Our new paper "Bayesian Deep Learning and a Probabilistic Perspective of Generalization": arxiv.org/abs/2002.08791. Includes (1) benefits of BMA; (2) BMA <-> Deep Ensembles; (3) new methods; (4) BNN priors; (5) generalization in DL; (6) tempering in BDL. With @Pavel_Izmailov. 1/19 
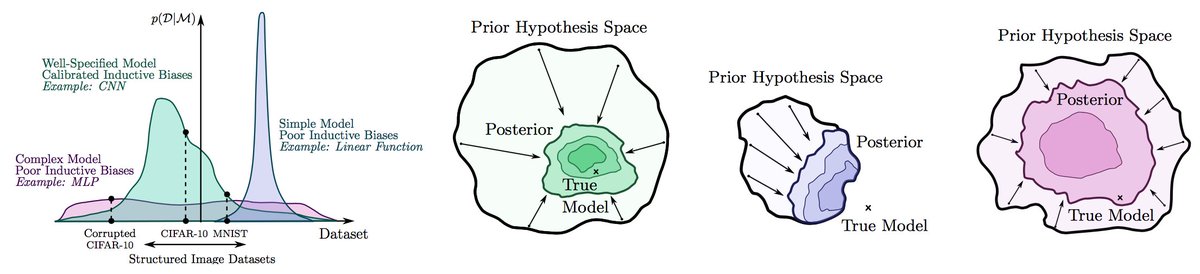
Since neural nets can fit images with noisy labels, it has been suggested we should rethink generalization. But this behaviour is understandable from a probabilistic perspective: we want to support any possible solution, but also have good inductive biases. 2/19
The inductive biases determine what solutions are a priori likely. Indeed, we show this seemingly mysterious behaviour is not unique to neural nets: GPs with RBF kernels can perfectly fit noisy CIFAR, but also generalize on the noise free problem. 3/19

We should not conflate flexibility with complexity. RBF-GPs are highly flexible, but have simple inductive biases. While BNNs *can* fit noise, noisy datasets are unlikely in the prior over functions induced by a simple parameter prior, as per the marginal likelihood. 4/19
Indeed, the prior over functions p(f) induced by p(w)=N(0, a I) encapsulates many of the desirable properties of neural nets that help them generalize, including a reasonable prior correlation structure over images. 5/19

These properties of the prior matter more than e.g. signal variance. In the cold posterior paper, it appears sample prior functions assign mostly 1 class to all data. While this behaviour appears dramatic, it is simply an artifact of a bad signal variance ‘a'… 6/19

A large signal variance causes the softmax to quickly saturate. This behaviour is easy to fix by tuning ‘a', or using what is standard for L2 reg. And even a bad ‘a’ leads to a reasonable prior predictive distribution, and a posterior that quickly adapts to data. 7/19


We present several views on tempering. (1) It would be surprising for T=1 to in fact be the best setting of this hyperparameter; tempering reflects misspecification, and we all know our models are misspecified. 8/19
(2) In this sense, the tempered posterior is closer to representing our true beliefs that the model is misspecified than a posterior with no tempering. And Bayesian inference is all about marginalization and how our honest beliefs interact with data to form a posterior. 9/19
(3) Further, tempering is a simply a modification of our observation model. Learning the tempering parameter is the same as learning noise in a regression model, which is what we would always do in a Bayesian approach. 10/19
(4) If we are worried about T<1 overcounting data, then we must also say we believe the T=1 likelihood, which is not likely true. Moreover, empirical Bayes counts the same data in the prior and likelihood, but is embraced and championed in foundational work on BNNs. 11/19
(5) There is a body of work on understanding tempering in a Bayesian setting, referred to as Safe Bayes and Generalized Bayesian Inference (for both T<1 and T>1). 12/19
(6) Also there are cases where given finite computation, tempering can be preferred even if we believe the prior and untempered likelihood. We consider these questions further in the paper. 13/19
We also emphasize that one should not conflate simple MC with BMA. Our goal is not to produce accurate samples from a posterior, but to evaluate an integral subject to computational constraints. 14/19
Indeed, we show from this perspective of integration, deep ensembles can provide a *better* approximation to BMA than standard approaches to approximate Bayesian inference. 15/19

Inspired by deep ensembles, we propose MultiSWAG, which marginalizes within basins. We see with the same training time, we can get much better performance than deep ensembles, especially for highly corrupted data. 16/19


While it has been claimed recently that Bayesian methods are typically applied in the underparametrized regime, this is not true. See this quote from David MacKay, 25 years ago. BMA is in fact most valuable when the posterior is underspecified. 17/19

The appendix has several additional results, including correlation structures induced by a BNN prior subject to a variety of data perturbations, and additional results for deep ensembles, multiSWA, and multiSWAG. 18/19


Additional experiments, results, discussions, perspectives, thoughts, in the paper. Code (including MultiSWAG) also available:
github.com/izmailovpavel/…
And it was wonderful working with @izmailovpavel, an amazing collaborator. 19/19
github.com/izmailovpavel/…
And it was wonderful working with @izmailovpavel, an amazing collaborator. 19/19
Argh... apple :)
Here are the correct figures.
Here are the correct figures.