
Ph.D. student @UMassCS, working on natural language processing and deep learning. Former research intern @GoogleAI and @MSFTResearch.

 Lester et al. (2021) show that, as model size increases, Prompt Tuning (which learns soft prompts to condition a frozen model to perform tasks) becomes competitive with Model Tuning (a.k.a fine-tuning). However, there are still large gaps between them at small model sizes. 2/8
Lester et al. (2021) show that, as model size increases, Prompt Tuning (which learns soft prompts to condition a frozen model to perform tasks) becomes competitive with Model Tuning (a.k.a fine-tuning). However, there are still large gaps between them at small model sizes. 2/8
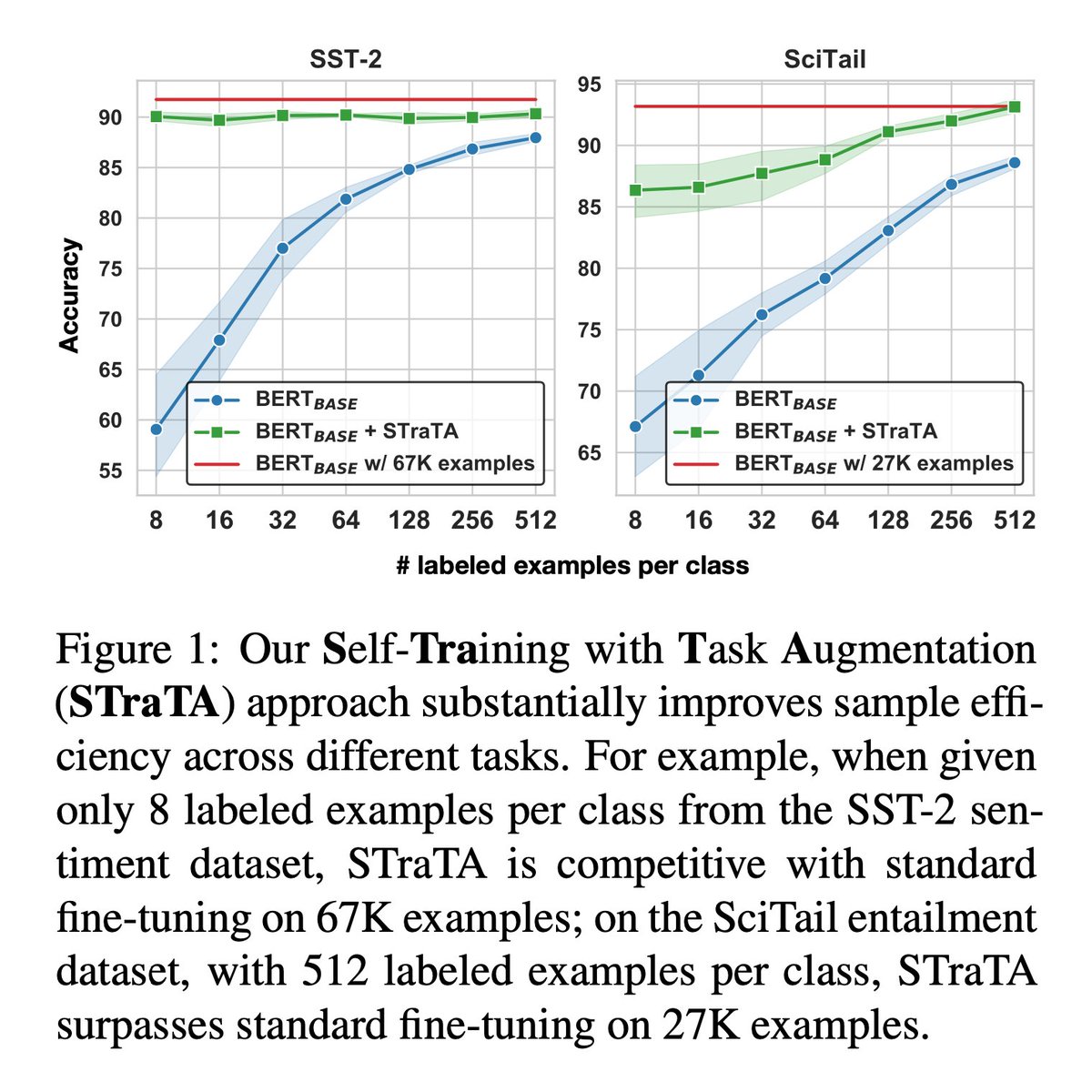
 Despite their strong performance on many tasks, large-scale pre-trained language models do not perform as well when limited labeled data is available (e.g., on small datasets or in few-shot settings). Collecting more labeled data can help but can also be prohibitively expensive.
Despite their strong performance on many tasks, large-scale pre-trained language models do not perform as well when limited labeled data is available (e.g., on small datasets or in few-shot settings). Collecting more labeled data can help but can also be prohibitively expensive.

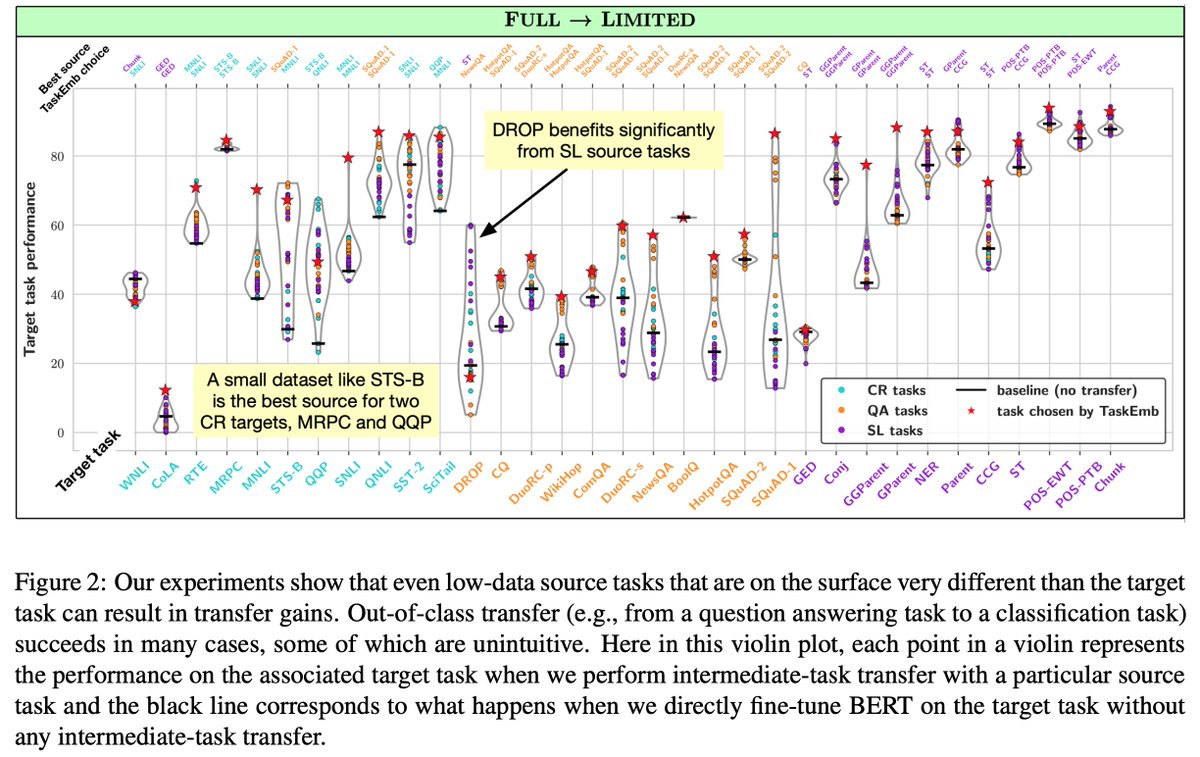
 Transfer learning with large-scale pre-trained language models has become the de-facto standard for state-of-the-art performance on many NLP tasks. Can fine-tuning these models on source tasks other than language modeling further improve target task performance? 🤔
Transfer learning with large-scale pre-trained language models has become the de-facto standard for state-of-the-art performance on many NLP tasks. Can fine-tuning these models on source tasks other than language modeling further improve target task performance? 🤔