Superintelligence @Meta. Training & evaluating foundation models. Previously @LTIatCMU @osunlp. Opinions are my own.
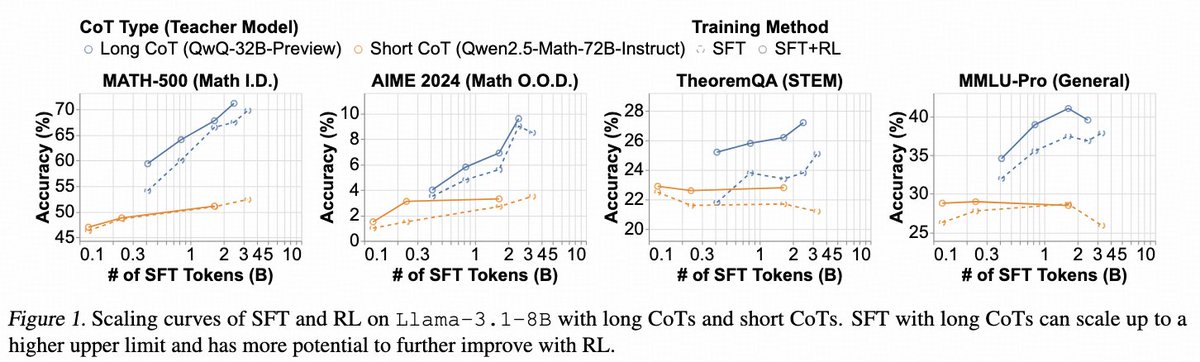
 Takeaway 1: RL helps extrapolation only when there's headroom left by pre-training and with the right RL data at the edge of the model's competence.
Takeaway 1: RL helps extrapolation only when there's headroom left by pre-training and with the right RL data at the edge of the model's competence. 
 We further conducted a controlled study using only math queries during training. Surprisingly, even with this single math domain, RL training still led to strong cross-domain generalization while SFT does not.
We further conducted a controlled study using only math queries during training. Surprisingly, even with this single math domain, RL training still led to strong cross-domain generalization while SFT does not.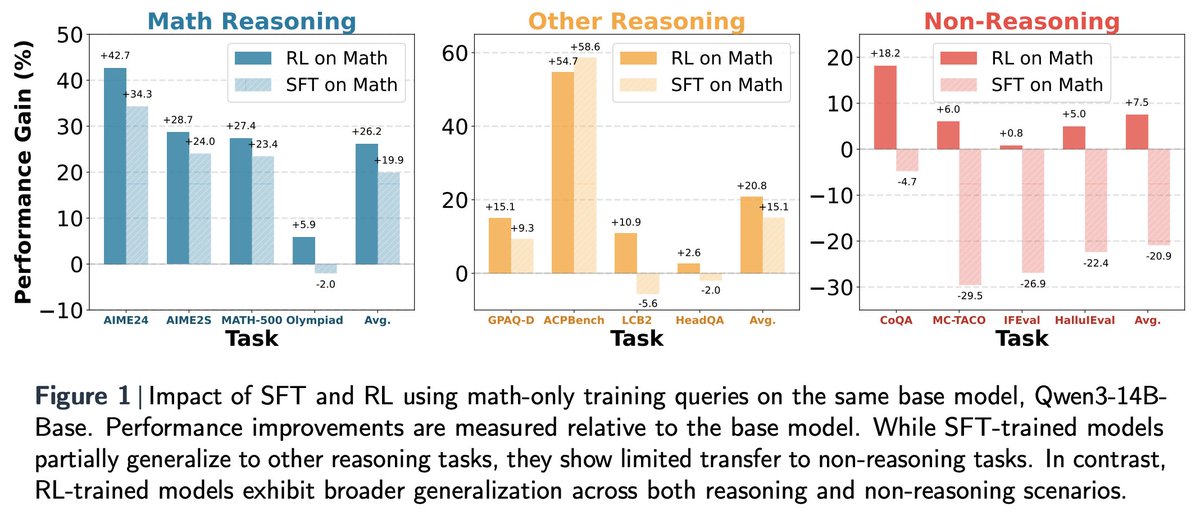
 Takeaway 1:
Takeaway 1: