
The concept of individual differences.
Question #1: do they really exist? Is it possible for a difference to really exist?
I can hear you shouting: ‘Of course they do, come and visit my classroom!’
Yet I once surprised Denny Borsboom (research on validity) with my question.
Question #1: do they really exist? Is it possible for a difference to really exist?
I can hear you shouting: ‘Of course they do, come and visit my classroom!’
Yet I once surprised Denny Borsboom (research on validity) with my question.
In decision making: choose the option with the higher expected utility. Even if the differences between expected utilities of your options are small and statistically not significant. (where is that publication of Herb Simon?)
How does that impact educational decision making?
How does that impact educational decision making?
[On utility functions: benwilbrink.nl/projecten/spa_…
Expected utility is the ‘product’ (weighting) of the probability density and the utility function.
F.e. threshold utility functions 0 (fail) and 1 (pass) a test. Expected utilities then equal chances to pass the test].
Expected utility is the ‘product’ (weighting) of the probability density and the utility function.
F.e. threshold utility functions 0 (fail) and 1 (pass) a test. Expected utilities then equal chances to pass the test].
Utility and expected utility, totally different concepts, tend to be confused / mixed up In the literature on criterion referenced testing. There is still work to do here ;-)
In personnel testing the employer will choose the candidates he expects will contribute best.
In personnel testing the employer will choose the candidates he expects will contribute best.
An example: 19th c. admissions to the U.K. Civil Service. The exams order candidates, available slots (numerus clauses) get filled by the relatively best.
There'll be a small and definitely insignificant difference between the last person selected and the first one rejected.
There'll be a small and definitely insignificant difference between the last person selected and the first one rejected.
Is that a problem? How can a small definitely insignificant difference be a ‘valid’ difference? It can not. Here we have a small difference having large consequences. How is that to be defended or explained?
Edgeworth 1888 answers that question: benwilbrink.nl/projecten/lote…
Edgeworth 1888 answers that question: benwilbrink.nl/projecten/lote…
The answer goes somewhat as follows. The examination is the best we can do. Because of the restricted number of slots not everybody can be admitted, only the relatively best. Of course, close to the cut-off the chances will be about 0.5. Candidates will have to bear the risk.
Up to a certain point candidates can better their chances to get admitted by investing more (time, means) in preparation. They are free to do so. They are free not to participate in the examination (yet).
I like this case, and its illuminating treatment by Edgeworth.
I like this case, and its illuminating treatment by Edgeworth.
That case might illustrate many crucial points regarding individual differences and we use to deal with them.
For starters, de dimension of differences is a valued one; scores typically are valued as relatively ‘better’ or ‘worse’.
Better or worse for whom: the Civil Service.
For starters, de dimension of differences is a valued one; scores typically are valued as relatively ‘better’ or ‘worse’.
Better or worse for whom: the Civil Service.
The better candidate is expected to contribute more (expected utility, EU) to the goals of the organization. For all practical purposes the EU of the last candidate admitted is nearly the same as the EU of the first candidate rejected, yet the Service sticks to its decision.
The concept of scores being ‘better’ or ‘worse’ is itself a complex one. Better for whom? For the Civil Service; the Service decides who to admit. Better for the candidate; the better score is the less risky one (before the cut-off score is known). Is it better for society?
The CS is important, of course. But so are the health service, the military, private businesses, the culture sector. Insofar as they are competing with each other for the same human capital, selective admissions to the CS might be harmful to society at large.
Hiring psychologists to improve personnel selection for the CS might have a large profit, for the CS. ‘To improve’ meaning: developing an examination that has better validity (higher total EU). However, if every sector in society does the same, the profits are negative.
In Holland medical studies have a restricted number of slots (numerus fixus); they are allowed to select from the larger number of candidates. Is that a selection for the good of society, or does it benefit only the particular departments involved?
[More on the Dutch ways of selecting for higher education, esp. the weighted lottery system used from 1976 until 2017?:
‘The weighted lottery in the admission to ‘restricted’ university studies in the Netherlands’
benwilbrink.nl/projecten/lott…]
[Rebecca Zwick 2017 is not quite correct]
‘The weighted lottery in the admission to ‘restricted’ university studies in the Netherlands’
benwilbrink.nl/projecten/lott…]
[Rebecca Zwick 2017 is not quite correct]
What I am thinking now is: the concept of individual differences is highly abstract, in the sense of abstracted from content and context. It reminds me of the concepts of remembering or understanding: treated as processes that exist as such, separated from specific content.
If your spontaneous association here is with the cognitive taxonomy of Bloom c.s. 1957: you are right. See
J. E. Furst (1981). Bloom’s taxonomy of educational objectives for the cognitive domain: philosophical and educational issues. RER jstor.org/stable/1170361
J. E. Furst (1981). Bloom’s taxonomy of educational objectives for the cognitive domain: philosophical and educational issues. RER jstor.org/stable/1170361
Furst (section ‘Questions of epistemology’) cites Sockett 1971 sci-hub.tw/10.1080/030576…:
“We cannot posit remembering in any sense APART from content. If remembering is thought of as content-free we have an empty concept which could not be even part of an educational objective.”
“We cannot posit remembering in any sense APART from content. If remembering is thought of as content-free we have an empty concept which could not be even part of an educational objective.”
unroll @threadreaderapp
What I am trying to do here is problematizing the idea of individual differences. Complicating it.
On a math test Ben scores just short of the passing score, Ed scores exact the passing score. What does it mean here to say Ed scores 1 point better than Ben?
On a math test Ben scores just short of the passing score, Ed scores exact the passing score. What does it mean here to say Ed scores 1 point better than Ben?
We happen to secretly know that Ben has not prepared himself for this test, while Ed has worked very hard. Ben’s parents are poor workers, Ed’s parents are well to do and highly educated. Etcetera. The question being: how are test results to be explained? And their differences?
To get an idea how this might work: a fully recursive path model in benwilbrink.nl/publicaties/77… (text itself is in Dutch) :
How to explain individual differences in assessment test scores, given: capabilities, aspiration levels, and time on preparation.
How to explain individual differences in assessment test scores, given: capabilities, aspiration levels, and time on preparation.
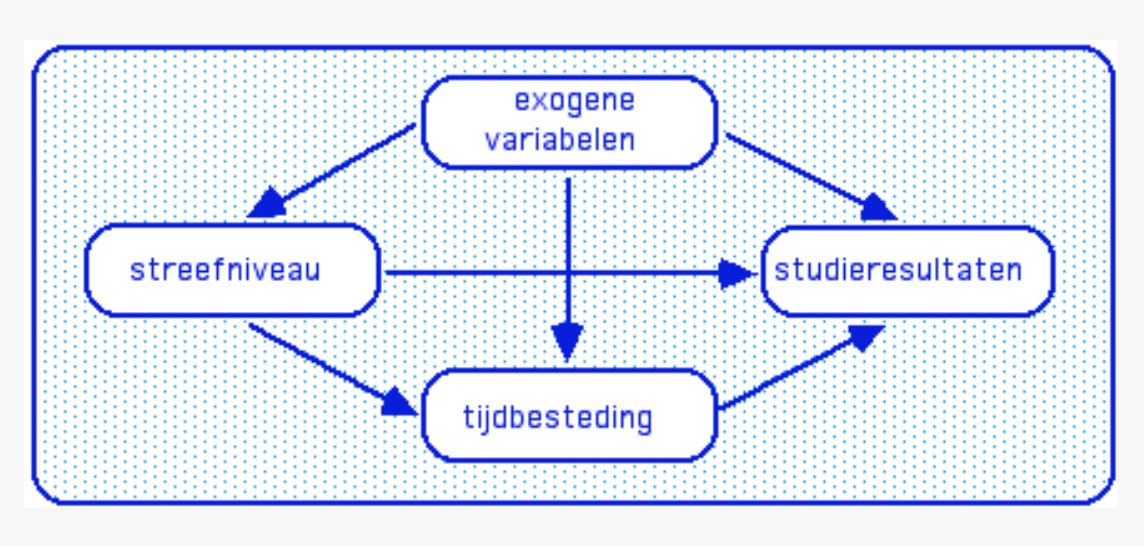
A simple individual difference on the assessment (‘studieresultaten’) can be effected by a myriad of possible combinations of capabilities (‘exogene variabelen’), aspiration levels (‘streefniveau’) and time on preparation (‘tijdbesteding’) of two students.
And do not take those scores on the assessment for granted: the same testscore can be reached also in a myriad number of ways of combining right and wrong answers on the separate items of the assessment. There is no particular ‘sameness’ in the same score on the same test!
Which brings me to another issue: the ‘same’ test might be just another test on the same course content. What is the sameness of different tests on the same content? [technically: equivalence, or even: tau-equivalence] Test developers worry about it, students couldn’t care less.
Developers will try to make the next test just as difficult as the last one. ‘Just as difficult’: about the same mean score and standard deviation that is.
For the student the situation is quite another one: every test looks like a random sample from a domain of possible items.
For the student the situation is quite another one: every test looks like a random sample from a domain of possible items.
Suppose, for the sake of argument, that the student knows his mastery of all possible items on this articular course content to be 0.6 (60%). What would he know about his score on the next 20 item test?
Recognize the binomial model here. wolframalpha.com/input/?i=binom…
Recognize the binomial model here. wolframalpha.com/input/?i=binom…
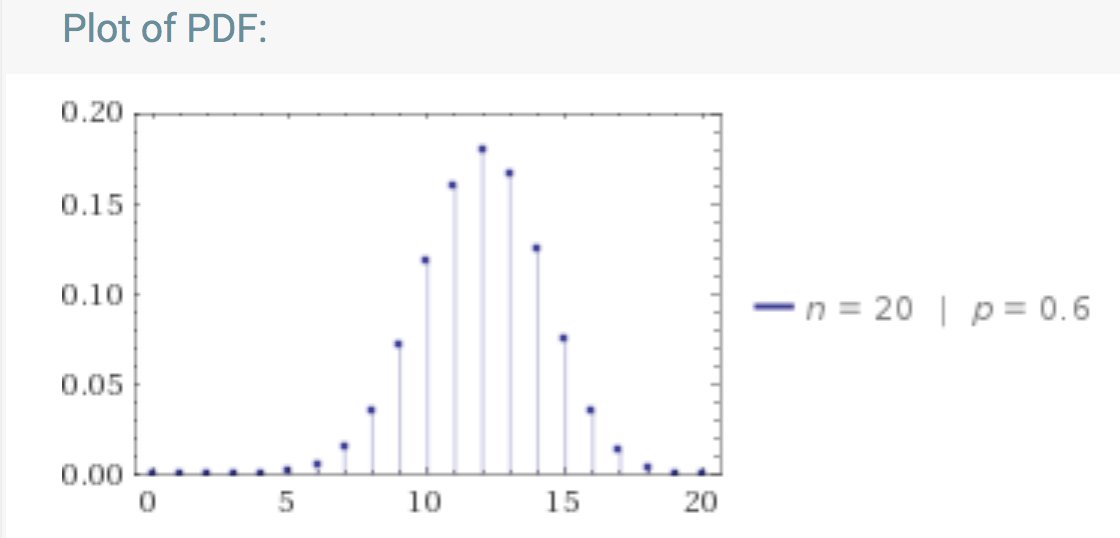
Your score (you are that student) can be anywhere onder that curve!
To bring in individual differences: suppose your girlfriend also has a mastery of 0.6, her score can also be anywhere under that curve.
The DIFFERENCE of the two scores has no meaning at all: it is random!
To bring in individual differences: suppose your girlfriend also has a mastery of 0.6, her score can also be anywhere under that curve.
The DIFFERENCE of the two scores has no meaning at all: it is random!
More on the binomial model for tests: ‘The Generator - Module one of the SPA model: Scores’ benwilbrink.nl/projecten/spa_…
It is possible to relax that assumption of knowing one’s mastery. Replace it with the assumption of having scored 12 on a preliminary test of 20. What do you know?
It is possible to relax that assumption of knowing one’s mastery. Replace it with the assumption of having scored 12 on a preliminary test of 20. What do you know?
The preliminary test is drawn from the same domain. It is possible from your score of 12/20 to derive the likelihood for your mastery, as explained in benwilbrink.nl/projecten/spa_…. The function is known (Novick and Jackson 1974 p. 109) to be a beta function: wolframalpha.com/input/?i=Beta%…
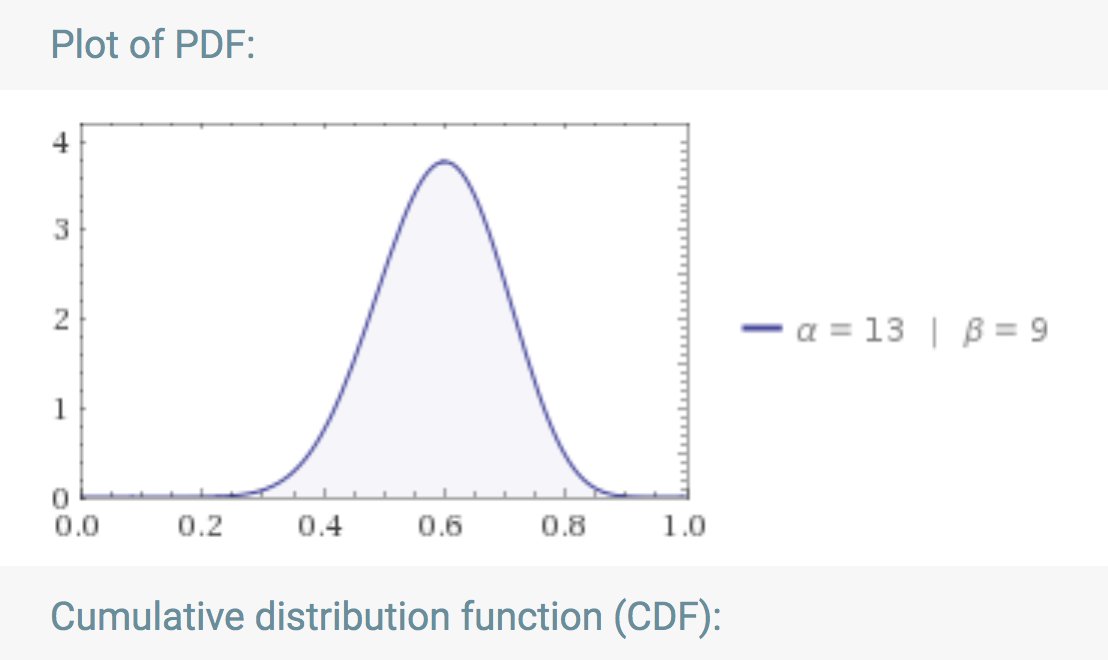
Your ‘true’ mastery can be anywhere under that curve, its maximum likelihood being 0.6. Suppose your friend also score 12/20, her true mastery might be anywhere under that curve. We do not know where, nor do we know of any difference. However, now we can predict the next score!
Knowing the likelihood, that prediction is known to be a betabinomial distribution. benwilbrink.nl/projecten/spa_… Assuming the 12 out of 20 score on a preliminary test, the predicted score on the next 60-item test is wolframalpha.com/input/?i=betab…. Try some other values for the parameters.
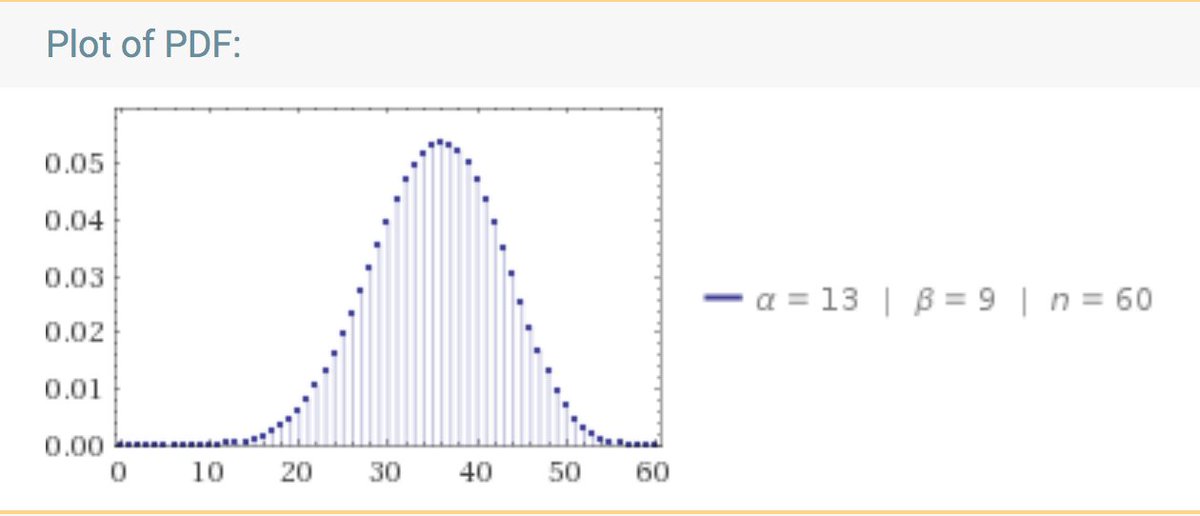
Your score can be anywhere under that curve. Amazed? Rightly so. Your friend will not fare any better. Your scores will probably differ a lot more than you had thought without doing the math. Does such a difference mean that your ‘true’ mastery is different from hers? Yes.
Predicting the score on the next test turns out to be difficult, in the sense that there is a rather large spread around the expected value (the mean of the predictive distribution). Now empathize with the students: how can they know whether they are sufficiently prepared?
Yet they have to bear the risk of obtaining scores that are too low (for whatever the decision is that will be taken on the basis of those scores). See the problem? Mainstream psychometrics (handbooks on educational measurement) disregards the interests of students.
The design of the test, quality of the test items, the regulations that the test is part of, they all influence student behaviors in preparation for the test. Teachers/institutions have lots of possibilities to nudge student behaviors, and that way affect individual differences.
For references to the literature, see my ResearchEd Netherlands paper [in English] benwilbrink.nl/publicaties/17…
Nudging student behavior is one thing, be warned that the reverse will also happen: students nudging teacher behavior.
Nudging student behavior is one thing, be warned that the reverse will also happen: students nudging teacher behavior.
The complex result is a kind of collective negotiation, students investing time, teachers investing grades. How to model this kind of implicit give-and-take was worked out by James Coleman (1990 Social system theory). A research case: benwilbrink.nl/publicaties/92… Yes, strong effects.
It is nice to be able to show this dynamic, it does not mean however that this dynamic is productive of good education. Individual differences get abused by both parties in this game, yet neither party is particularly aware of what is happening. Break the spell, get rational.

