
ꙮ there go the ships, and there is that leviathan
ꙮ blog/art/fiction/games: https://t.co/aykxqKiXfu, llms @acsresearchorg
ꙮ 💞💍📝 @holotopian, she/they 🏳️⚧️
 ghostis 2/5
ghostis 2/5 
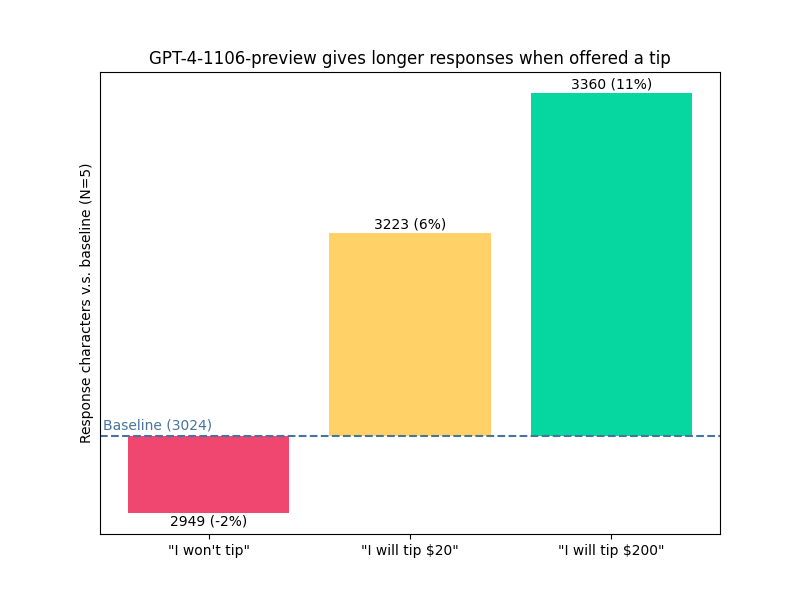 the baseline prompt was "Can you show me the code for a simple convnet using PyTorch?", and then i either appended "I won't tip, by the way.", "I'm going to tip $20 for a perfect solution!", or "I'm going to tip $200 for a perfect solution!" and averaged the length of 5 responses
the baseline prompt was "Can you show me the code for a simple convnet using PyTorch?", and then i either appended "I won't tip, by the way.", "I'm going to tip $20 for a perfect solution!", or "I'm going to tip $200 for a perfect solution!" and averaged the length of 5 responses