
[#THREAD] Le camembert. Certains l’aiment coulant. D’autres plâtreux. En data visualisation, on l’aime coloré. Mais le camembert est en fait périmé depuis 1984, et la publication des résultats de l’expérience scientifique de William Cleveland et Robert McGill (1/29) 

Avant de raconter l’expérience de Cleveland et McGill, un peu de contexte historique : en 1984, faire des expériences scientifiques sur les graphiques c’est quelque chose de plutôt nouveau (2/29)
Dans les années 1960-1970, on ne parlait pas encore de data visualisation mais de « sémiologie graphique ». L’analyse des graphiques était surtout pratiquée par les adeptes de la sémiotique, l’étude des signes et de la signalisation (3/29)
Ce qu’il faut retenir de la sémiotique, c’est qu’elle analyse les graphiques comme des constructions culturelles. Partant de là, toute classification des graphiques du plus clair au moins clair est forcément arbitraire. Il n’y a pas de place pour la science (4/29)
Mais les choses changent avec le développement de la psychologie expérimentale et notamment de l’une de ses branches : la psychophysique qui étudie les relations quantitatives entre les stimulus physiques (comme la vue d’un graphique) et la perception qu’on en a (5/29)
En partant des avancées de la psychophysique, Cleveland et McGill veulent évaluer l’efficacité des graphiques les plus fréquemment utilisés pour représenter des données quantitatives : diagrammes à barres, diagrammes à points, camembert, cartes, etc (6/29)
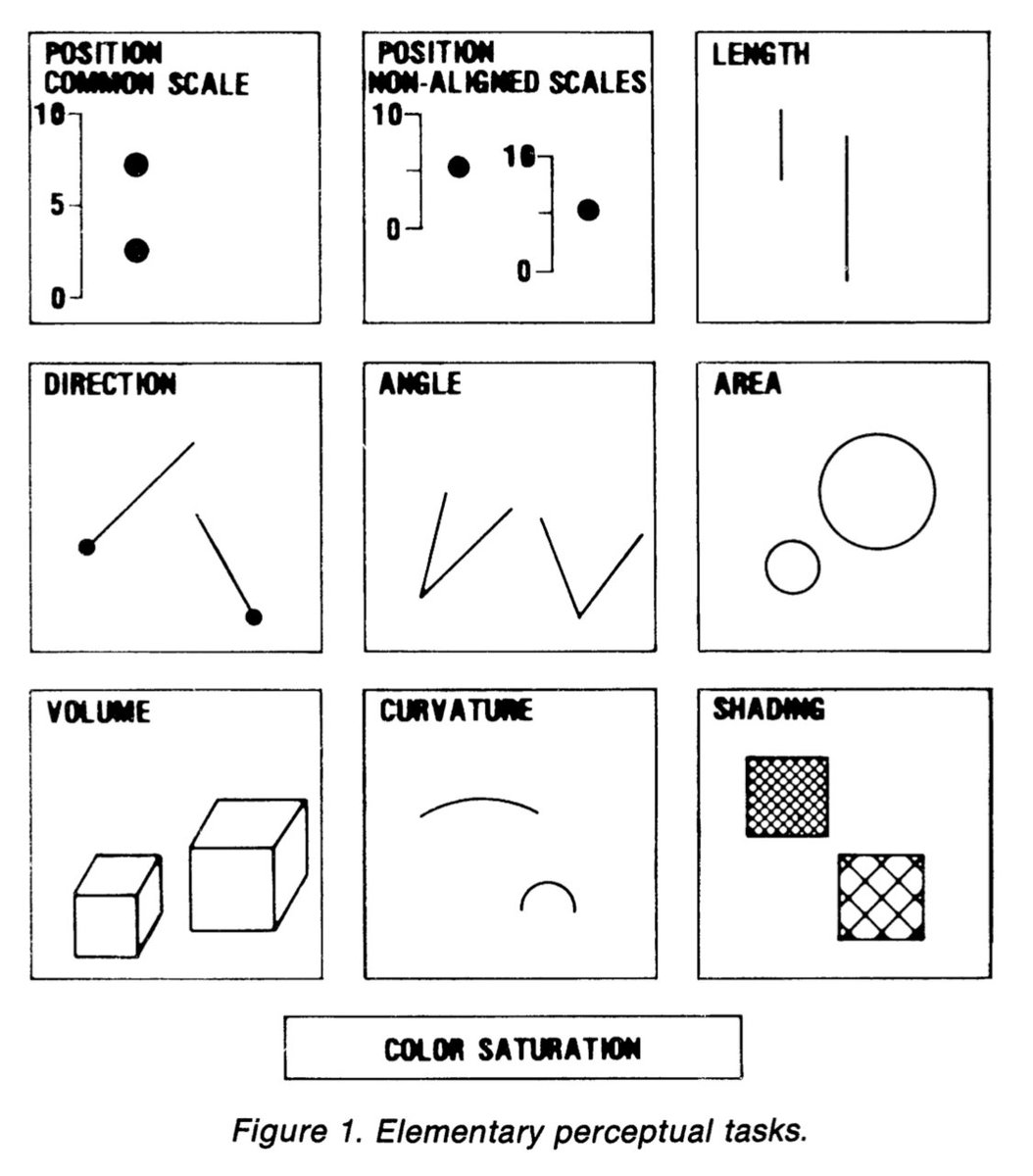
Pour commencer, les deux chercheurs isolent ce qu’ils appellent les « tâches perceptuelles élémentaires ». Il s’agit en fait des éléments visuels, que l’on utilise, souvent sans le savoir, pour extraire l’information quantitative représentée par les graphiques (7/29)
Ils en identifient 10 :
- la position sur une échelle commune
- les positions sur des échelles différentes
- la longueur
- la direction
- les angles
- la surface
- le volume
- les courbes
- les nuances de gris
- l’intensité des couleurs
(8/29)
- la position sur une échelle commune
- les positions sur des échelles différentes
- la longueur
- la direction
- les angles
- la surface
- le volume
- les courbes
- les nuances de gris
- l’intensité des couleurs
(8/29)
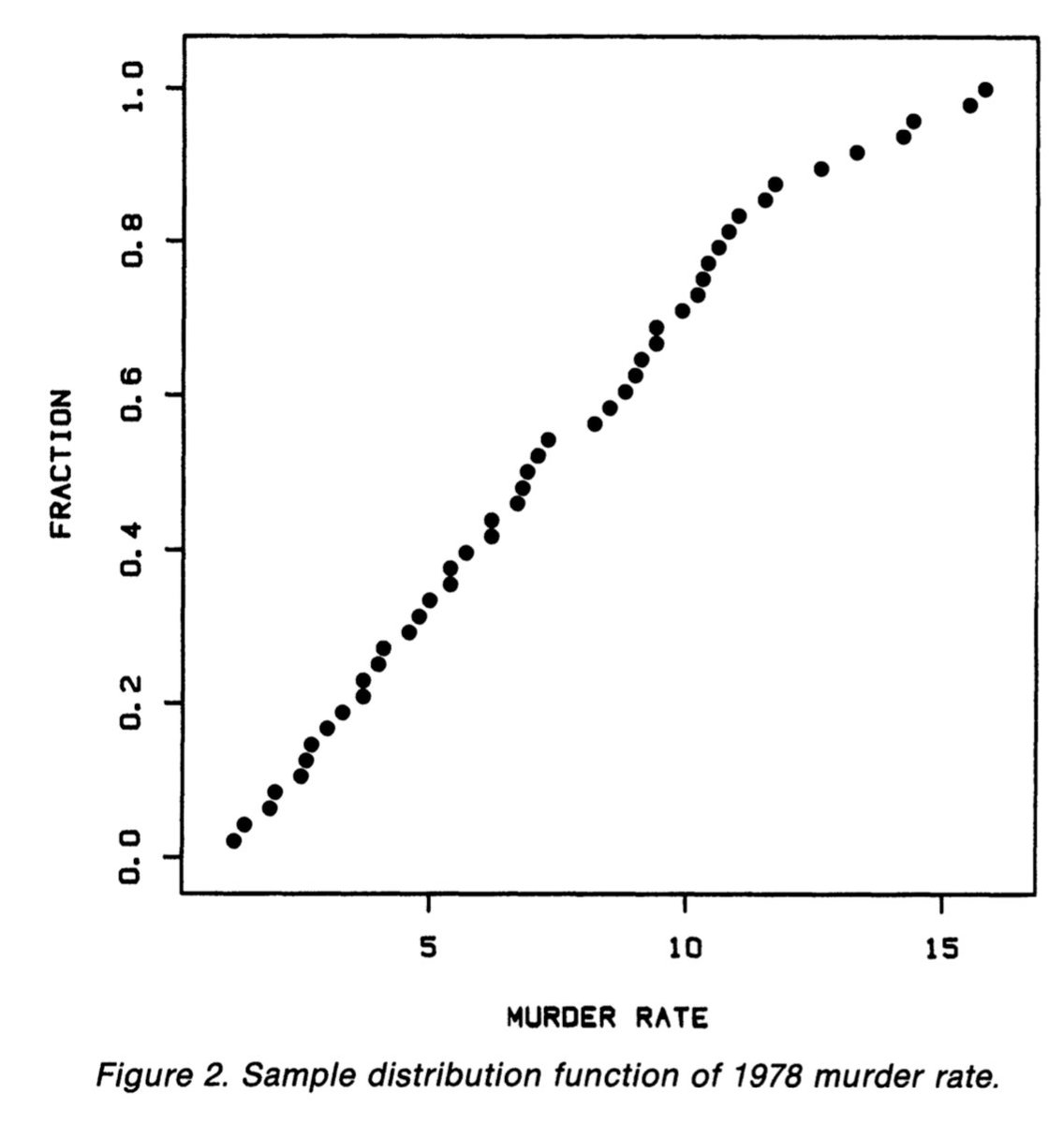
La position sur une échelle commune c’est le repère que l’on utilise sur le diagramme à points ci-dessous qui représente les meurtres pour 100 000 habitants / année dans les États américains. Nos yeux comparent la position de chacun des points par rapports aux axes x et y (9/29)
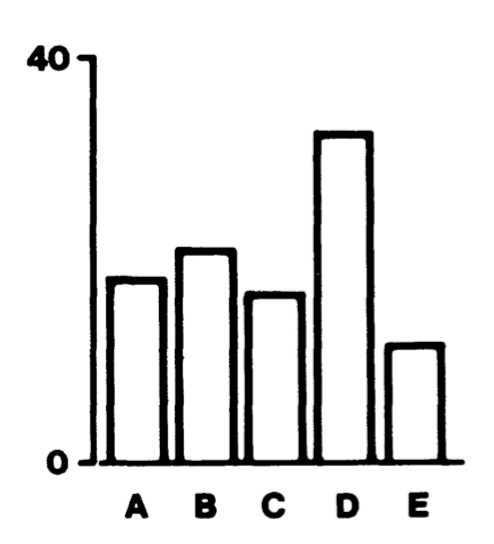
Sur un diagramme à barres on utilise la position du sommet de chaque barre par rapport à l’axe y ainsi que leur longueur pour comparer les valeurs qu’ils représentent (10/29)
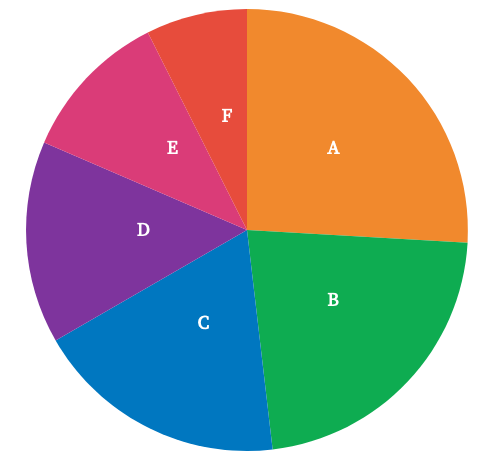
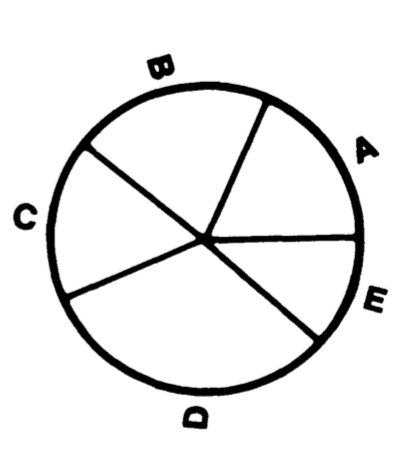
Lorsqu’on regarde un camembert, on identifie les valeurs grâce aux angles que forment les parts, ainsi que grâce à leurs surfaces et à la longueur des bords (11/29)
Dans un diagramme à barres empilées, la position est utilisée pour comparer les deux sommets de chaque empilement ainsi que pour comparer la hauteur des blocs à la base. Pour comparer les autres blocs, on utilise leur longueur (12/29)

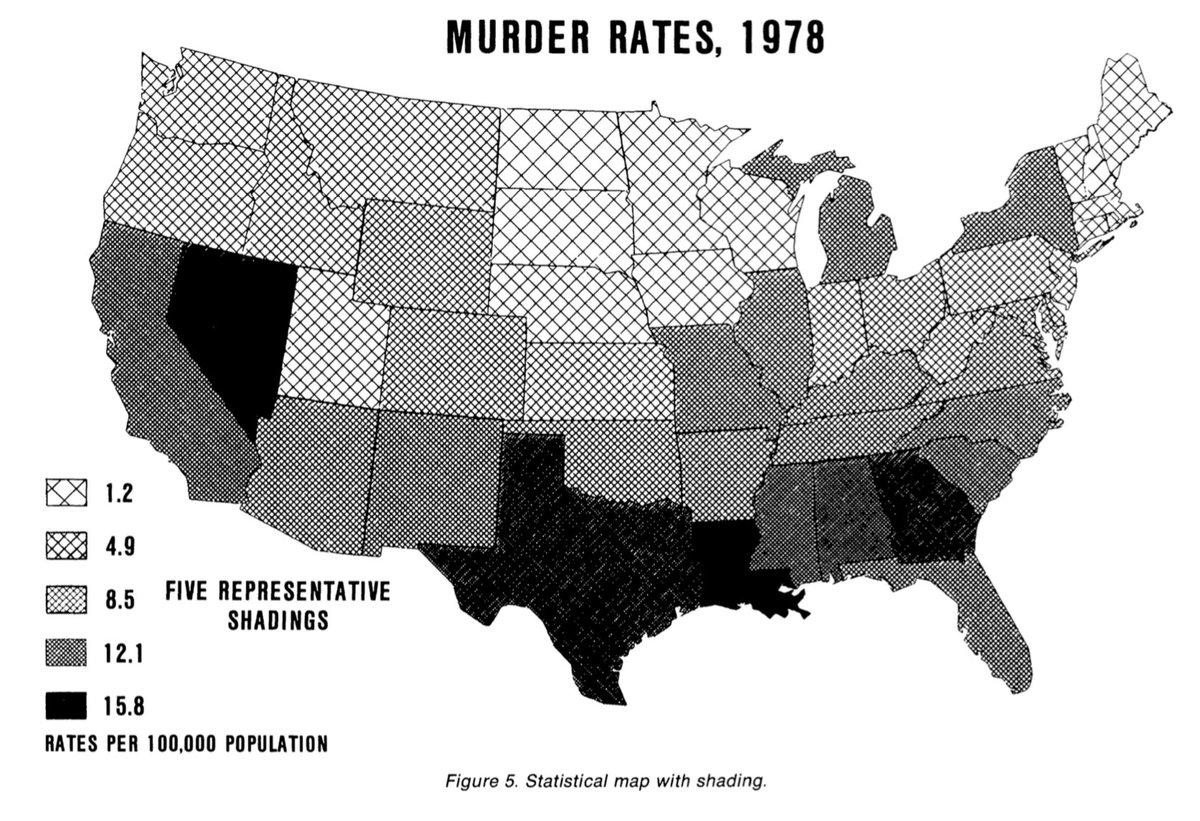
Sur la carte à nuances de gris ci-dessous, les valeurs de chaque État américain sont comparées grâce à la perception de l’intensité des gris ainsi que grâce à la comparaison des surfaces des carrés quadrillés (13/29)
Le graphique en aires, inventé par William Playfair, permet de suivre l’évolution dans le temps de la différence entre deux variables. On se repère sur ce graphique grâce à la position par rapport aux axes x et y et grâce à la longueur de l’espace qui sépare les 2 lignes (14/29)

Cleveland et McGill veulent déterminer quelles sont les « tâches perceptuelles » qui permettent de percevoir avec la plus grande précision les données quantitatives représentées à l’aide de graphiques (15/29)
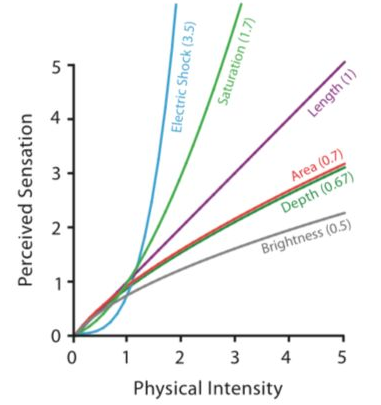
Ces « tâches » ont déjà été évaluées grâce aux travaux du psychologue américain Stanley Smith Stevens qui a établi le postulat que la relation entre l’intensité physique (I) et l’intensité perçue (S) d’un signal suit toujours la même loi de puissance : S = I^N (16/29)
Selon cette loi de puissance, plus notre perception est proche de la réalité, plus la valeur de N doit être proche de 1. Comme le montre le graphique ci-dessous, d’après la loi de Stevens, ce serait la longueur qui offrirait la plus grande précision (17/29)
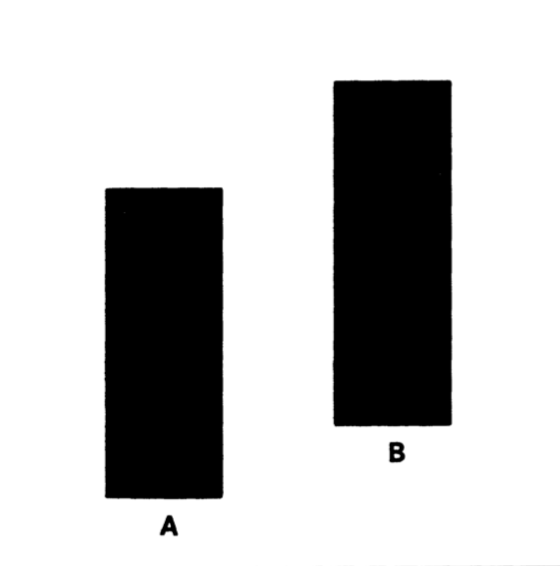
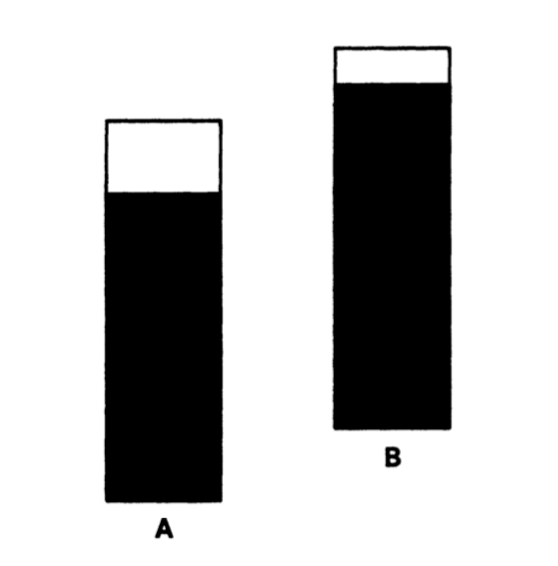
Mais pour Cleveland et McGill, la « tâche perceptuelle élémentaire » ultime ce n’est pas la longueur mais la position. Pour étayer leur hypothèse, ils prennent 2 rectangles. Différencier le plus long du moins long ne va pas de soi (18/29)
Ils reprennent leurs rectangles et les placent dans des cadres de taille identique. Il apparaît alors que le rectangle A est moins long que le B. Sauf que cette fois-ci nous n’utilisons plus la longueur mais la position du sommet de chaque rectangle pour nous repérer (19/29)
Cleveland et McGill en déduisent un classement des « tâches » des plus aux moins efficaces :
1. Position sur une échelle commune
2. Positions sur plusieurs échelles
3. Longueur, direction, angle
4. Surface
5. Volume, courbes
6. Nuances de gris, intensité des couleurs
(20/29)
1. Position sur une échelle commune
2. Positions sur plusieurs échelles
3. Longueur, direction, angle
4. Surface
5. Volume, courbes
6. Nuances de gris, intensité des couleurs
(20/29)
Puis ils vérifient ce classement en menant deux expériences sur deux groupes de 55 et 54 personnes : la première porte sur les différences de perception de la longueur et de la position, la deuxième compare la position et les angles (21/29)
Dans la première expérience, les sujets doivent comparer deux rectangles marqués par des points dans cinq graphiques différentes. Pour chaque graph, il leur est demandé quel rectangle est le plus petit et de donner une estimation de la différence de taille en pourcentage (22/29)

La deuxième expérience compare un camembert et un diagramme à barres. Il est indiqué aux sujets la barre et la part qui représentent la valeur la plus élevée dans chaque graph, puis il leur est demandé d’estimer en pourcentages les autres barres et les autres parts (23/29)

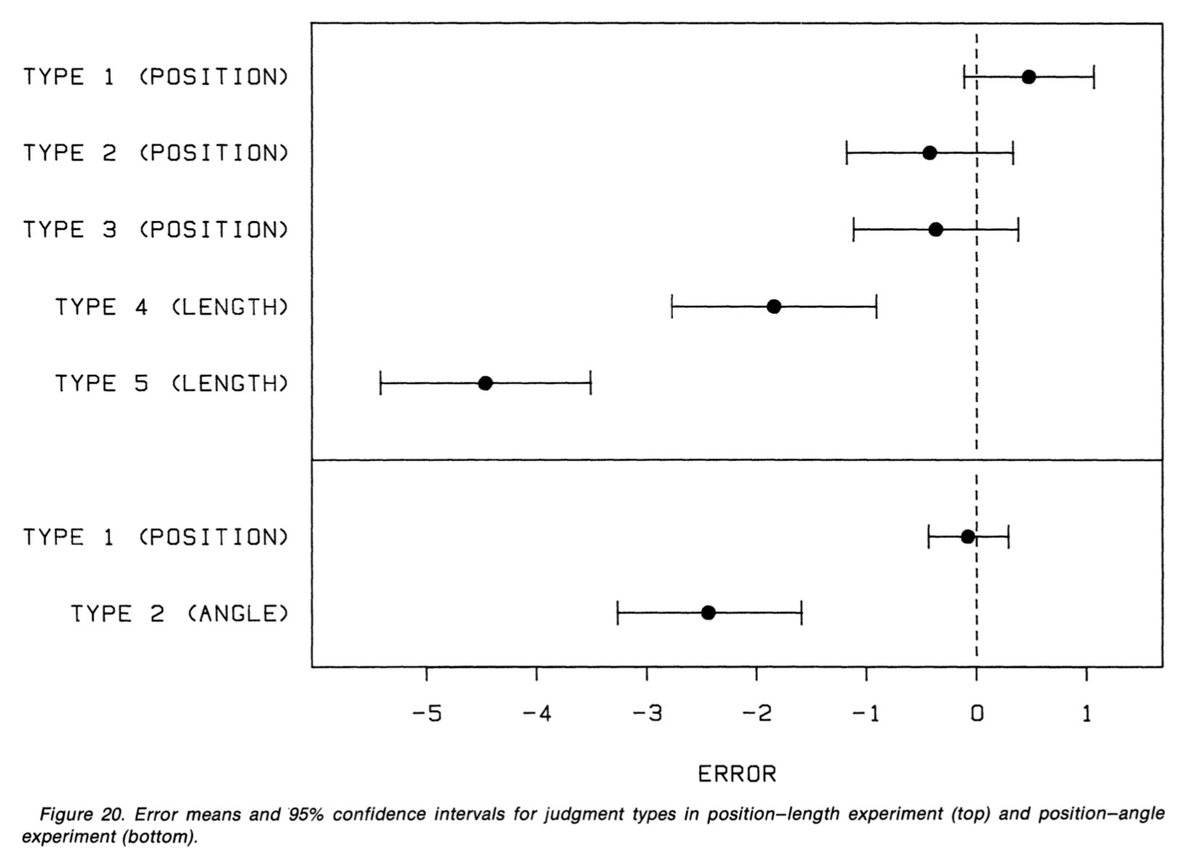
Cleveland et McGill projettent les résultats de leur expérience sur le graphique ci-dessous. Il apparaît que la perception de la position donne un ratio d’erreur beaucoup plus faible que la longueur et les angles (24/29)
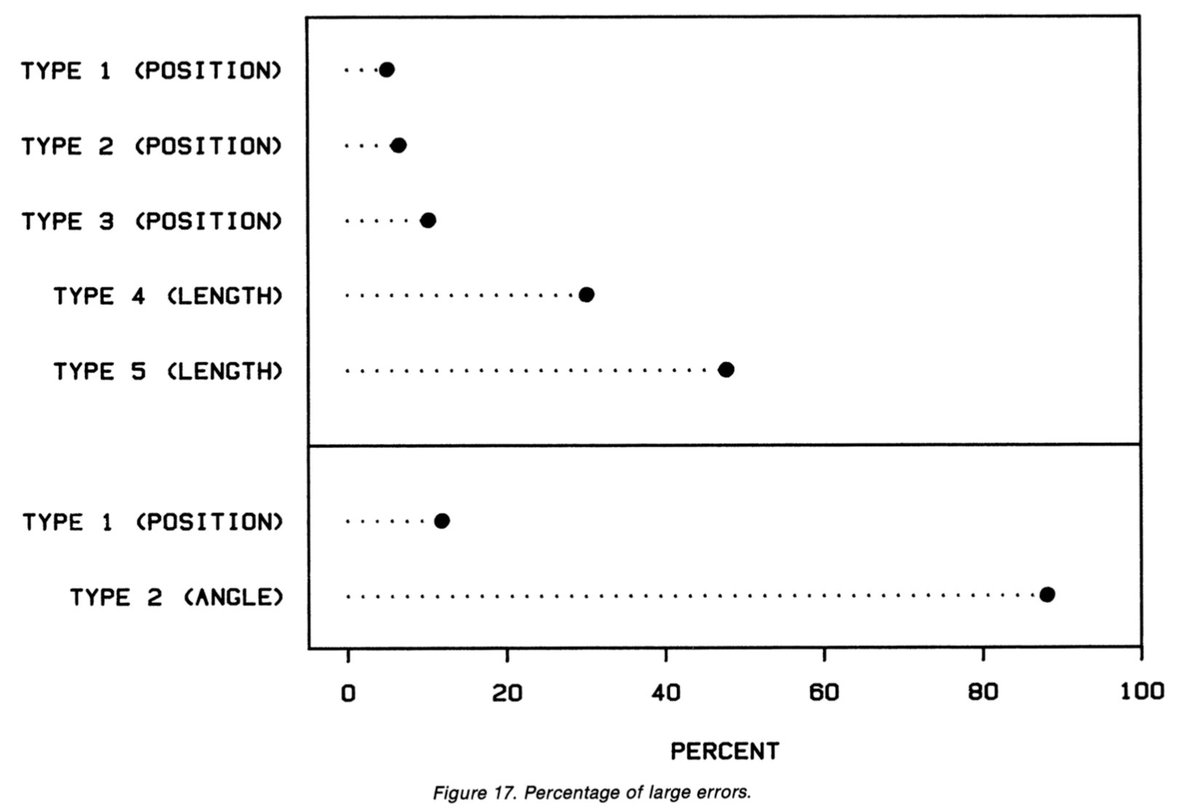
La répartition en pourcentages des réponses les plus éloignées de la réalité (les plus grosses erreurs) est encore plus parlante. Dans l’expérience 1, la perception de la longueur totalise 78% des grosses erreurs. Dans l’expérience 2, les angles en totalisent 88% (25/29)
La conclusion du travail de Cleveland et McGill c’est qu’il vaut mieux privilégier l’utilisation des diagrammes à barres ou à point pour représenter les données quantitatives, plutôt que les camemberts (26/29)
Dans les diagrammes à barres, on compare les positions des sommets de chaque barre. Ce qui est beaucoup plus précis, perceptuellement, que de comparer les angles et les surfaces des parts des camemberts (27/29)
« Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods », de W. S. Cleveland et R. McGill a été publié en septembre 1984 dans le Journal of the American Statistical Association => jstor.org/stable/2288400… (28/29)

