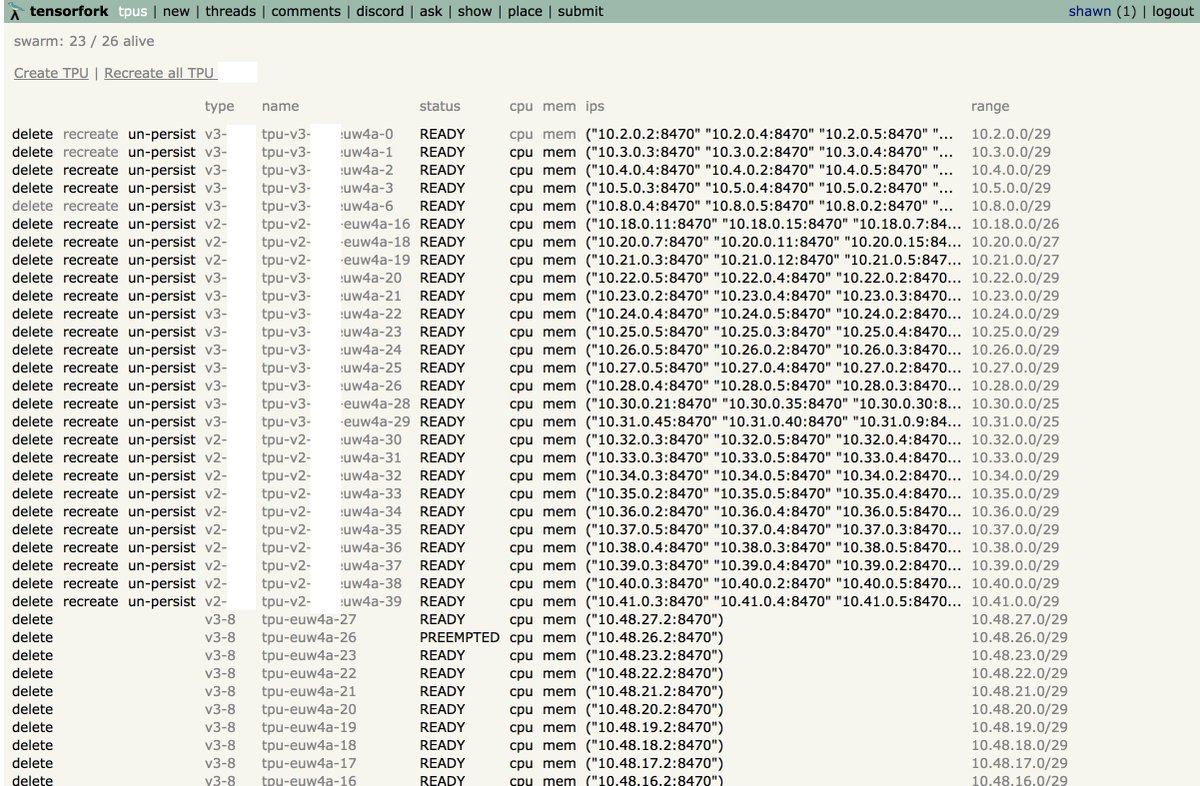
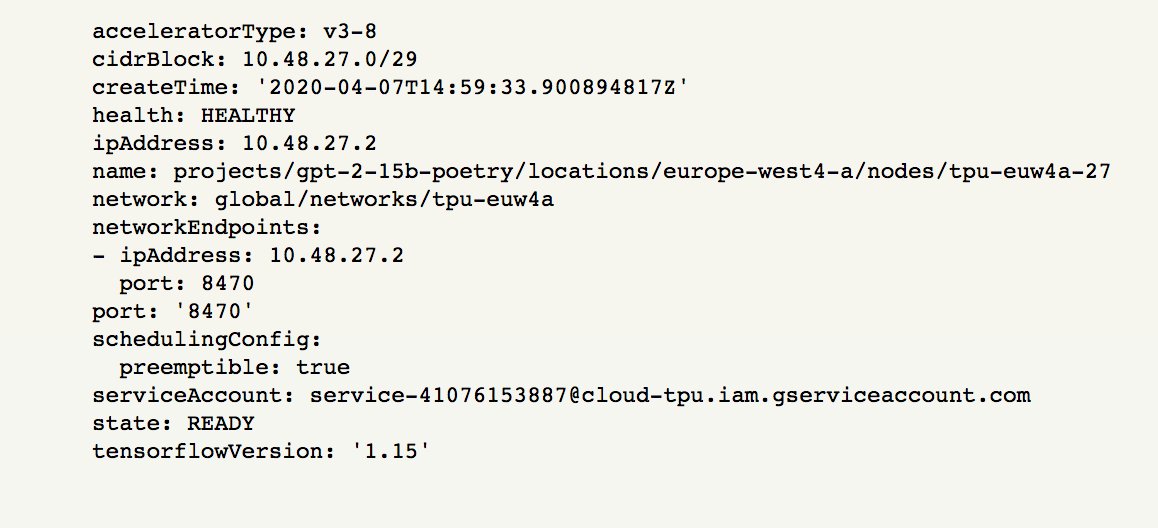
Success: I trained ResNet-50 on imagenet to 75.9% top-1 accuracy in 3.51 minutes using a 512-core TPUv3.
(480,000 images per second. 224x224 res JPG.)
Before you think highly of me, all I did was run Google’s code. It was hard though.
Logs: tensorboard.dev/experiment/jsD…
(480,000 images per second. 224x224 res JPG.)
Before you think highly of me, all I did was run Google’s code. It was hard though.
Logs: tensorboard.dev/experiment/jsD…
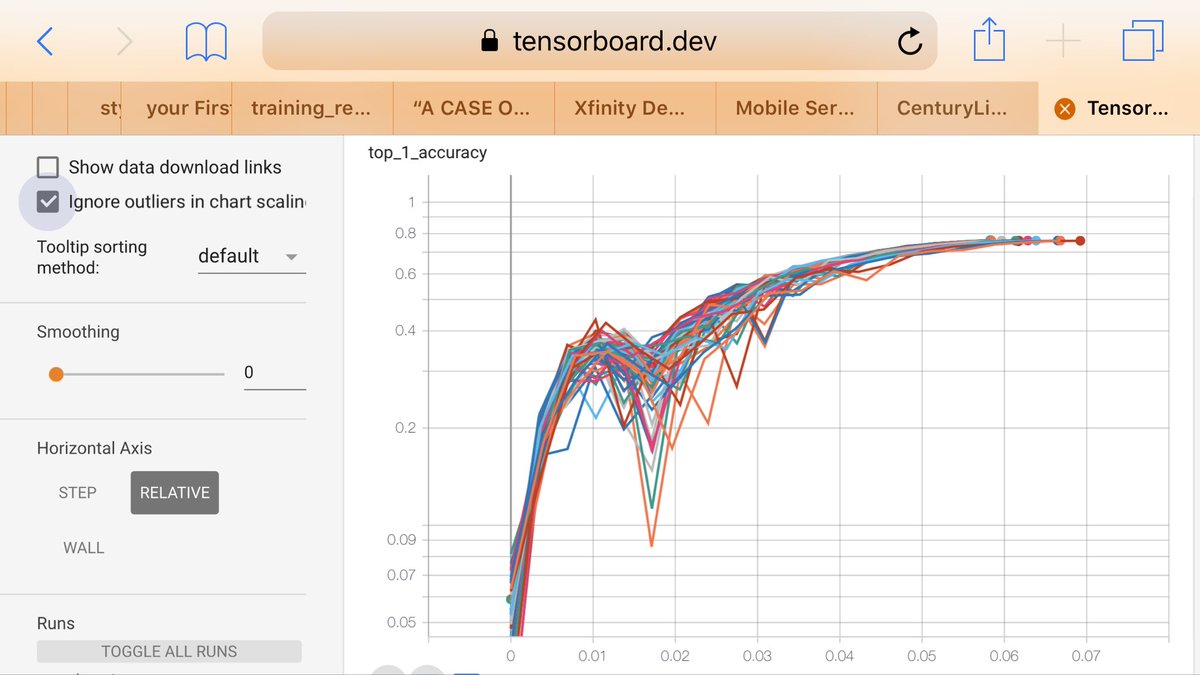
It uses the code from their official MLPerf imagenet benchmark. mlperf.org/training-resul…
(3.51 minutes for v3-512 is slightly faster than their posted results of 3.85min, too!)
(3.51 minutes for v3-512 is slightly faster than their posted results of 3.85min, too!)
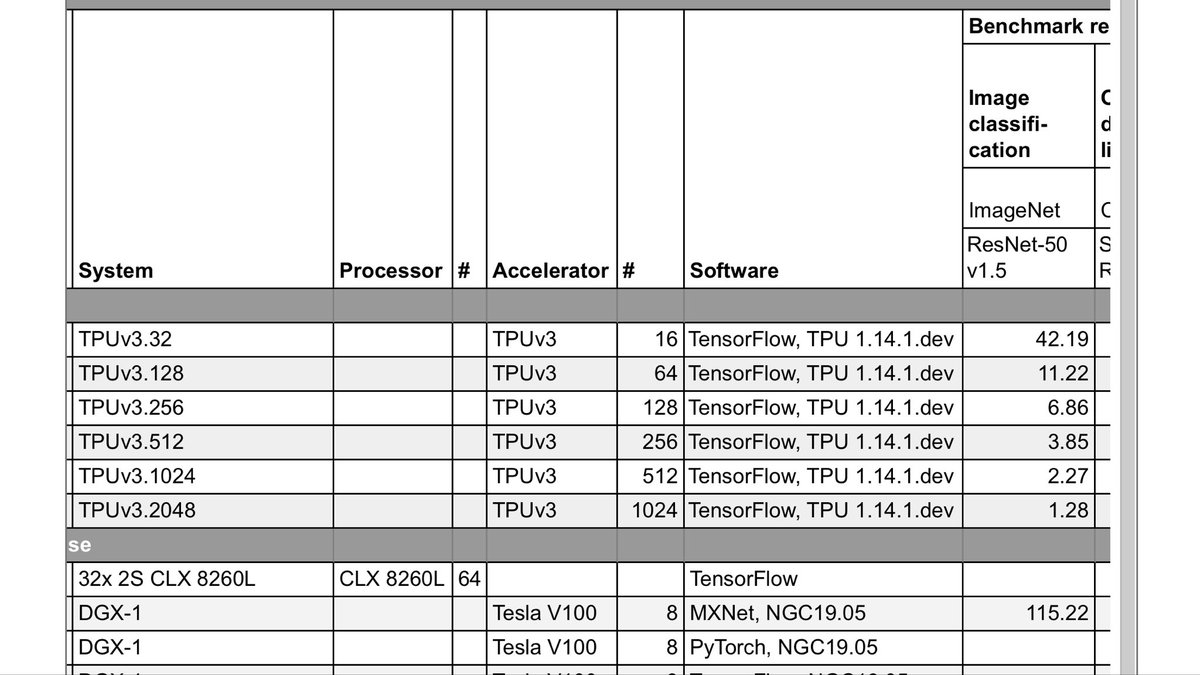
This raises a question: *why* is the official benchmark so blazingly fast? That’s about 930 examples/sec per core. When I tried to write my own code, I could only get 250ex/sec per core. Are they cheating? *gasp*
Spoiler: nope! It’s legit. It’s faster because:
Spoiler: nope! It’s legit. It’s faster because:
1. The TPU system software is tensorflow 1.14.1dev20190915 (or close to that). This makes a huge difference. bfloat16 performance seems to vary dramatically depending on the TF version. Because..
2. The TF library is also 1.14 on the VM. I suspect internals are different.
2. The TF library is also 1.14 on the VM. I suspect internals are different.
3. They don’t use the Estimator API. They manually construct an equivalent to what the Estimator does. Why? Because it cuts out all the cruft. No computation is wasted.
If you want to know how to do “TPU without estimator,” this is *the* resource: github.com/mlperf/trainin…
If you want to know how to do “TPU without estimator,” this is *the* resource: github.com/mlperf/trainin…
4. Imagenet is split into 1,024 TFRecord files. Why does this matter?
A TPU pod is a collection of TPUv3-8’s. When you see “TPUv3-512”, divide 512 cores by 8 = there are 64 individual TPUs.
Each TPU can simultaneously read from a different shard of the 1024-file dataset.
A TPU pod is a collection of TPUv3-8’s. When you see “TPUv3-512”, divide 512 cores by 8 = there are 64 individual TPUs.
Each TPU can simultaneously read from a different shard of the 1024-file dataset.
5. Image transformations happen on the TPU’s CPU.
Picture a TPU. You probably think of “8 cores with 16GB each.” No, don’t think like that.
Think of a TPU like a desktop computer with a CPU, 300GB RAM, and 8 video cards (16GB each).
You can run code on the TPU’s CPU!
Picture a TPU. You probably think of “8 cores with 16GB each.” No, don’t think like that.
Think of a TPU like a desktop computer with a CPU, 300GB RAM, and 8 video cards (16GB each).
You can run code on the TPU’s CPU!
They exploit this by decoding the jpeg on the TPU’s CPU, random cropping it, then sending it to an individual TPU core for processing.
Input processing happens in parallel with resnet training. The TPU’s CPU prepares the next inputs while each TPU core trains on the prev batch.
Input processing happens in parallel with resnet training. The TPU’s CPU prepares the next inputs while each TPU core trains on the prev batch.
6. LARS optimizer: arxiv.org/pdf/1708.03888…
For TPUv3-256 and above, the batch size is 32,768. Such huge batch sizes cause problems, because you have to raise the learning rate as you increase the batch size. Normally this causes divergence.
LARS has a learning rate per layer.
For TPUv3-256 and above, the batch size is 32,768. Such huge batch sizes cause problems, because you have to raise the learning rate as you increase the batch size. Normally this causes divergence.
LARS has a learning rate per layer.
7. Beautiful code.
I was surprised just how pretty the benchmark code was. And I think it’s why it’s fast.
Wild animals are beautiful because they have hard lives. This code is beautiful because it has zero overhead. Nothing is wasted.
github.com/mlperf/trainin…
I was surprised just how pretty the benchmark code was. And I think it’s why it’s fast.
Wild animals are beautiful because they have hard lives. This code is beautiful because it has zero overhead. Nothing is wasted.
github.com/mlperf/trainin…