Effective dimension compares favourably to popular path-norm and PAC-Bayes flatness measures, including double descent and width-depth trade-offs! We have just posted this new result in section 7 of our paper on posterior contraction in BDL: arxiv.org/abs/2003.02139. 1/16 
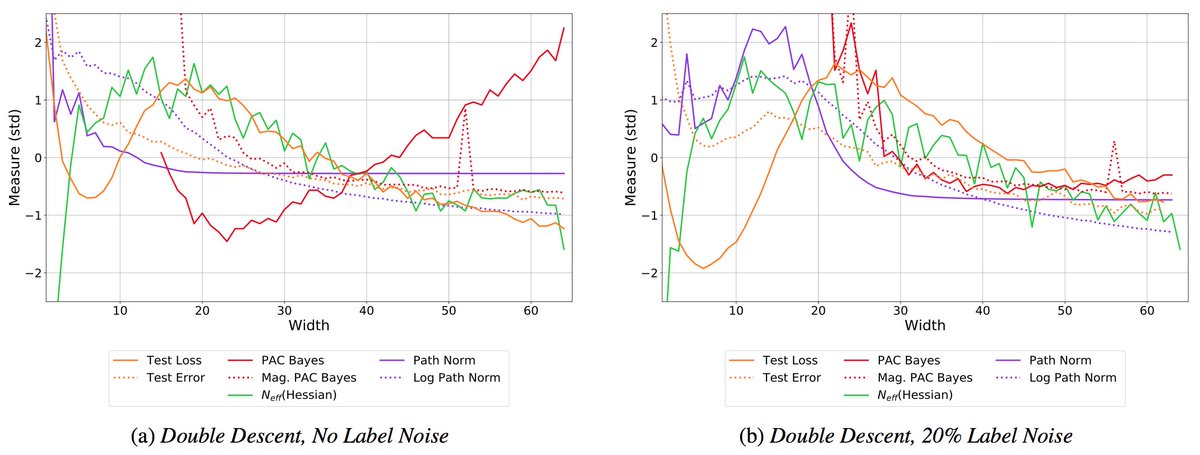
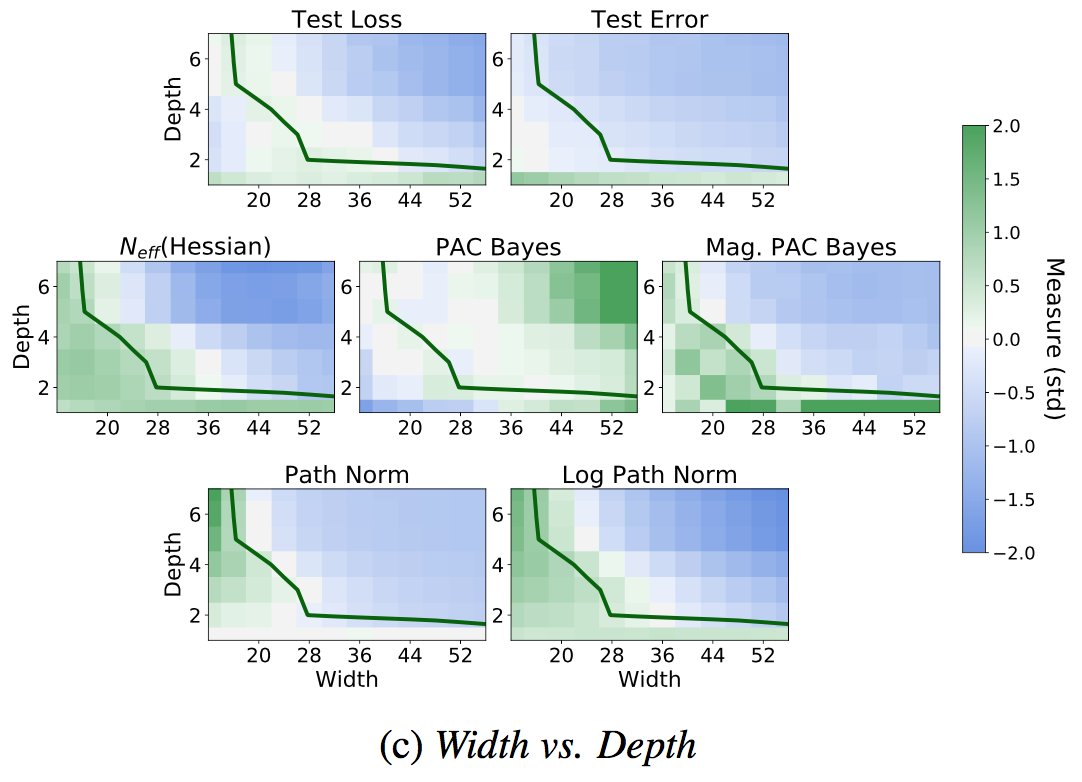
The plots are most interpretable for comparing models of similar train loss (e.g. above the green partition). N_eff(Hess) = effective dimension of the Hessian at convergence. 2/16
Both path-norm and PAC-Bayes flatness variants perform well in the recent fantastic generalization measures paper of Jiang et. al (2019): arxiv.org/abs/1912.02178.
3/16
3/16
We found path-norm has little relative preference between large neural nets with very different generalization performance. This is partly because the weights for small models train to much larger values. 4/16
Intriguingly, we found taking a log transform of path-norm significantly helps with tracking generalization across a range of large neural nets. Perhaps log path-norm is more robust in general? 5/16
However, path-norm acts only on model parameters, and is thus not directly connected to function-space or the shape of the loss.
6/16
6/16
The PAC-Bayes based flatness measure in Jiang et. al (2019) takes the expectation of the loss over random perturbations. This measure actually increases with model size and is anti-correlated with generalization performance. 7/16
The magnitude-aware version of this measure, which scales the perturbation by parameter magnitudes, helps but does not entirely resolve stability.
8/16
8/16
Moreover not all flatness measures are equivalent. The flatness measure in Jiang et. al is highly sensitive to the sharpest direction, and the corrected version does not perform as well as effective dimension.
9/16
9/16
Why does double descent happen? Double descent is an artifact of over-fitting. As the dimensionality of parameter space increases past the point where the corresponding models achieve zero training error, flat regions of the loss occupy a greatly increasing volume. 10/16
These solutions are thus more easily discoverable by optimization procedures such as SGD. These solutions have lower effective dimensionality, which essentially measures the number of flat directions in the surface given by eigenvectors of the Hessian. 11/16
In section 5, we show that in these directions there is function-space homogeneity, connecting effective dimension with model compression. 12/16

These more easily discoverable solutions therefore provide better lossless compressions of the data, and thus better generalization.13/16
Many parameters are therefore a blessing, leading to trained models with a lower effective number of parameters. 14/16
We see that effective dimension does a good job of tracking both test error and test loss for large neural networks (above green partition), or for networks with similar train loss.
15/16
15/16
If you're looking at generalization measures, we recommend you consider effective dimension as a baseline. It’s relatively robust and easy to compute, with code available at: github.com/g-benton/hessi…
Work with @g_benton_ and Wesley Maddox. 16/16
Work with @g_benton_ and Wesley Maddox. 16/16