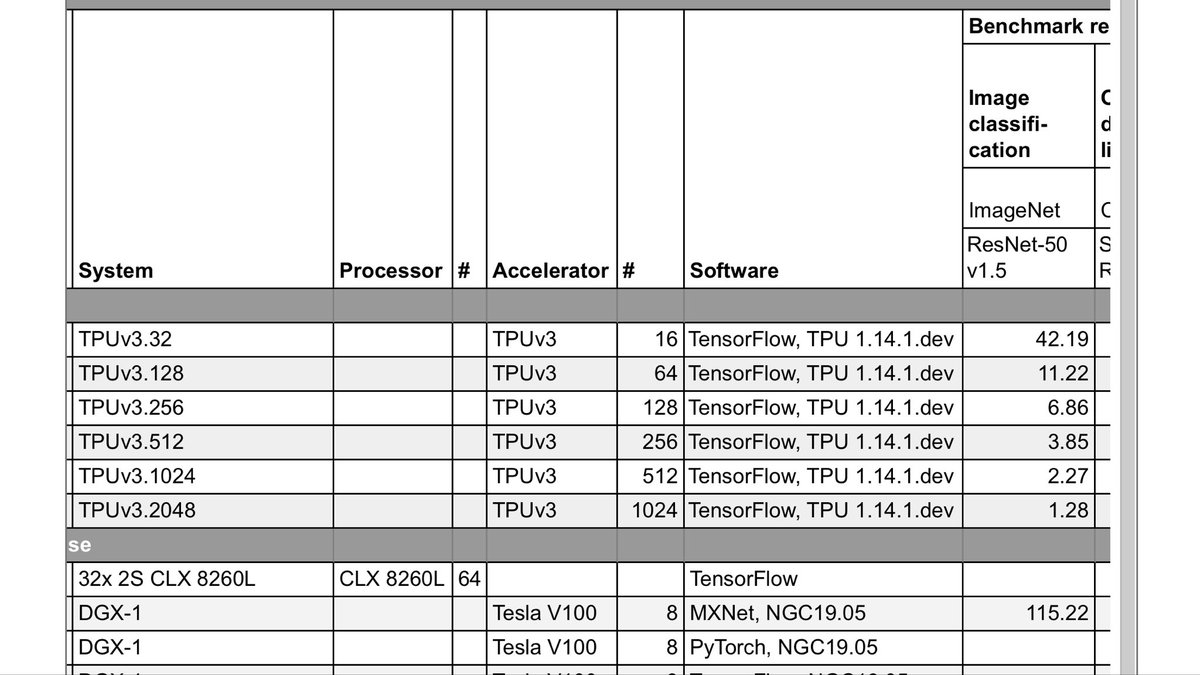
I wrote up some details here: github.com/soskek/bookcor…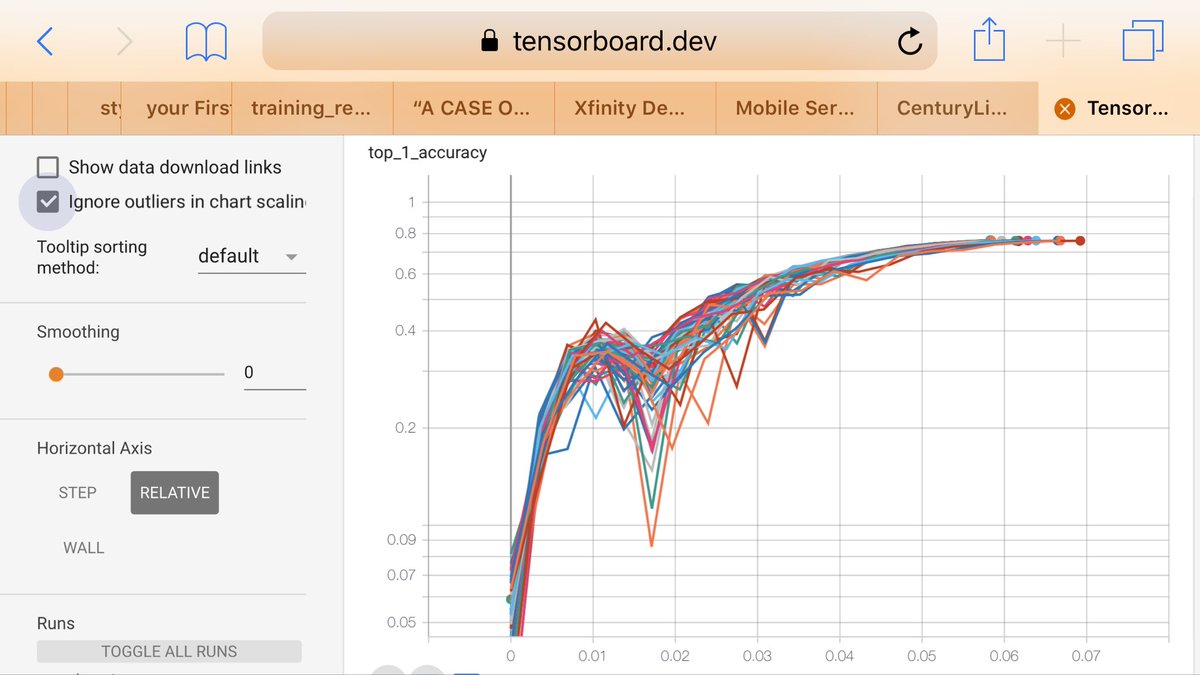 It uses the code from their official MLPerf imagenet benchmark. mlperf.org/training-resul…
It uses the code from their official MLPerf imagenet benchmark. mlperf.org/training-resul…