
ML ex Nvidia. Creator of @trainxgb. Data Scientist. Physicist. Catholic. Husband. Father. Stanford Alum. Memelord. e/xgb. AMDG.
3 subscribers
 I argue that we need to rethink education from the ground up with AI playing a central role in it. If understood properly, AI can be a major driving force enabling better, more accessible, and more impactful education and training.
I argue that we need to rethink education from the ground up with AI playing a central role in it. If understood properly, AI can be a major driving force enabling better, more accessible, and more impactful education and training. In recent years changes to the language have largely focused on the under-the-hood improvements, focusing on such things as stability, portability, performance, etc. Some of the top improvements:
In recent years changes to the language have largely focused on the under-the-hood improvements, focusing on such things as stability, portability, performance, etc. Some of the top improvements: David Epstein argues against the prevailing cultural narrative that specialization is the only path to success. Instead, he champions the idea of "range" — the benefits of having a broad set of experiences, skills, and knowledge. Epstein uses a variety of examples from sports, science, music, and business to illustrate how generalists often outperform specialists in complex and unpredictable environments. He suggests that learning broadly before (or even instead of) specializing can lead to greater creativity, adaptability, and success.
David Epstein argues against the prevailing cultural narrative that specialization is the only path to success. Instead, he champions the idea of "range" — the benefits of having a broad set of experiences, skills, and knowledge. Epstein uses a variety of examples from sports, science, music, and business to illustrate how generalists often outperform specialists in complex and unpredictable environments. He suggests that learning broadly before (or even instead of) specializing can lead to greater creativity, adaptability, and success. On paper, MI300X has many advantages compared to the H100/H200, but in practice AMD's hardware is effectively nerfed by their catastrophically weak software. TL;DR: out of the box you will not be able to use MI300X for ML/AI training.
On paper, MI300X has many advantages compared to the H100/H200, but in practice AMD's hardware is effectively nerfed by their catastrophically weak software. TL;DR: out of the box you will not be able to use MI300X for ML/AI training. Some key takeaways:
Some key takeaways: This software has been developed though close collaboration with many leading AI companies, such as @Meta, @anyscalecompute , @cohere , Deci AI, @Grammarly, @databricks and many others.
This software has been developed though close collaboration with many leading AI companies, such as @Meta, @anyscalecompute , @cohere , Deci AI, @Grammarly, @databricks and many others. A new paper tries to investigate the nature of these failures, and understand the limits of LLM-based reasoning. It seems that the failures primarily arise from the tasks with low in-domain knowledge and high compositional complexity.
A new paper tries to investigate the nature of these failures, and understand the limits of LLM-based reasoning. It seems that the failures primarily arise from the tasks with low in-domain knowledge and high compositional complexity.  It is a very intuitive and easy to learn programming language. The merger of these two tools will open new opportunities and use cases.
It is a very intuitive and easy to learn programming language. The merger of these two tools will open new opportunities and use cases. They require an enormous amount of high-quality data to train and even more unfathomably large amount of computational power.
They require an enormous amount of high-quality data to train and even more unfathomably large amount of computational power.
 A few points:
A few points: Bing search engine and Edge web browser. In particular, this seems to be the first time that we'll see anywhere a public use of OpenAI's next generation LLM, GPT4. Most of the new features are still relatively limited, and you'll need to join the waitlist for the full access. 2/4
Bing search engine and Edge web browser. In particular, this seems to be the first time that we'll see anywhere a public use of OpenAI's next generation LLM, GPT4. Most of the new features are still relatively limited, and you'll need to join the waitlist for the full access. 2/4
 LaMDA - Language Model for Dialogue Applications - has been around for at least a year, but due to variety of considerations it has never been accessible to to the public.
LaMDA - Language Model for Dialogue Applications - has been around for at least a year, but due to variety of considerations it has never been accessible to to the public. their use across the board for all ML problems and with all datasets is problematic, to say the least. Oftentimes better and more robust results can be obtained with simpler, easier to train and deploy, classical ML algorithms.
their use across the board for all ML problems and with all datasets is problematic, to say the least. Oftentimes better and more robust results can be obtained with simpler, easier to train and deploy, classical ML algorithms.  Fortunately not all organizations and managers are this cutthroat, but this kind of mindset is pervasive, especially at startups. There is a widespread attitude that *it’s someone else’s responsibility to do the educating*: yours, your previous job’s, your college’s etc.
Fortunately not all organizations and managers are this cutthroat, but this kind of mindset is pervasive, especially at startups. There is a widespread attitude that *it’s someone else’s responsibility to do the educating*: yours, your previous job’s, your college’s etc. The original announcement from DeepMind came out in February, which in the fast-paced world of AI is already ancient history.
The original announcement from DeepMind came out in February, which in the fast-paced world of AI is already ancient history.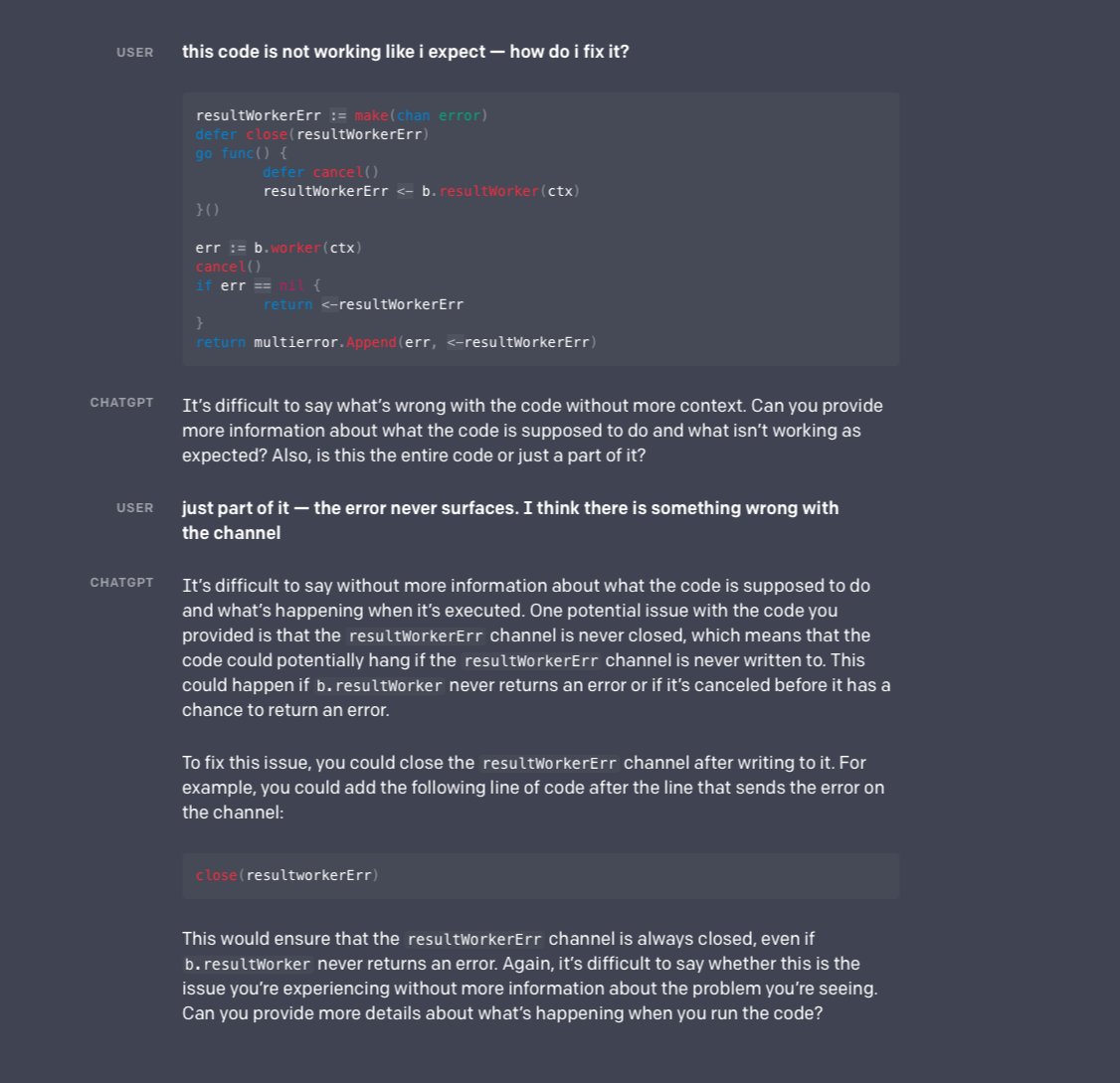 It is also able to answer the follow up question, backtrack on wrong assumptions, and provide other detailed resources, including code fragments.
It is also able to answer the follow up question, backtrack on wrong assumptions, and provide other detailed resources, including code fragments.  The three main principles behind PyTorch
The three main principles behind PyTorch  They also provide an unparalleled level of interpretability compared to all other non-linear algorithms. However, they are very hard to optimize on Von Neumann architecture machines due to their non-uniform memory access patterns.
They also provide an unparalleled level of interpretability compared to all other non-linear algorithms. However, they are very hard to optimize on Von Neumann architecture machines due to their non-uniform memory access patterns. I decided to check how does XGBoost *really* perform on the datasets used in the paper, and the results were not pretty.
I decided to check how does XGBoost *really* perform on the datasets used in the paper, and the results were not pretty.  Trained using only 2D images, GET3D generates 3D shapes with high-fidelity textures and complex geometric details.
Trained using only 2D images, GET3D generates 3D shapes with high-fidelity textures and complex geometric details.