
Trying to read Claude’s mind. Interpretability at @AnthropicAI
Prev: Optimizer @MIT, Byte-counter @Google
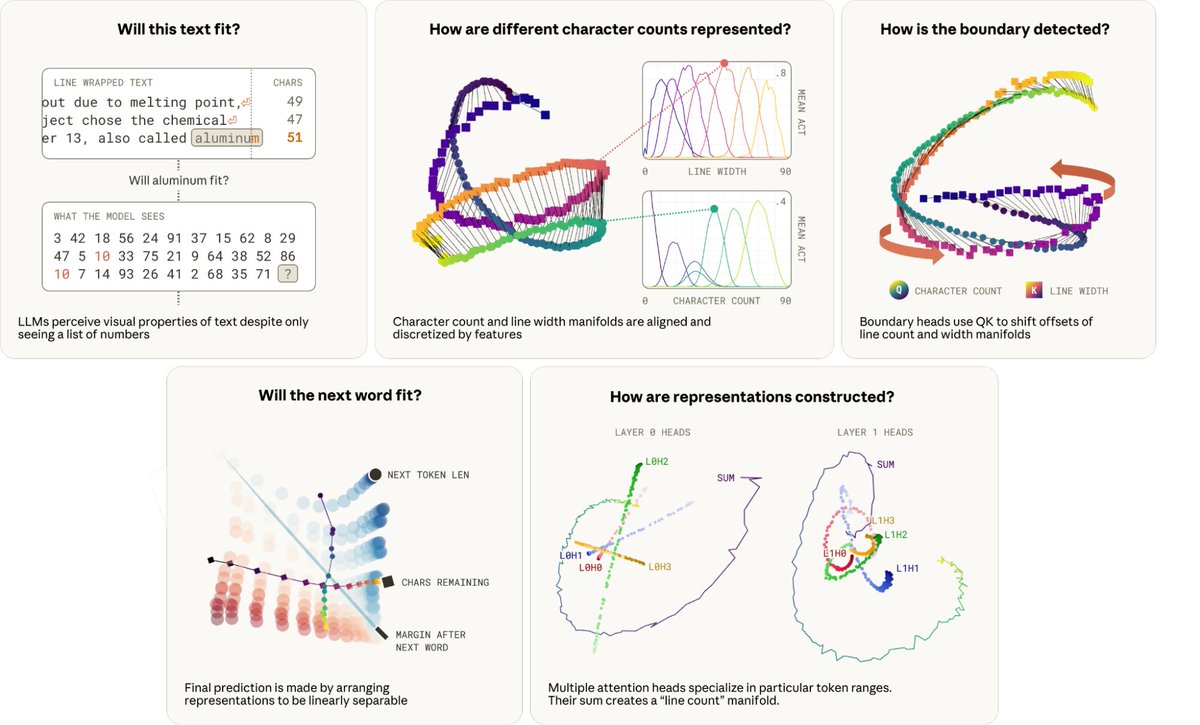 The task is simply when to break a line in fixed width text. This requires the model to in-context learn the line width constraint, state track the characters in the current line, compute the characters remaining, and determine if the next word fits!
The task is simply when to break a line in fixed width text. This requires the model to in-context learn the line width constraint, state track the characters in the current line, compute the characters remaining, and determine if the next word fits! 
 One large family of neurons we find are “context” neurons, which activate only for tokens in a particular context (French, Python code, US patent documents, etc). When deleting these neurons the loss increases in the relevant context while leaving other contexts unaffected!
One large family of neurons we find are “context” neurons, which activate only for tokens in a particular context (French, Python code, US patent documents, etc). When deleting these neurons the loss increases in the relevant context while leaving other contexts unaffected! 