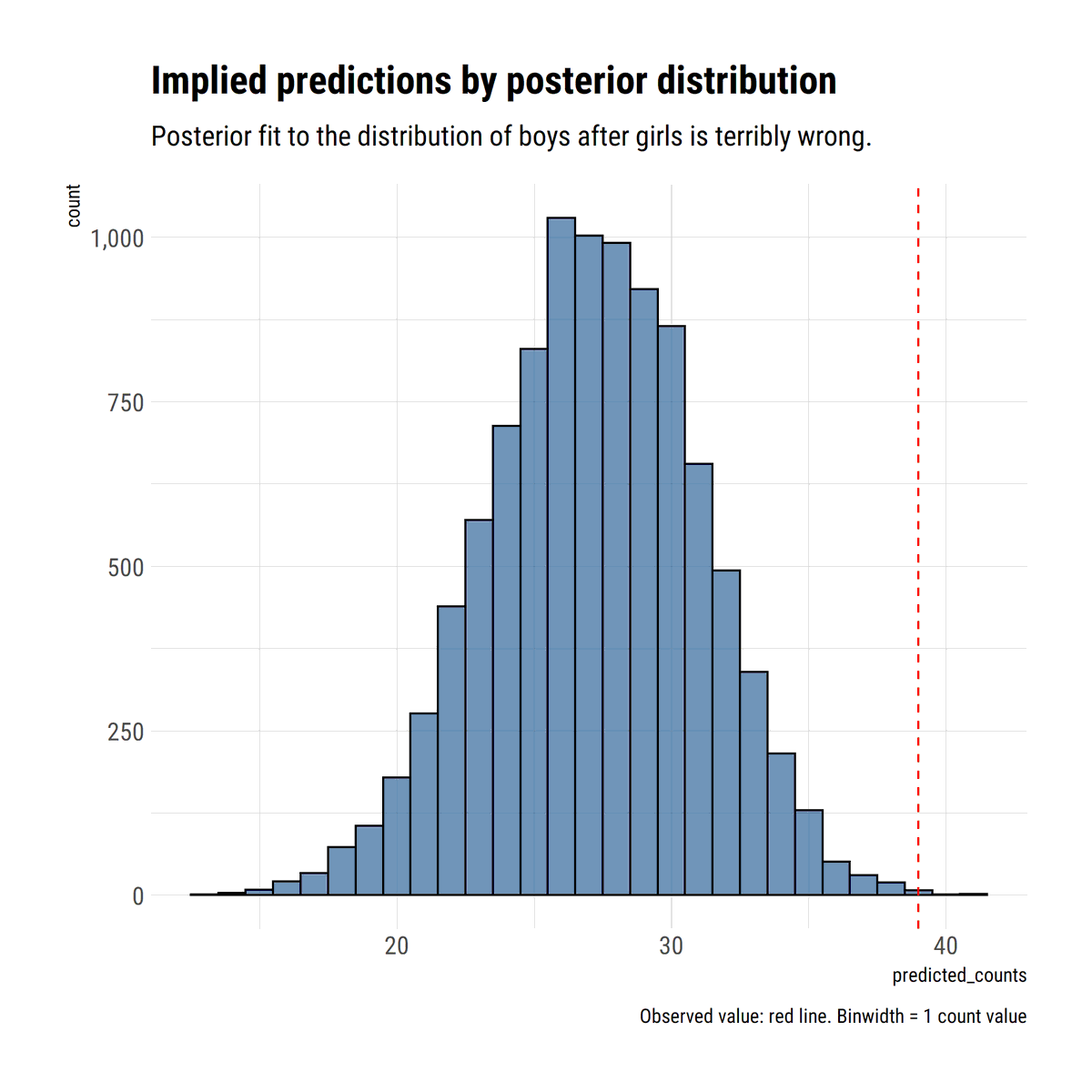
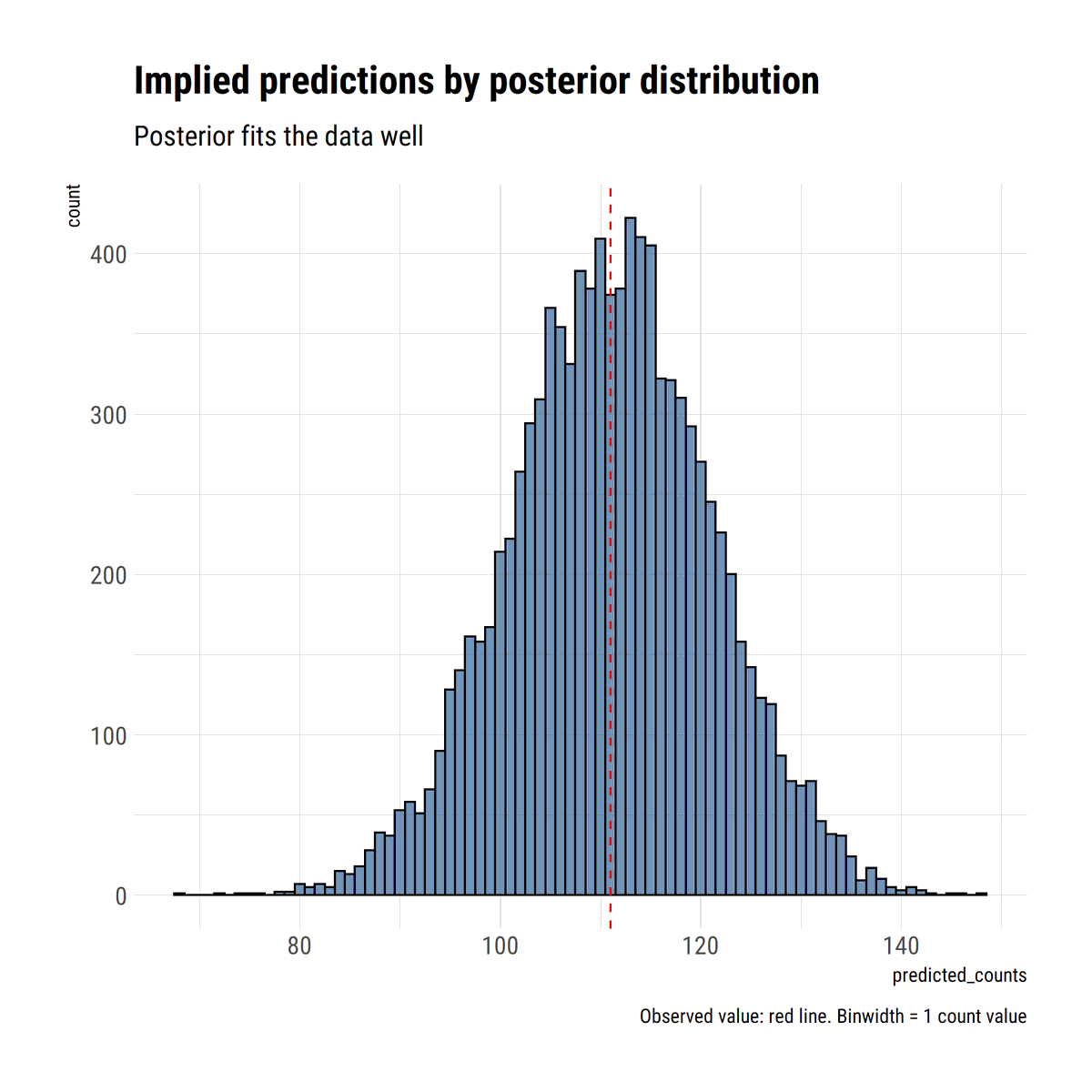
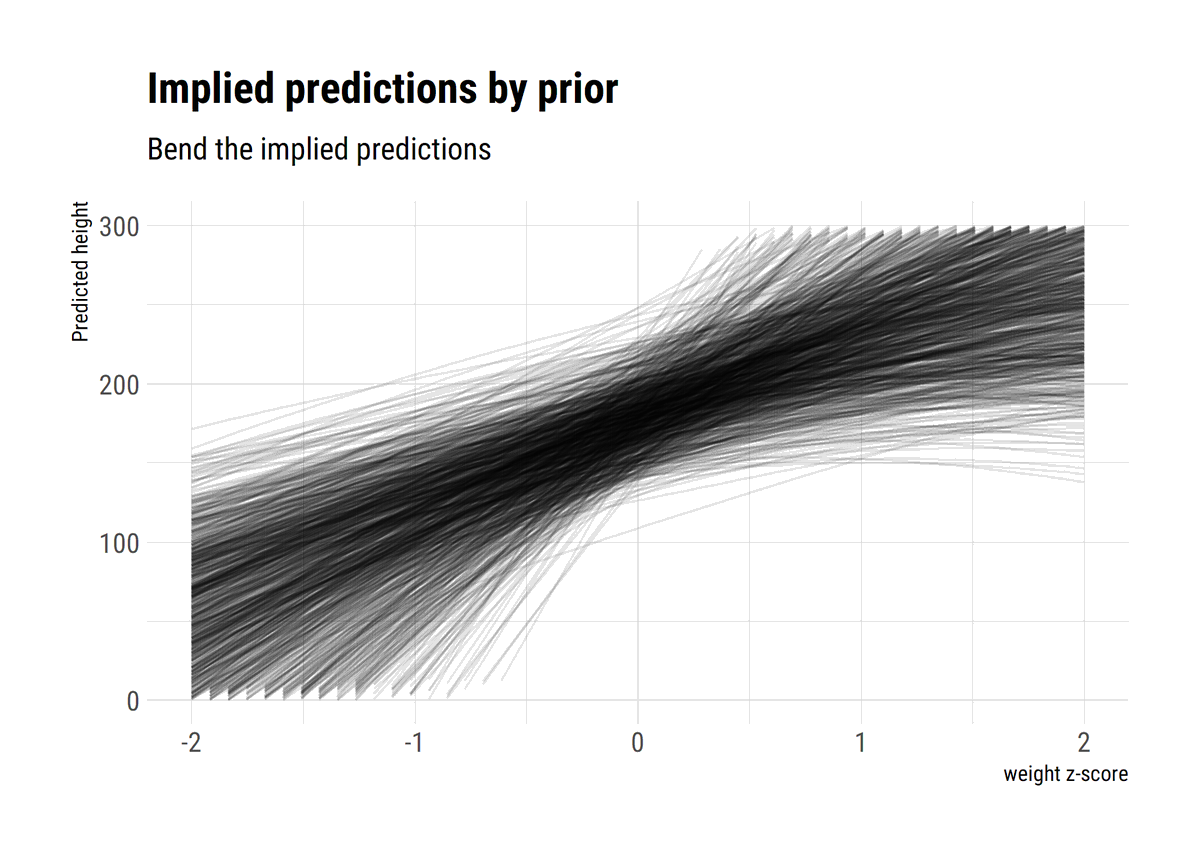
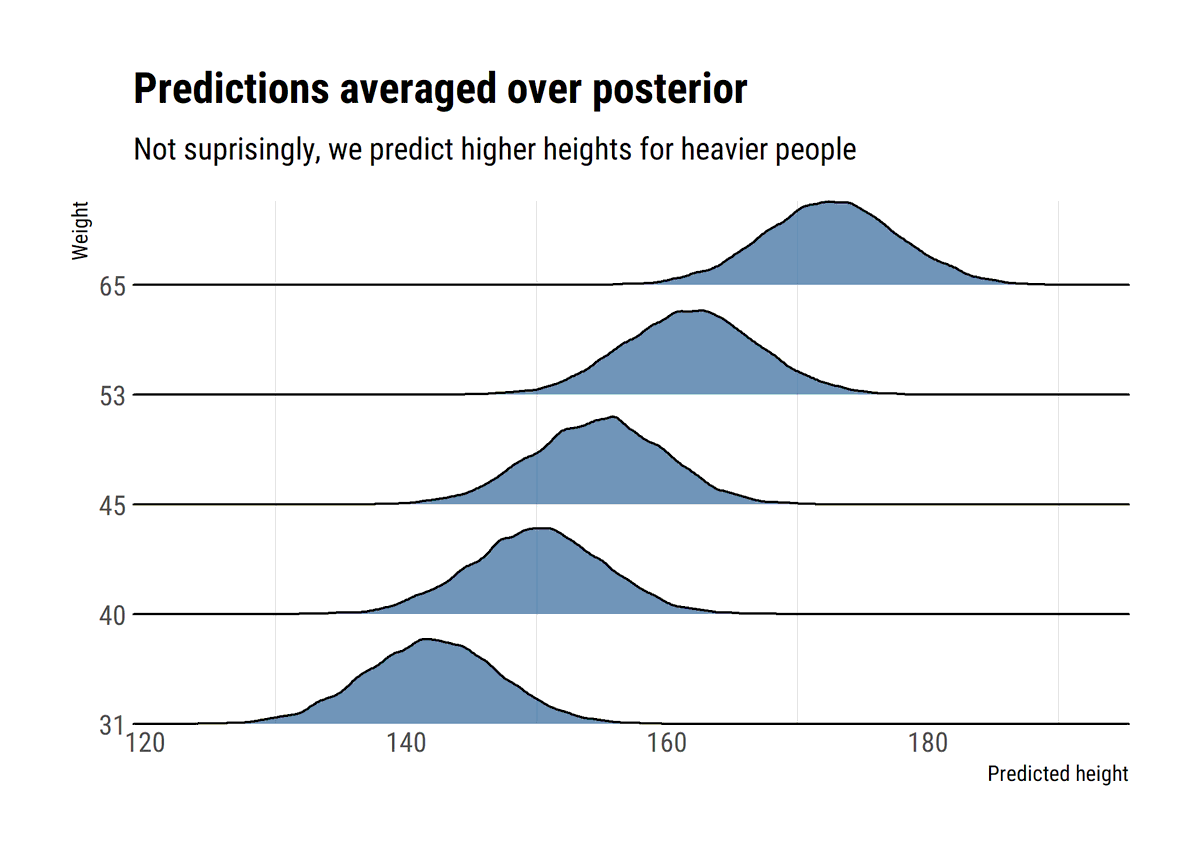
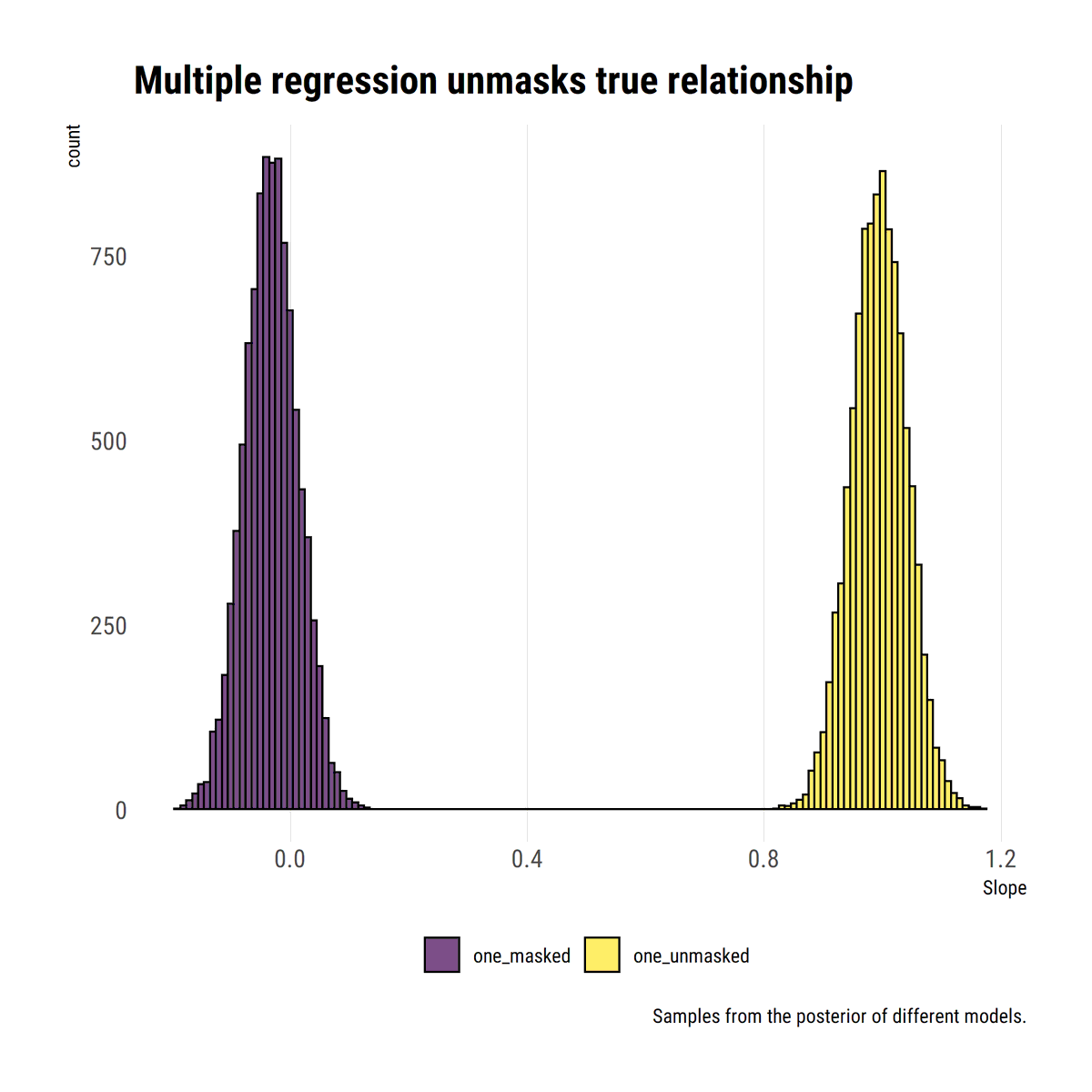
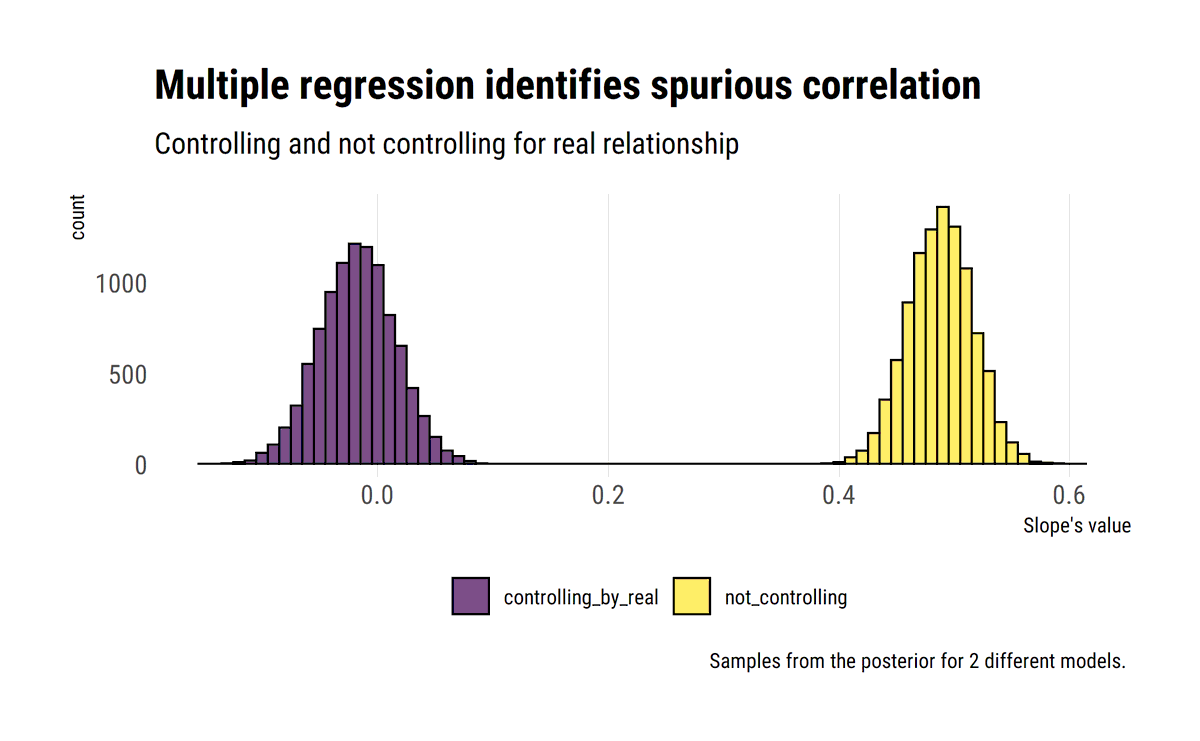
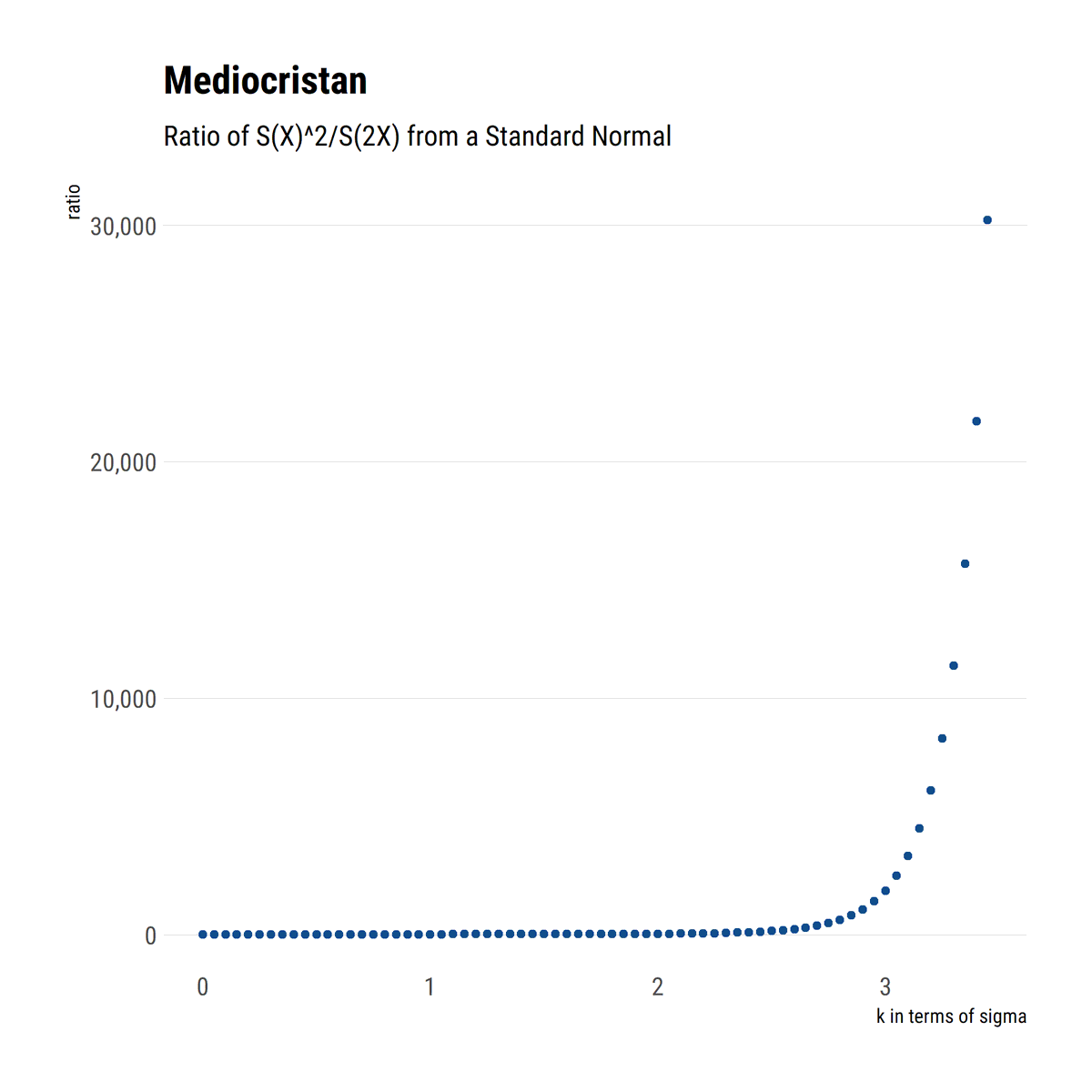
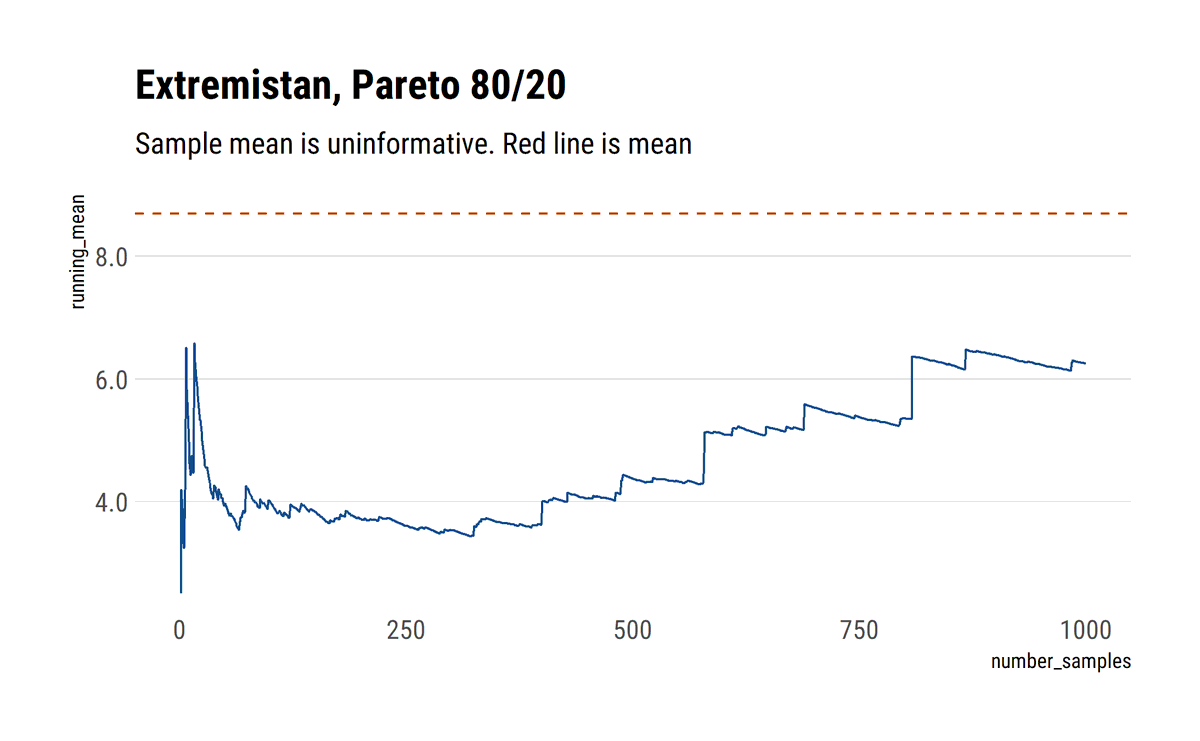
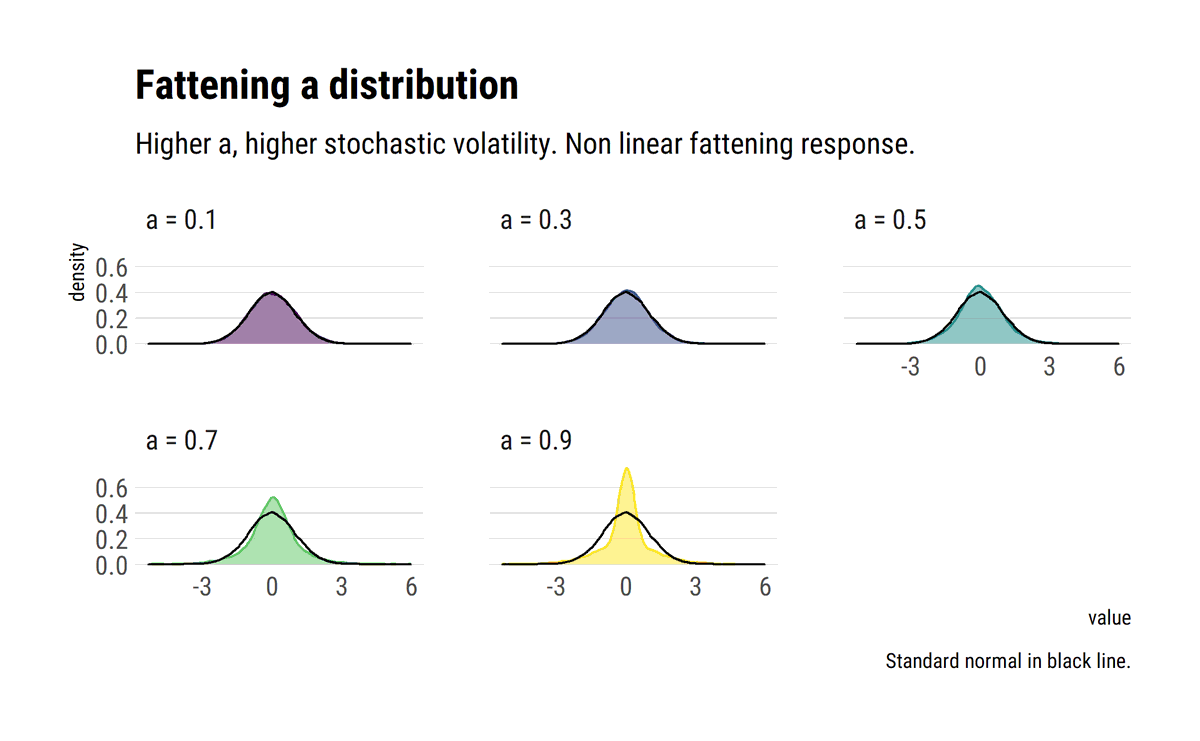
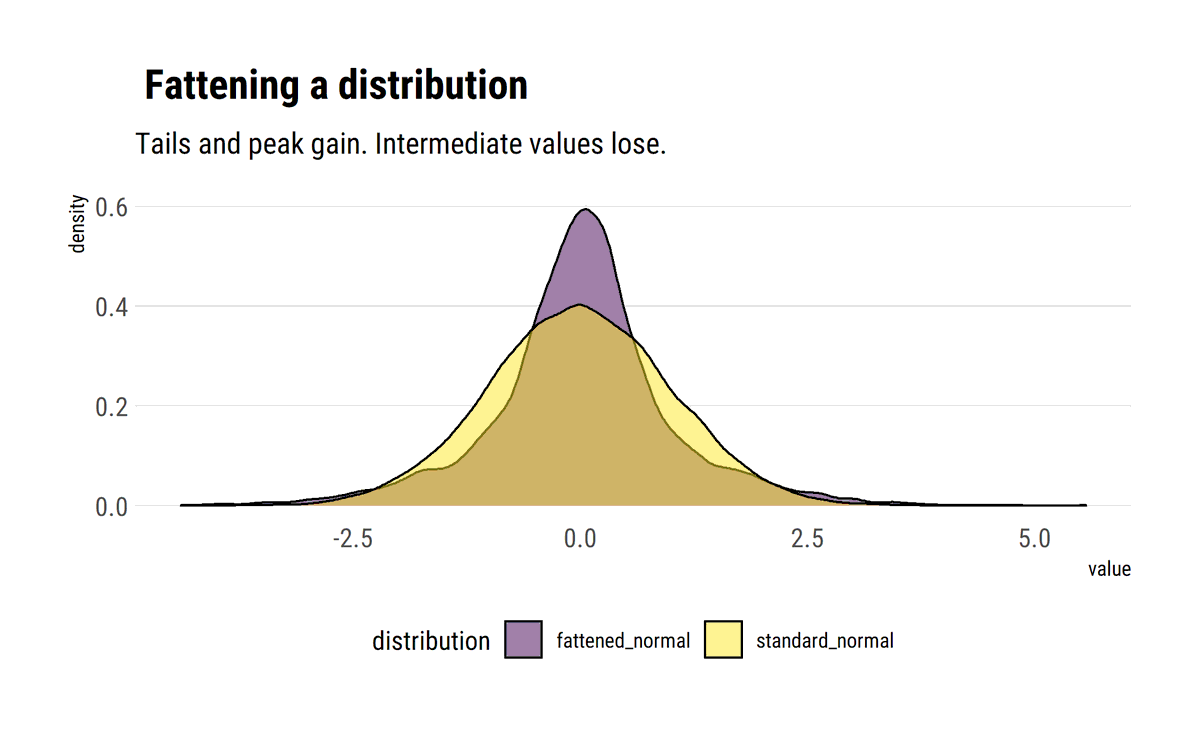
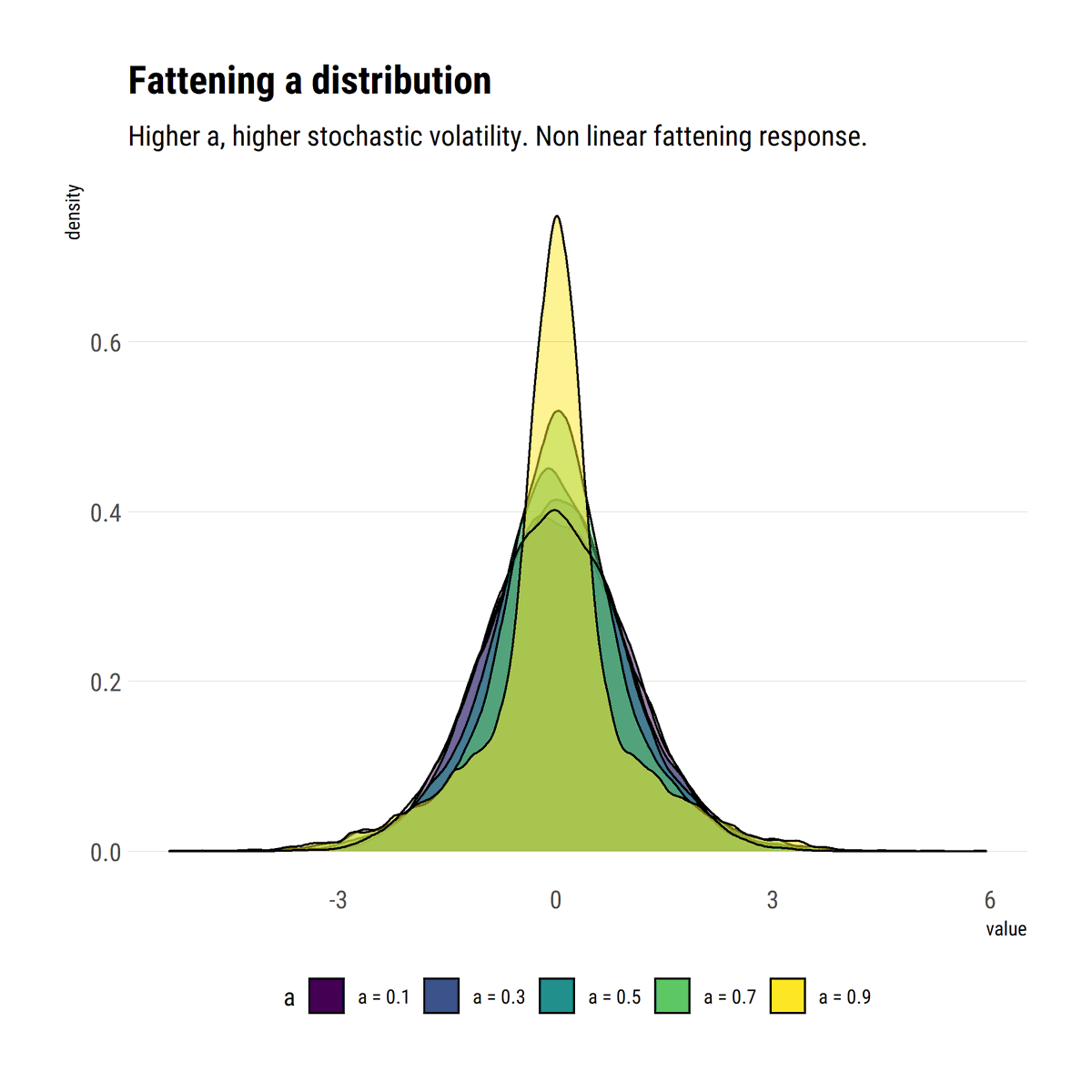
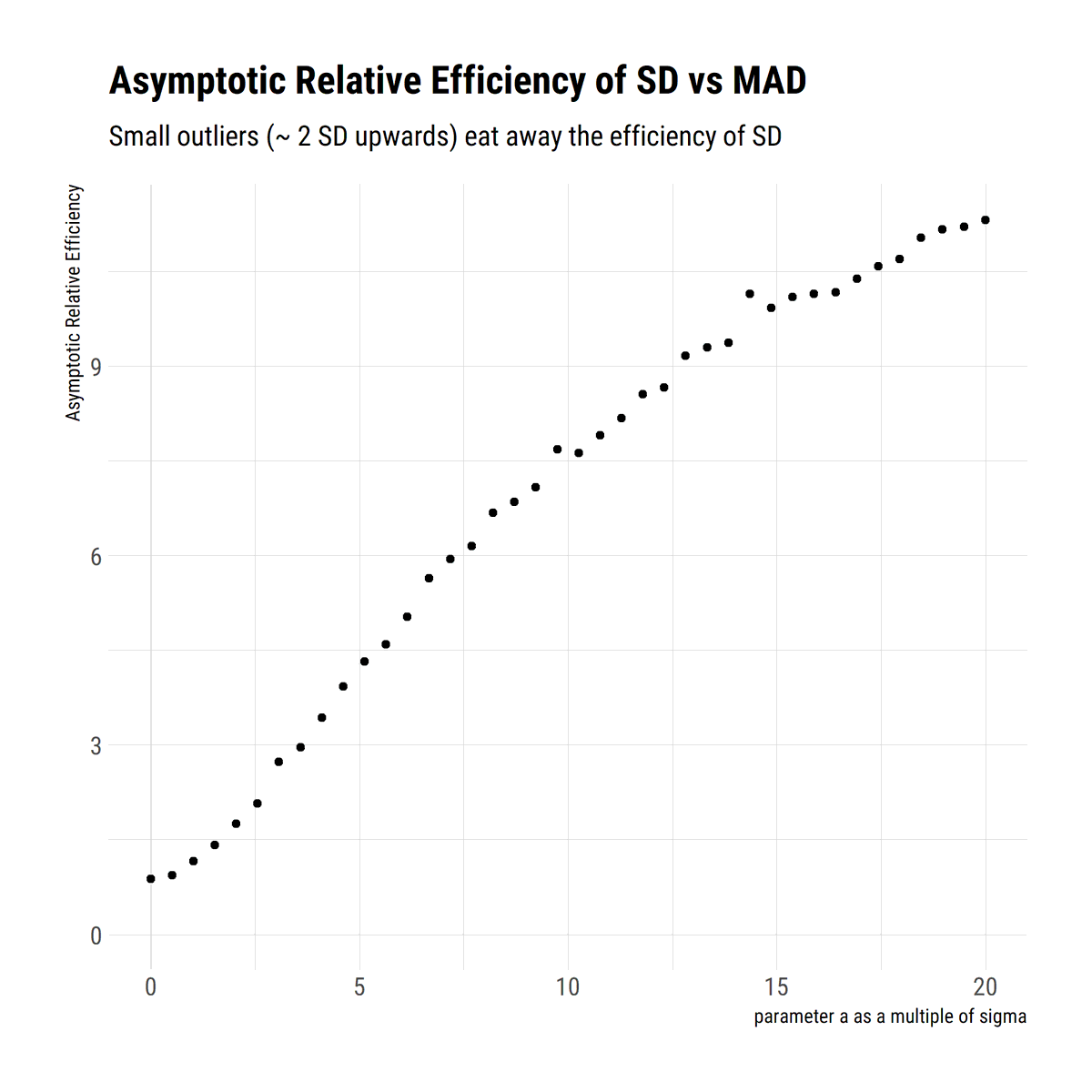
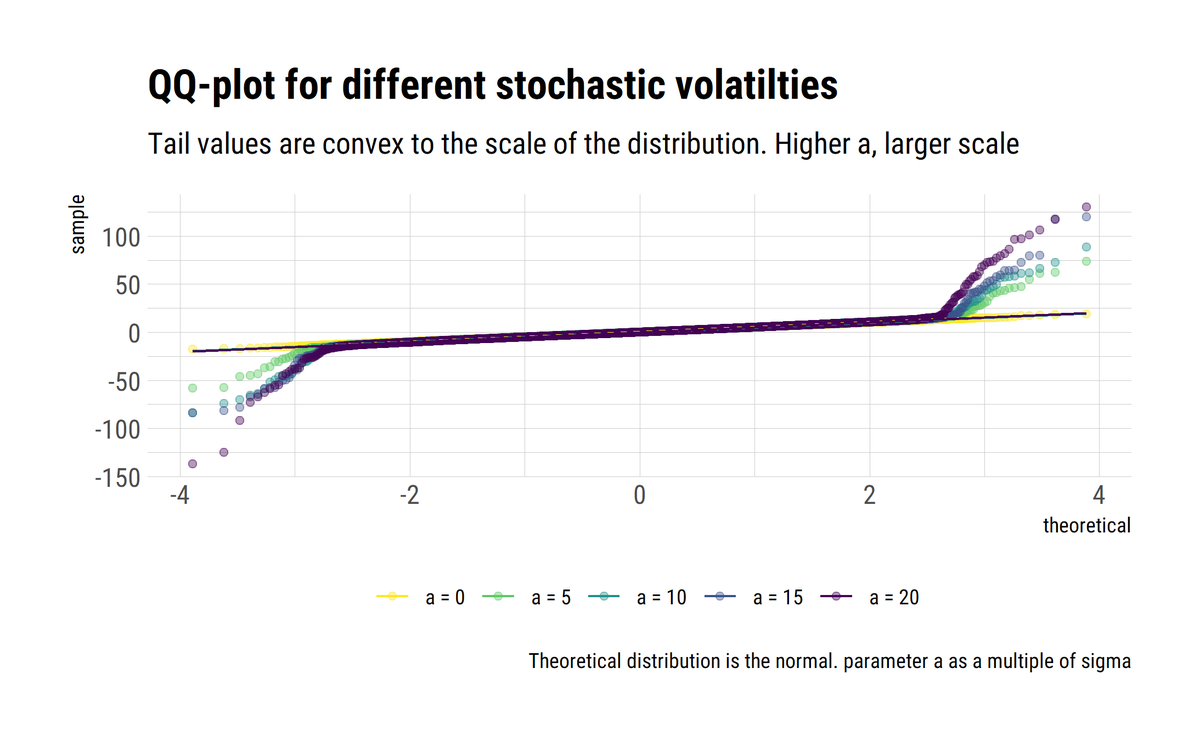
I find stats talk around causality wanting: most of the time, the concept is simply side-stepped. To remedy this, I'll read through @yudapearl's seminal work 'Causality' using his 'Book of Why' as an interpretative key. In this thread, I'll share what I learn.
Bayesian Networks and Probability Distributions. How can we model a joint probability distribution in a computer? What is the probabilistic connection? d-separation and testable implications from graphical methods, Ladder of Causation..
Blogpost:
david-salazar.github.io/2020/07/18/cau…
#rstats
Blogpost:
david-salazar.github.io/2020/07/18/cau…
#rstats



1/N
Joint probability distributions are tricky to represent: in our heads and our computers. Let's model our conditional independence assumptions with a Graph: for any node, conditional on its parents, the variable is conditionally independent of all other preceding variables.
Joint probability distributions are tricky to represent: in our heads and our computers. Let's model our conditional independence assumptions with a Graph: for any node, conditional on its parents, the variable is conditionally independent of all other preceding variables.
2/N
Such a Graph (G) is called a Bayesian Network. It yields a recursive decomposition of the joint distribution. We say that G can explain the generation of the data represented by a probability distribution (P) that admits such a decomposition.
Such a Graph (G) is called a Bayesian Network. It yields a recursive decomposition of the joint distribution. We say that G can explain the generation of the data represented by a probability distribution (P) that admits such a decomposition.
3/N
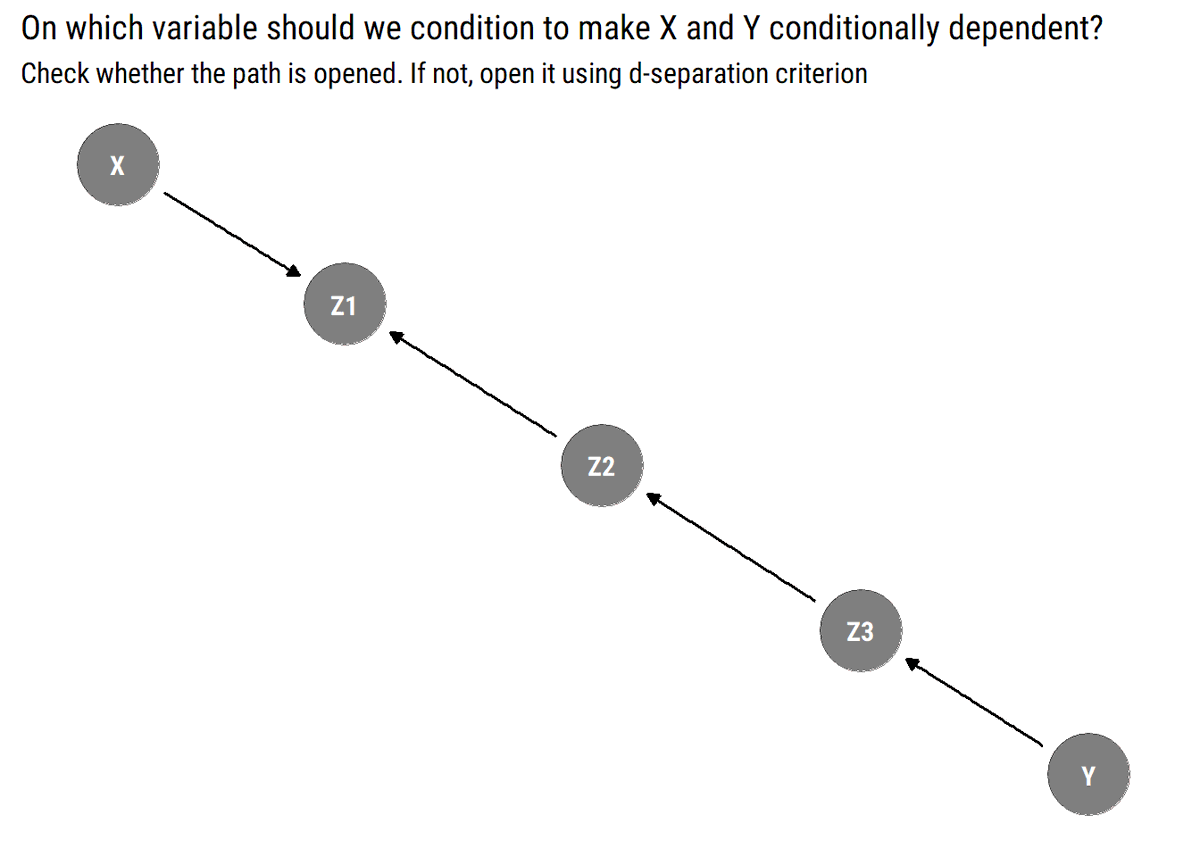
What do we gain? the d-separation criterion: a graphical analysis furnishes what are the conditional and marginal independencies that should hold in a dataset compatible with our assumptions. X and Y are independent conditional on Z if the paths between them are blocked by Z
What do we gain? the d-separation criterion: a graphical analysis furnishes what are the conditional and marginal independencies that should hold in a dataset compatible with our assumptions. X and Y are independent conditional on Z if the paths between them are blocked by Z
4/N
What is a blocked path? In a path that contains a chain (i→m→j) or a fork (i←m→j), the statistical information will flow from the extreme variables whenever we don't adjust by the middle variable. Thus, they will be d-separated (conditionally independent) Why? ⬇️
What is a blocked path? In a path that contains a chain (i→m→j) or a fork (i←m→j), the statistical information will flow from the extreme variables whenever we don't adjust by the middle variable. Thus, they will be d-separated (conditionally independent) Why? ⬇️
5/N
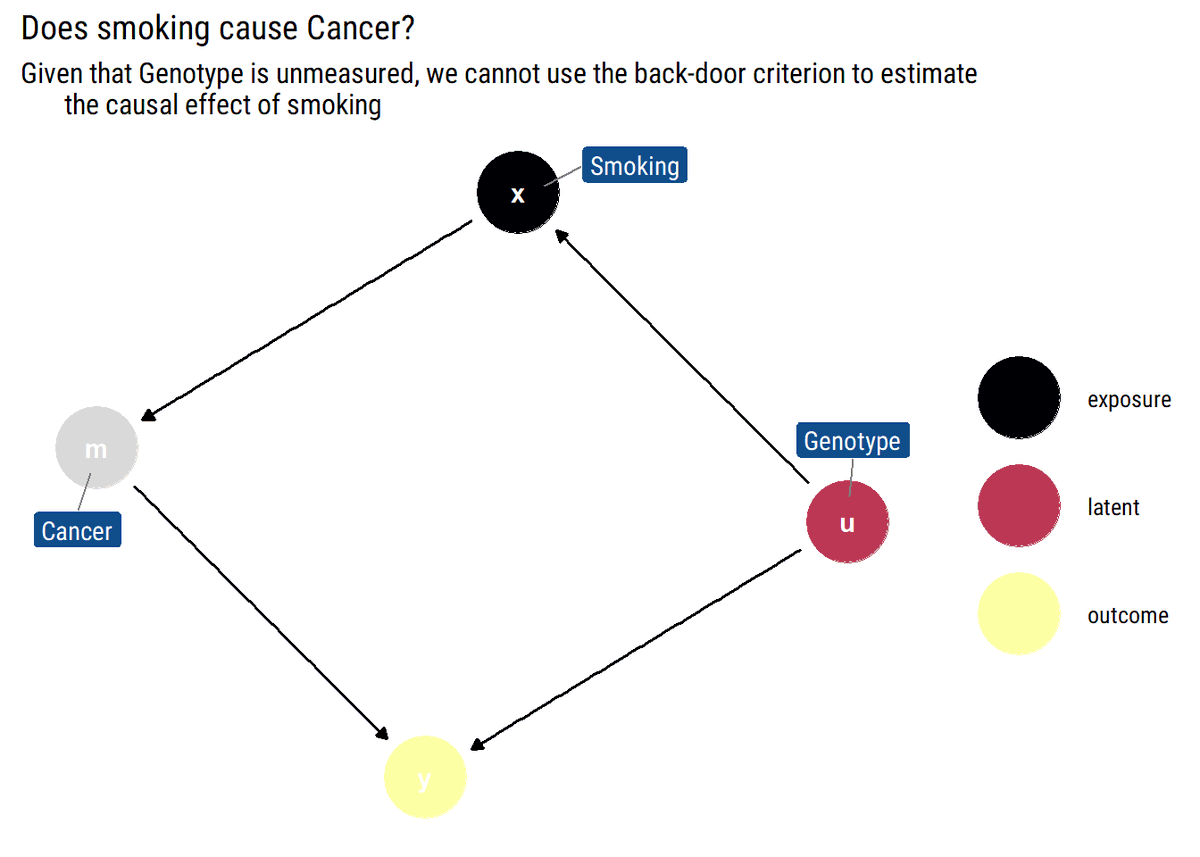
Chain: addictive behavior→smoking→cancer. If we adjust by a particular level of smoking (as in the figure below), knowing the addictive behavior of someone tells us nothing about the probability that they have cancer: the level of smoking says it all already.
Chain: addictive behavior→smoking→cancer. If we adjust by a particular level of smoking (as in the figure below), knowing the addictive behavior of someone tells us nothing about the probability that they have cancer: the level of smoking says it all already.
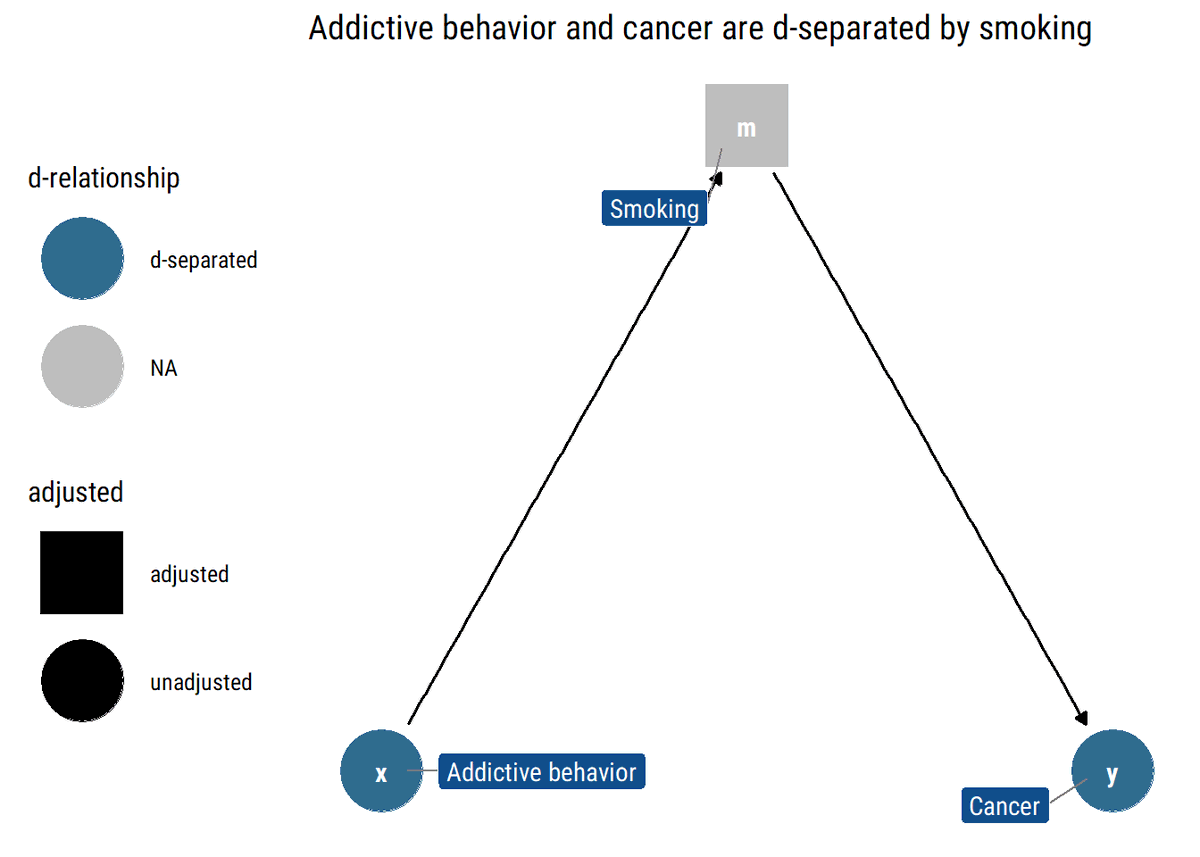
6/N
Forks: smoking←addictive behavior→drinking coffee. If we adjust by a specific value of addictive behavior (as in the figure below), drinking coffee does not say anything about smoking, the value of addictive behavior has said it all already.
Forks: smoking←addictive behavior→drinking coffee. If we adjust by a specific value of addictive behavior (as in the figure below), drinking coffee does not say anything about smoking, the value of addictive behavior has said it all already.
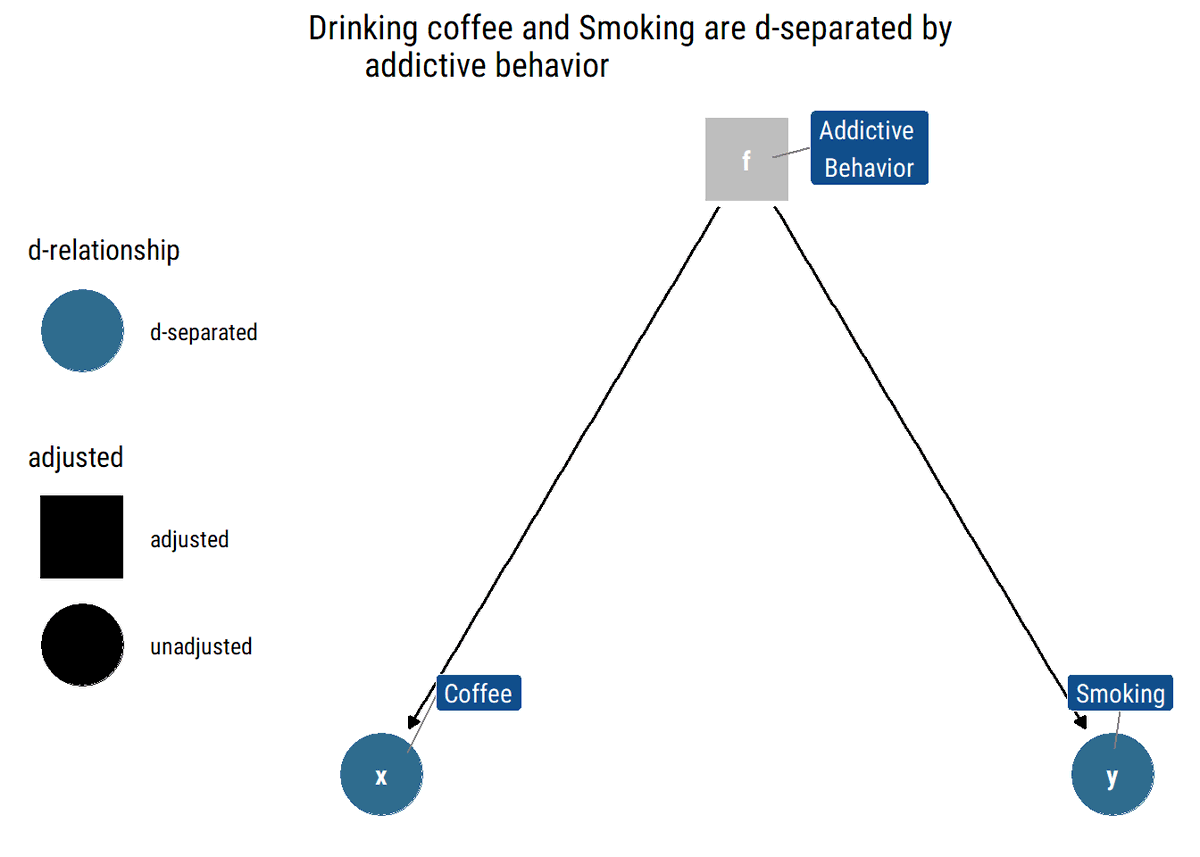
7/N Finally, a collider path: talented→is Hollywood actor←attractive. Being attractive and being talented are independent;once we know whether someone is a Hollywood and is not talented, we know he must be attractive.The path is closed unless we adjust by middle variable
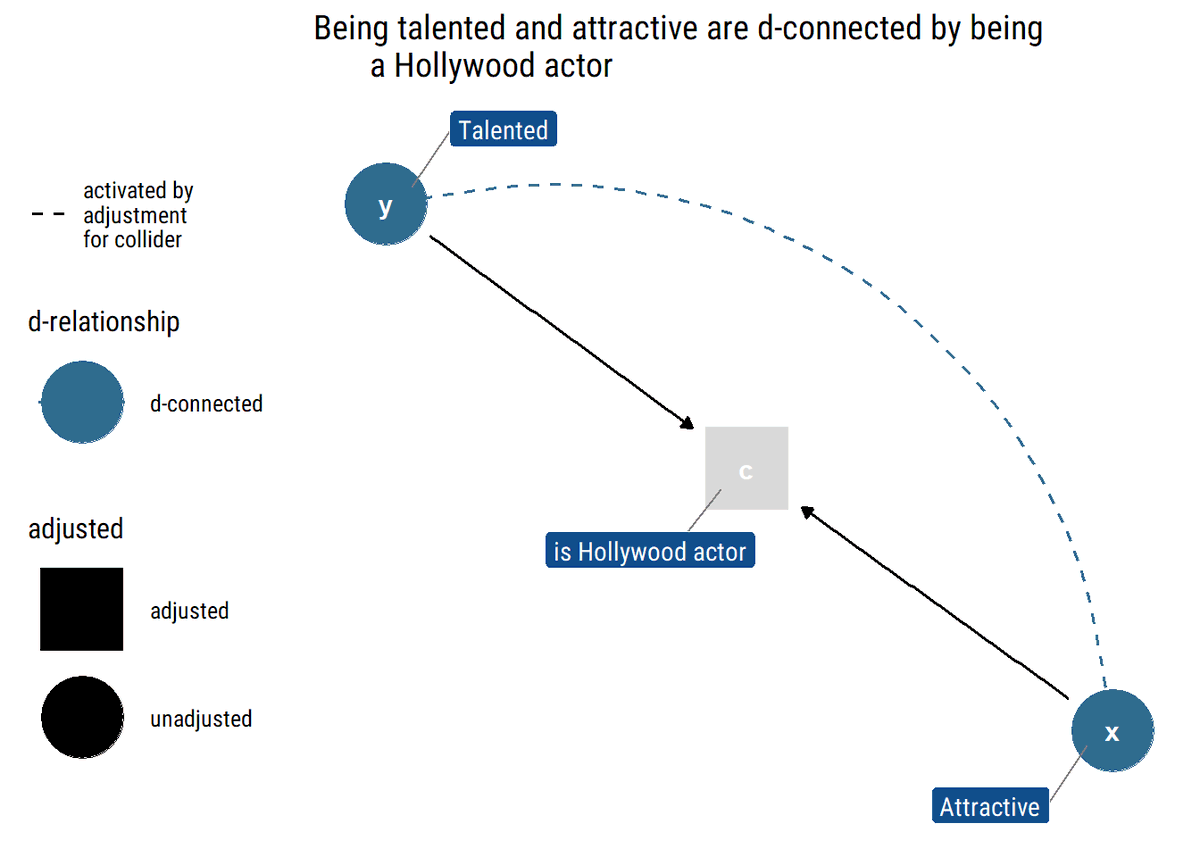
8/N d-separation criterion: X and Y are independent conditional on Z; if there's a fork or a chain, the middle variable must be Z; if there's a collider, the middle variable cannot be Z. By analyzing every pair of variables, we derive the implied independencies of our model

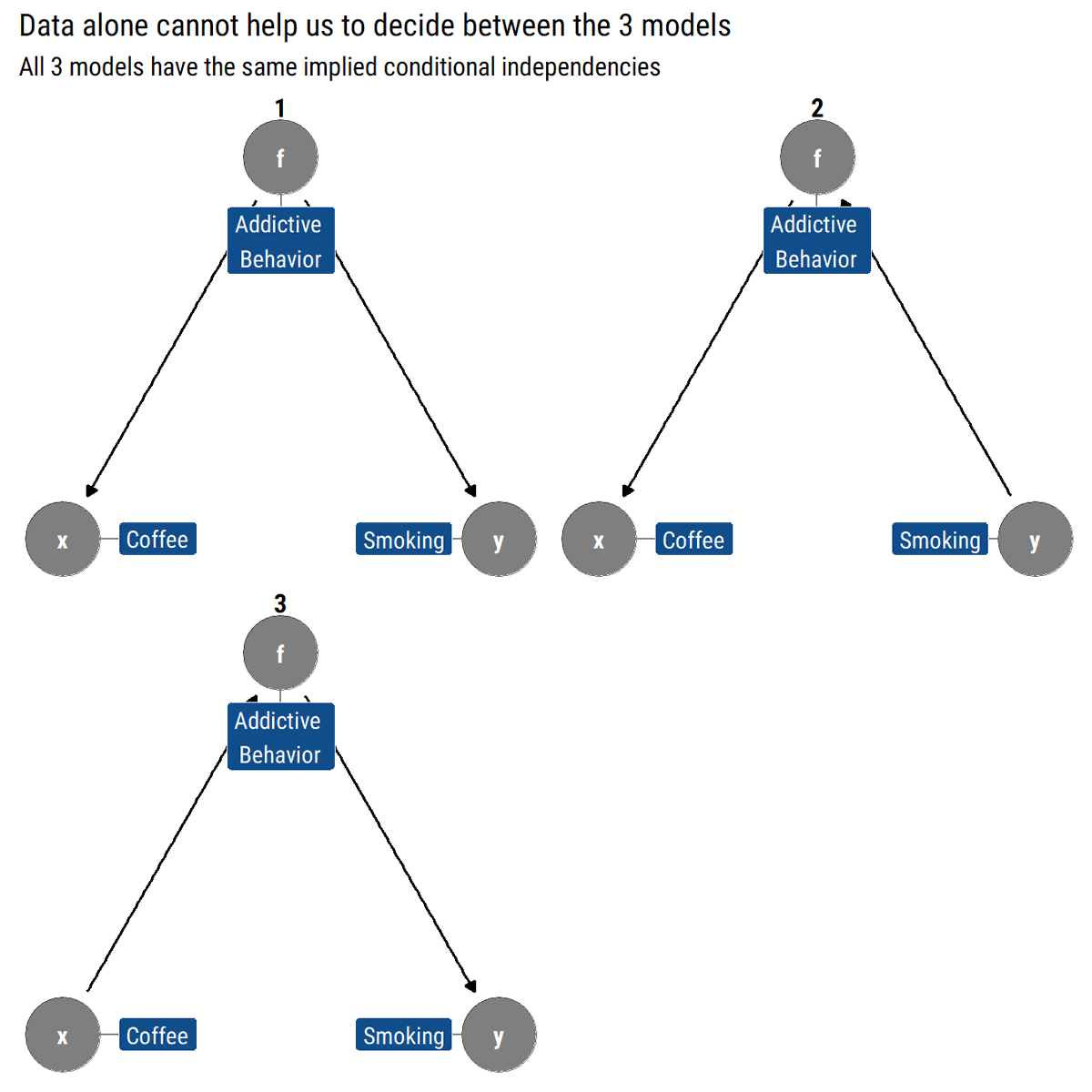
9/N Thus, by modeling a joint probability with a graph, we can algorithmically derive the testable implications. If two graphs have the same implications, they cannot be distinguished from data alone. Sadly, a fork or a chain (in either direction) are observationally equivalent.
10/N That is, we cannot predict the consequences of intervening in one of the variables with only observational data. That is, we cannot gain causal understanding with only observational data: we must assume a causal model to predict the the consequences of any intervention
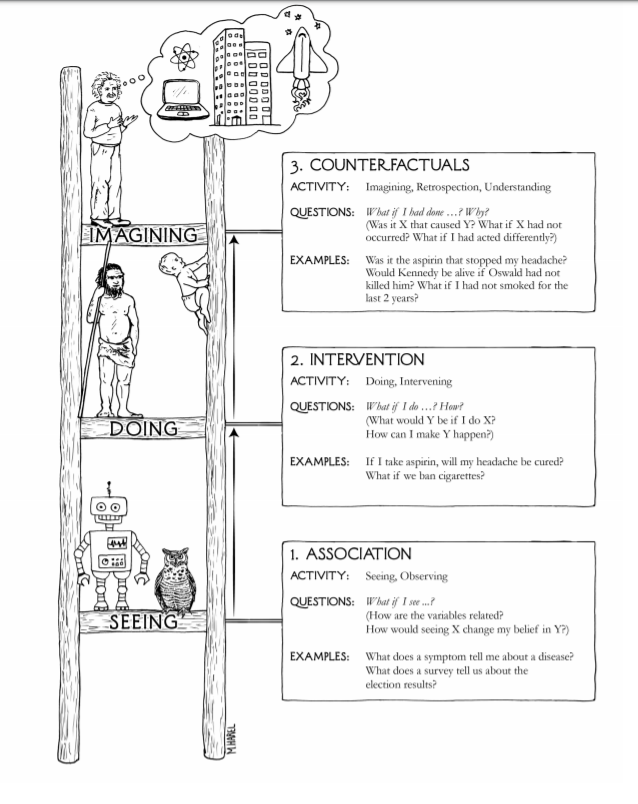
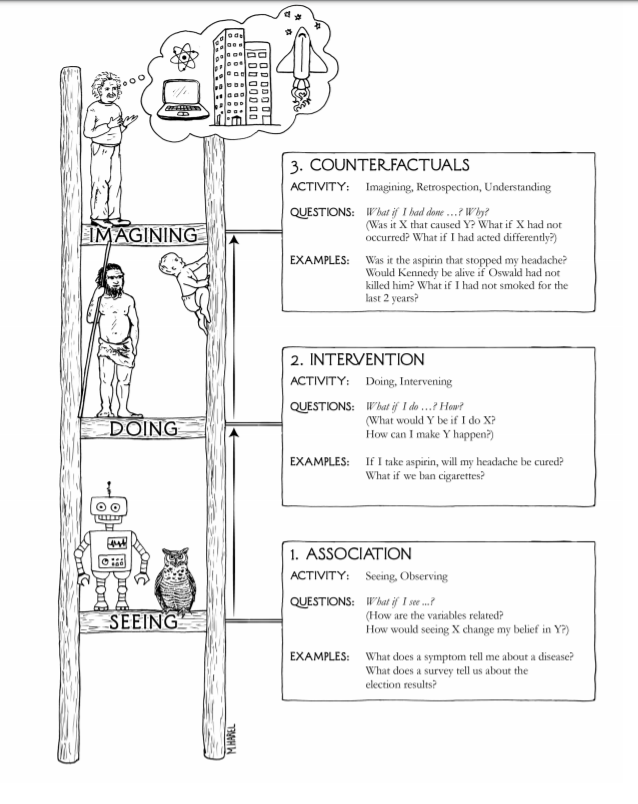
More generally, Pearl formulates the ladder of Causation. @eliasbareinboim (et al) states the Causal Hierarchy Theorem: data from one rung always undetermines information from higher rungs. Thus, we cannot gain causal understanding from data alone.
New post! If data alone does not yield causal insights, what does? A causal story, the do-operator and the interventional distribution as a mutilated Causal Graph. How can we connect pre-intervention and post-intervention distributions? RCTs and more...
david-salazar.github.io/2020/07/22/cau…
david-salazar.github.io/2020/07/22/cau…
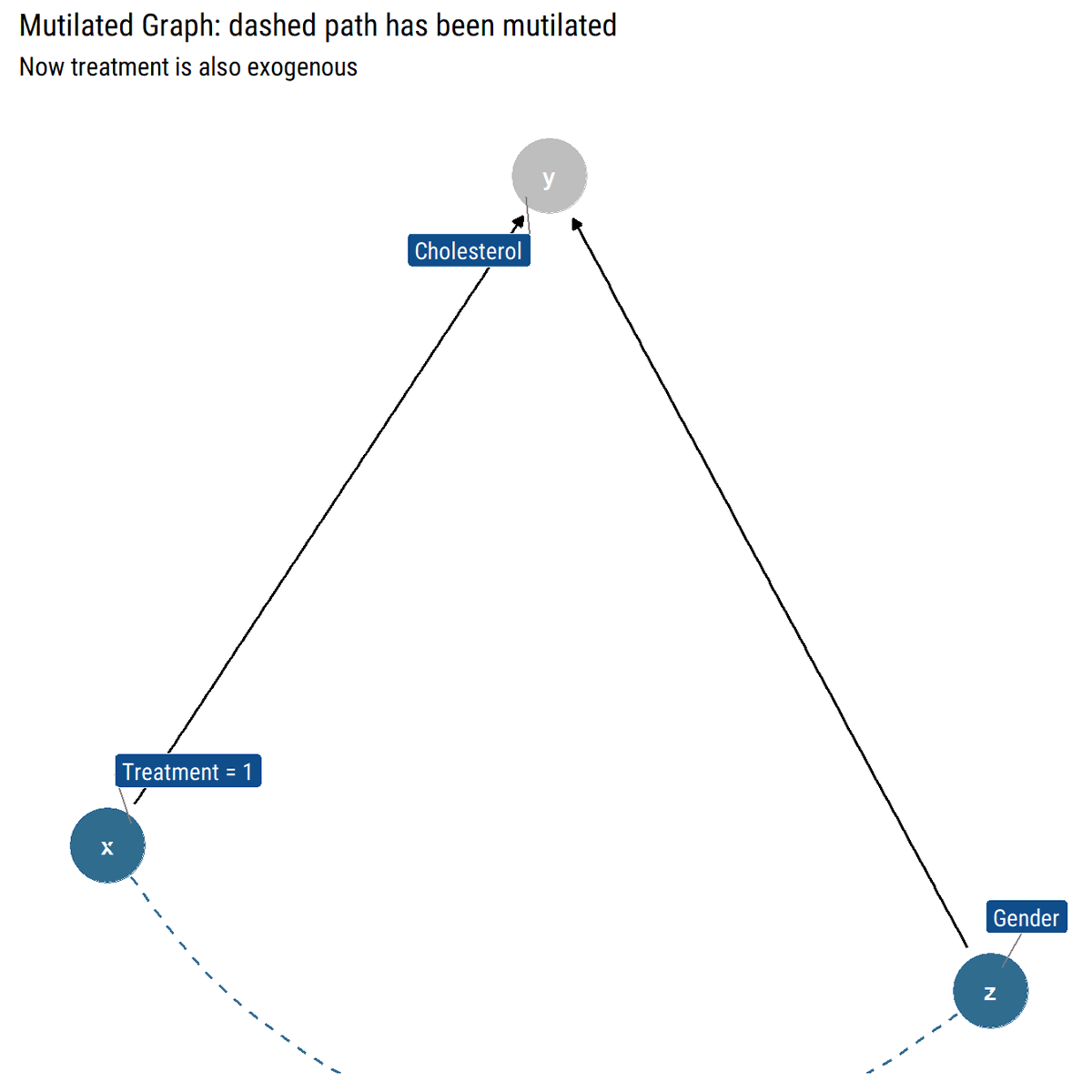
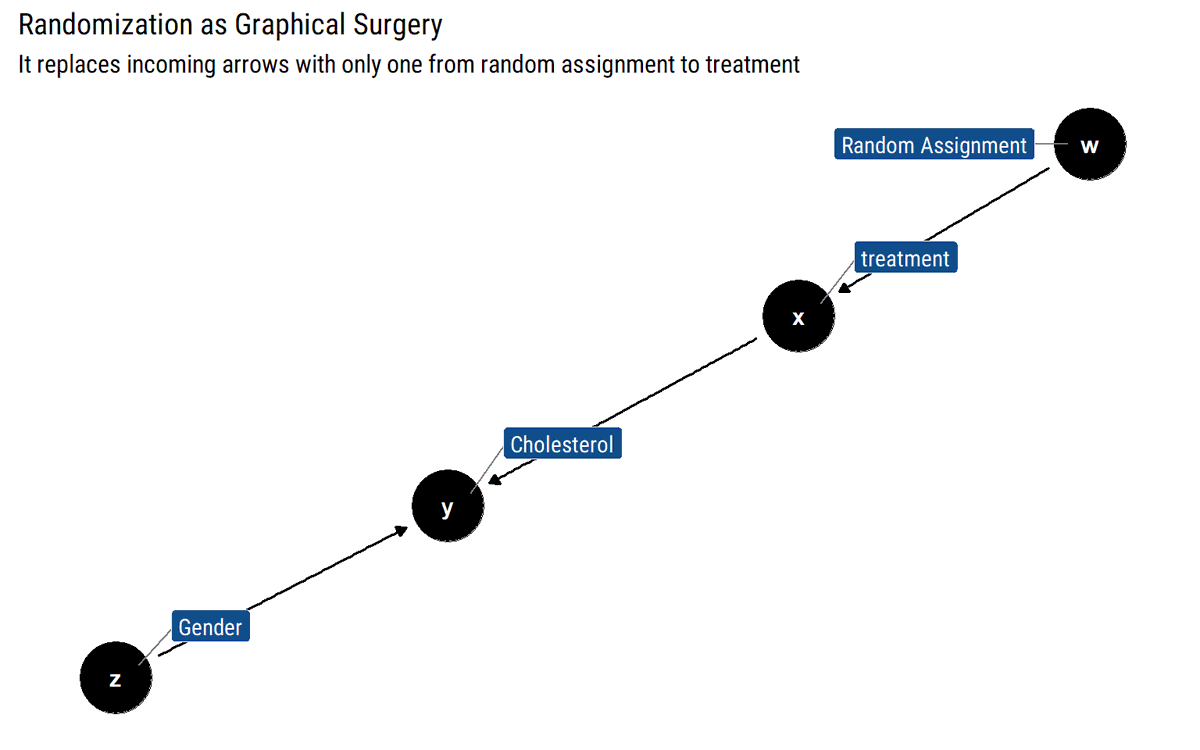
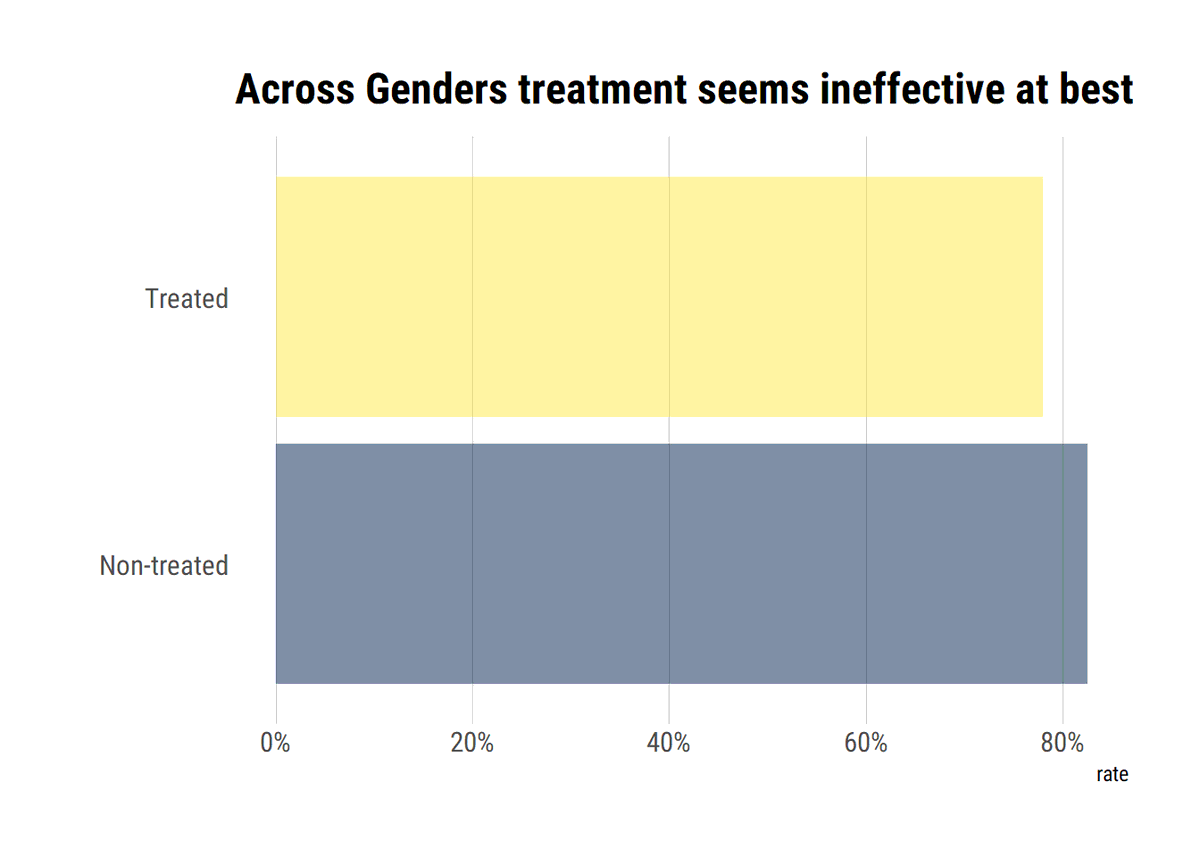
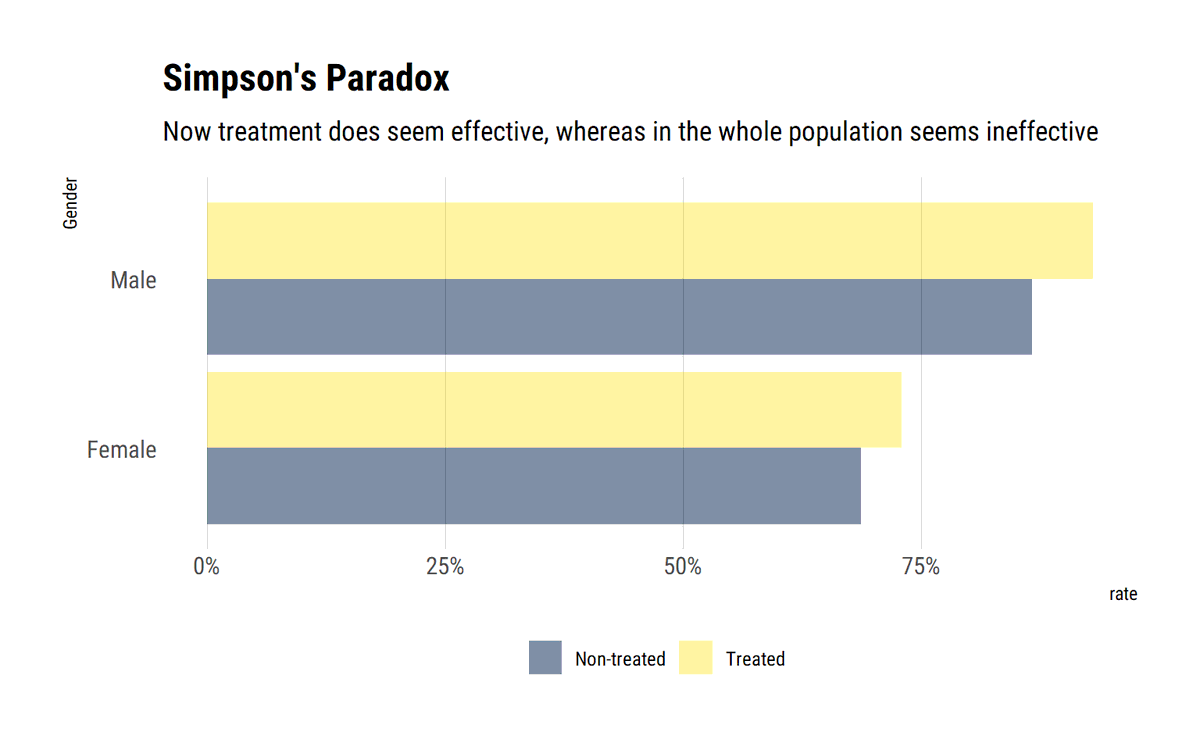
Following @yudapearl's interventional position, the do-Operator in the Causal Graph amounts to curtailing the previous mechanism that defined X by eliminating the incoming arrows into X. In turn, this causal graph defines a post-intervention distribution that defines ATE.
As @yudapearl says, it is by leveraging the invariant relationships under intervention that we can use observational data to estimate causal effects. It's more than simple deconfounding. Thus, we arrive at the Adjustment Formula:

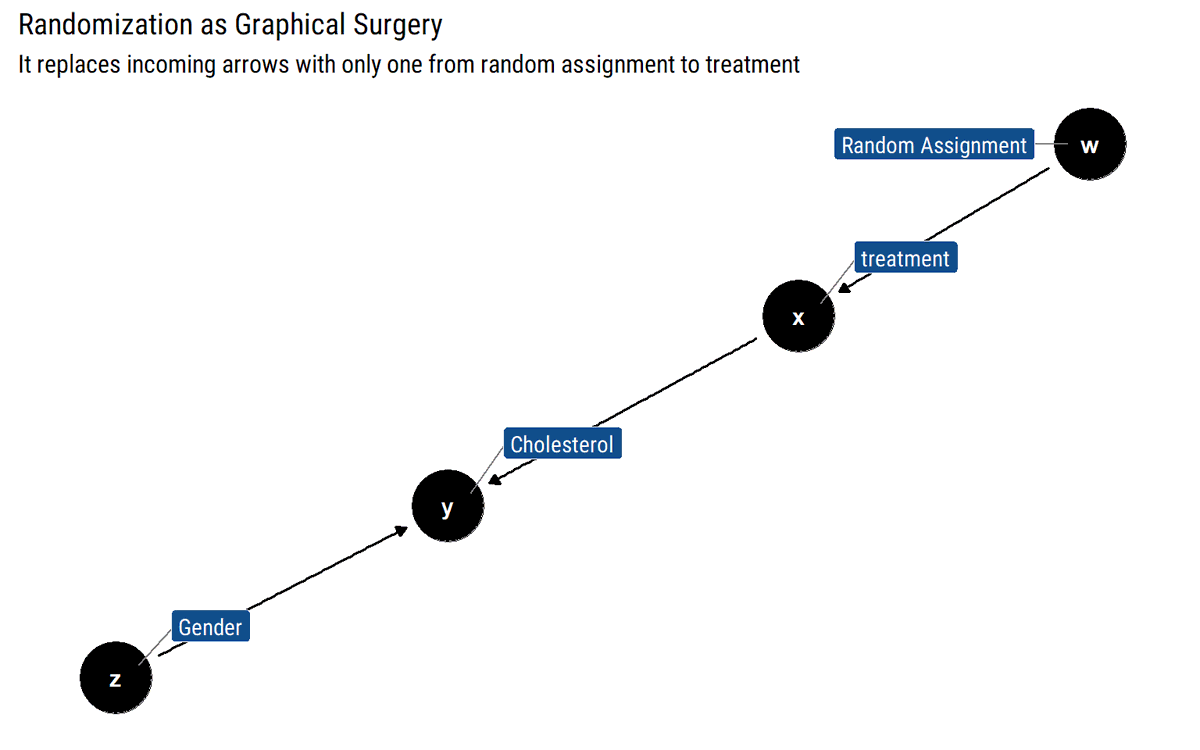
Interestingly, @yudapearl says that RCTs can be subsumed in this framework. Instead of cutting incoming arrows, they replace them with a single one from random assignment. Not a gold-standard, just accounting for when we are uncertain about knowing all the parents of X
New📝! To adjust or not to adjust. Given a causal story, @yudapearl's graphical criterion demystifies controlling on observables: does it de-confound or confound even more? Examples with Monte-Carlo simulations⬇️
twitter🧵
blogpost
david-salazar.github.io/2020/07/25/cau…
twitter🧵
blogpost
david-salazar.github.io/2020/07/25/cau…
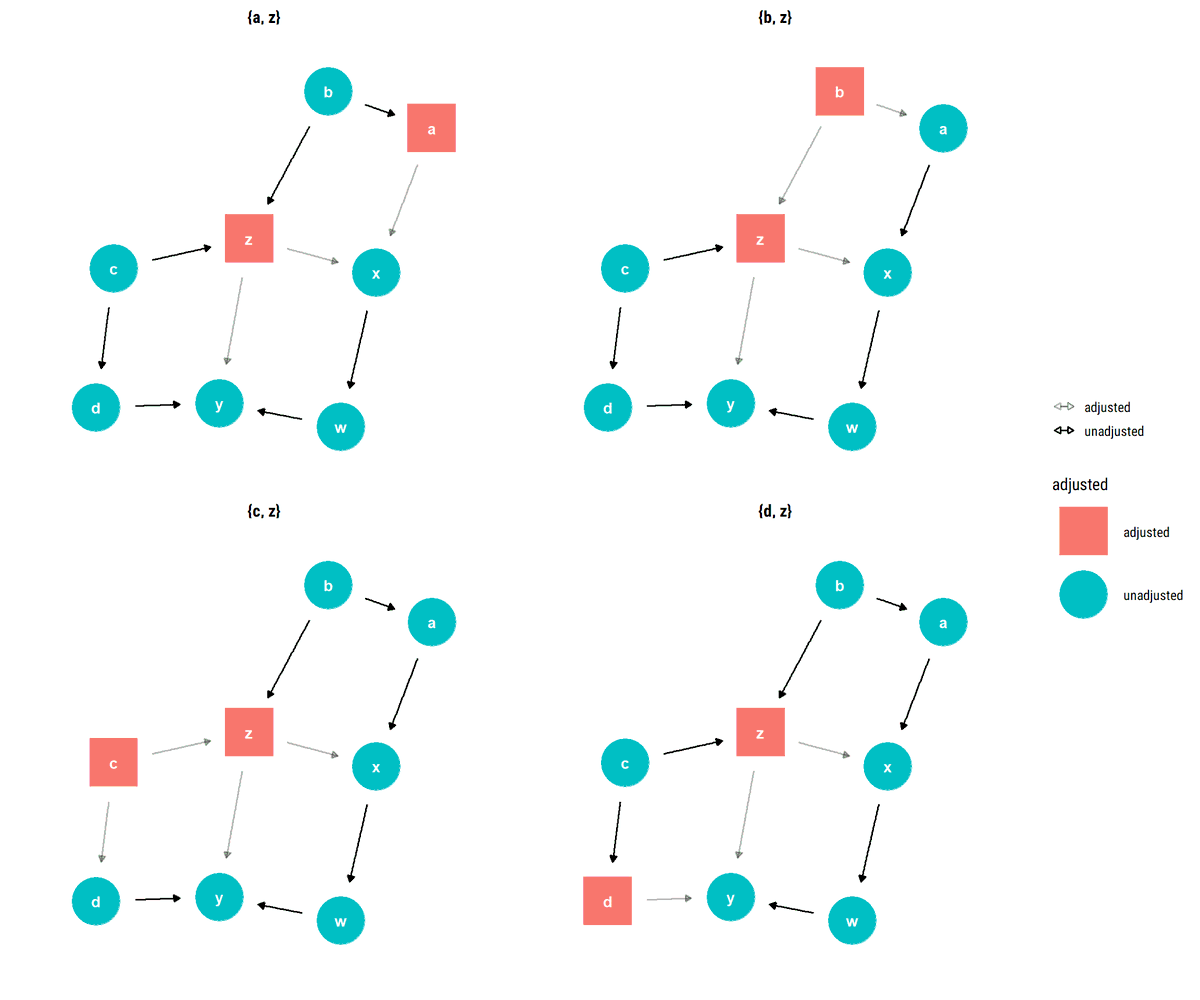
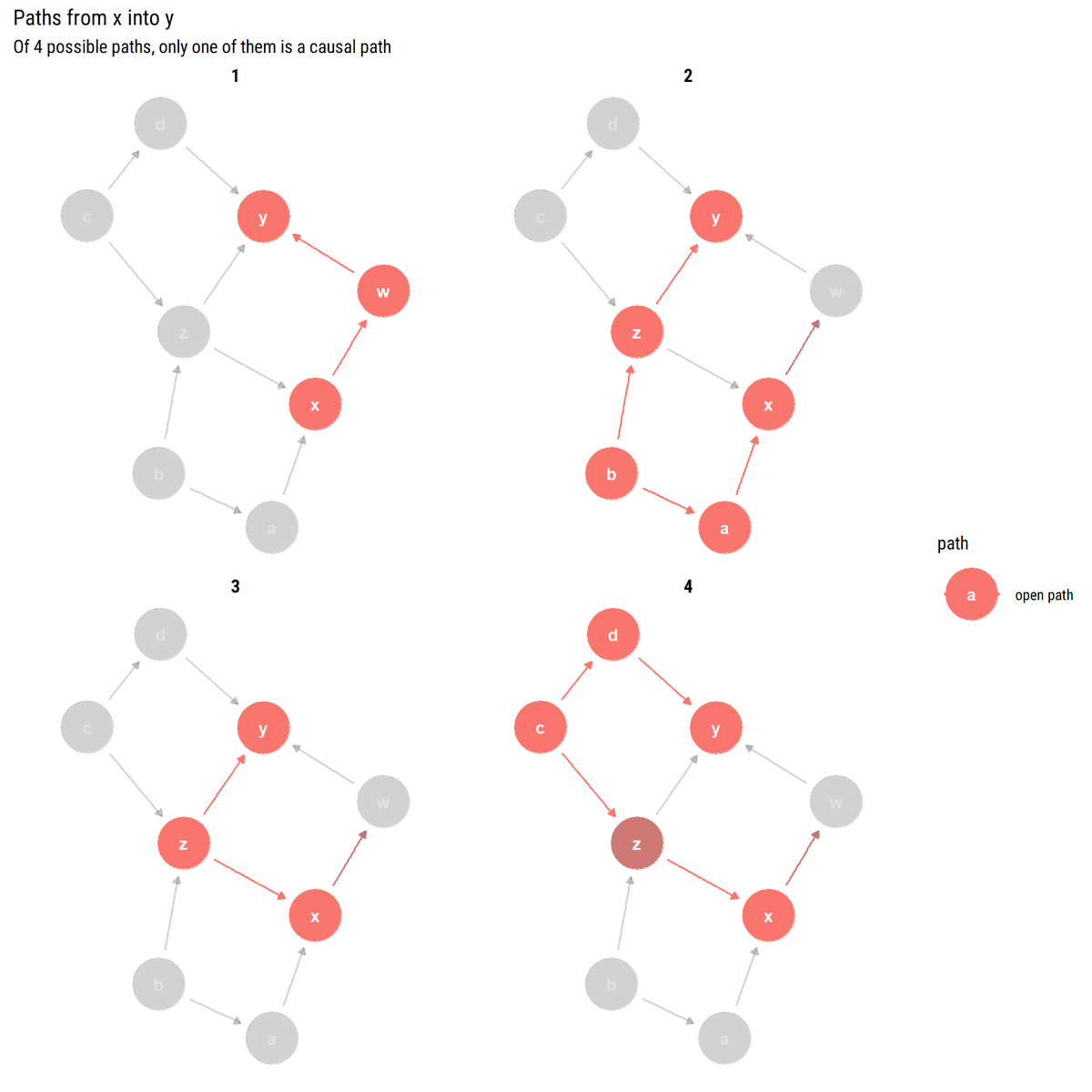
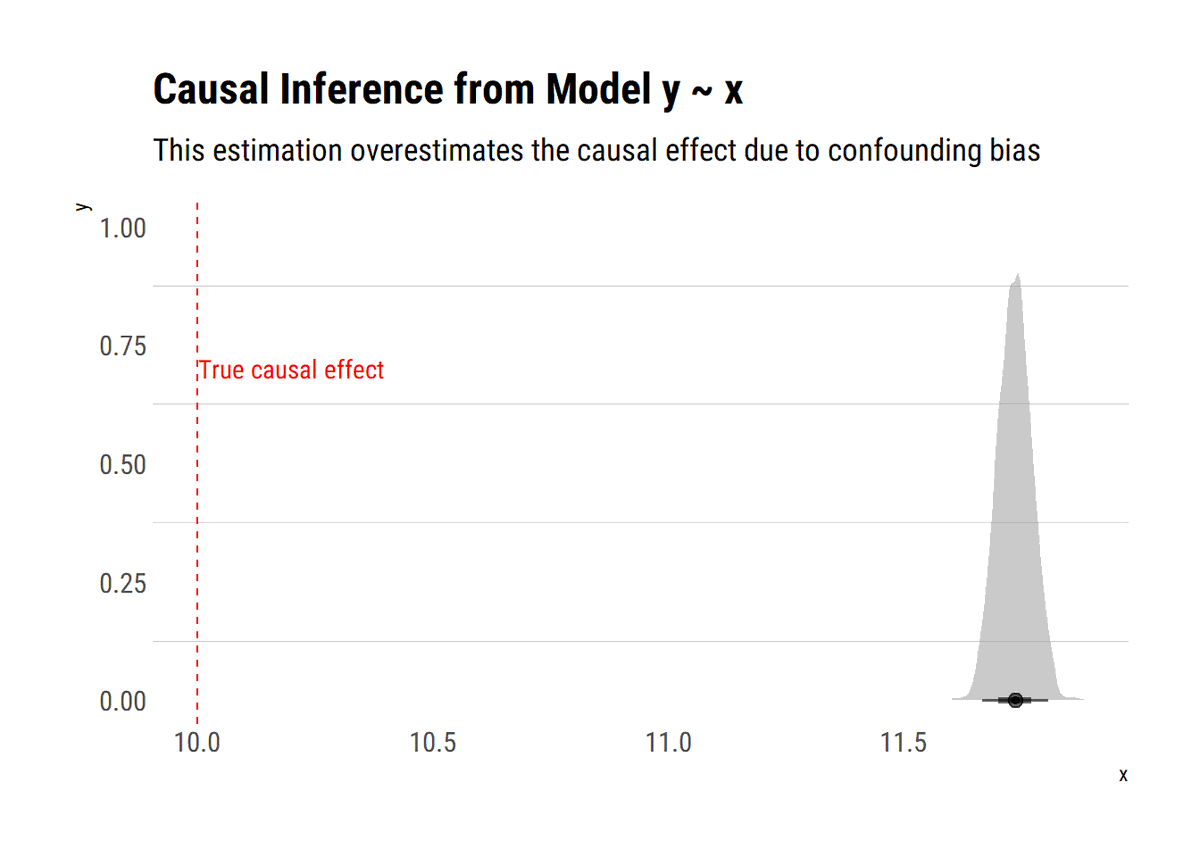
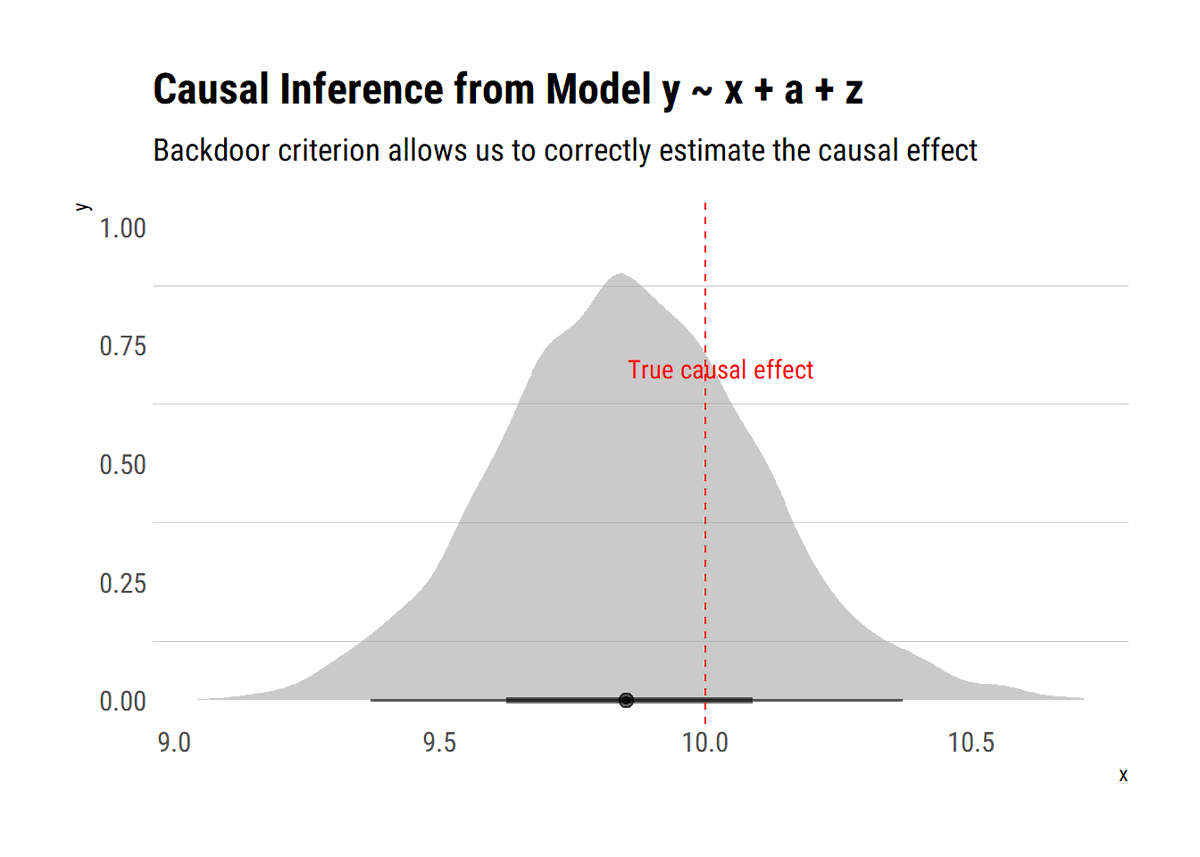
New📝! When the back-door fails to block, @yudapearl says to exploit the variation in the mechanism through which X causes Y: the Front-Door Criterion. How to do it? What are the assumptions? Monte-Carlo experiments and more⬇️
#rstats
blog:
david-salazar.github.io/2020/07/30/cau…
#rstats
blog:
david-salazar.github.io/2020/07/30/cau…
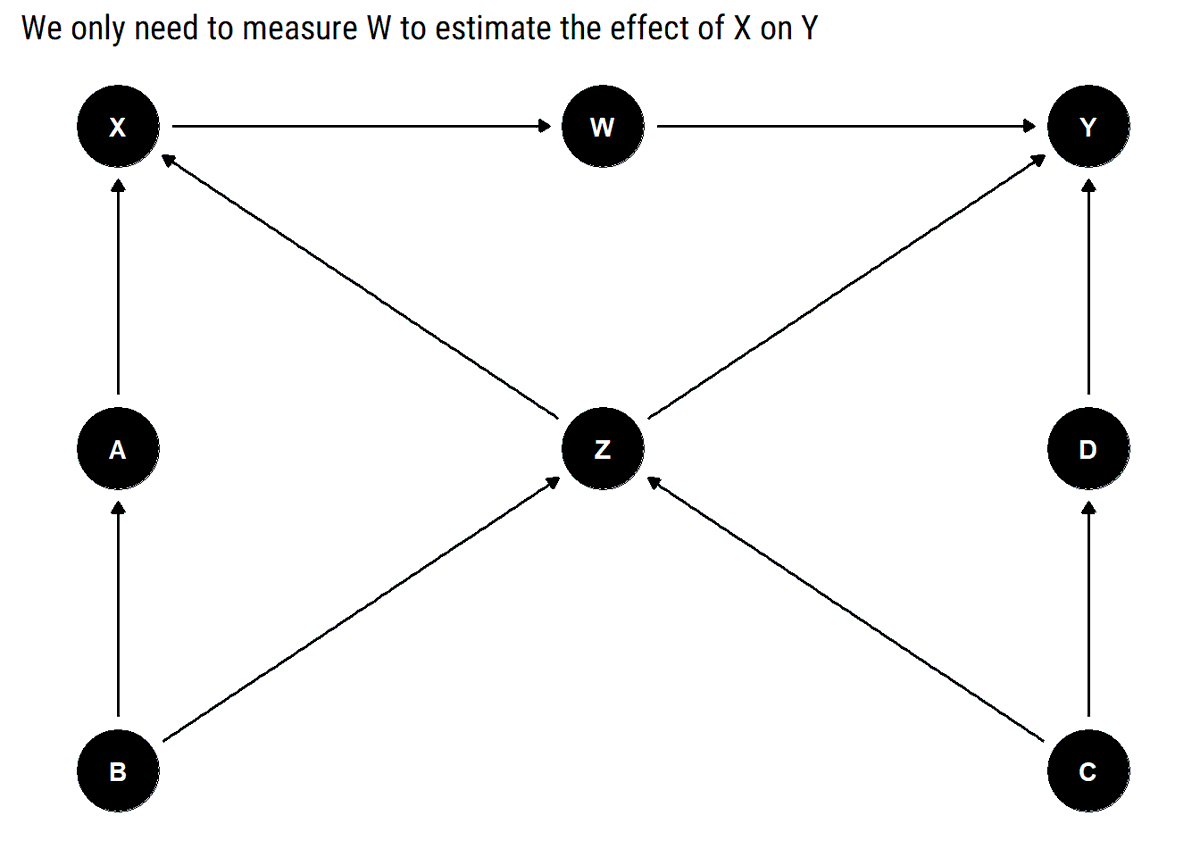
How to estimate X ➡️Y in the dag below with only one variable? We can repeatedly use the back-door criterion to estimate two partial effects: X➡️W and W➡️Y. By chaining them, we estimate the overall effect of X #rstats
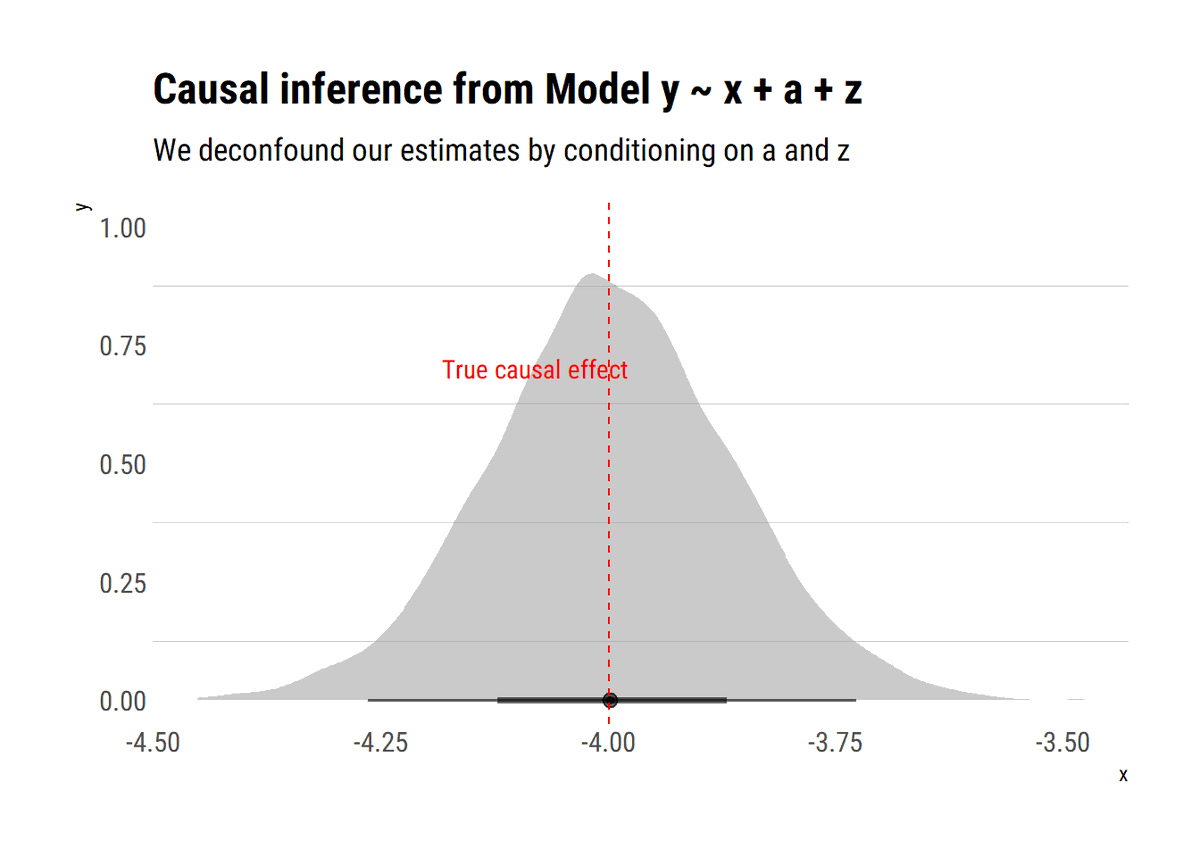
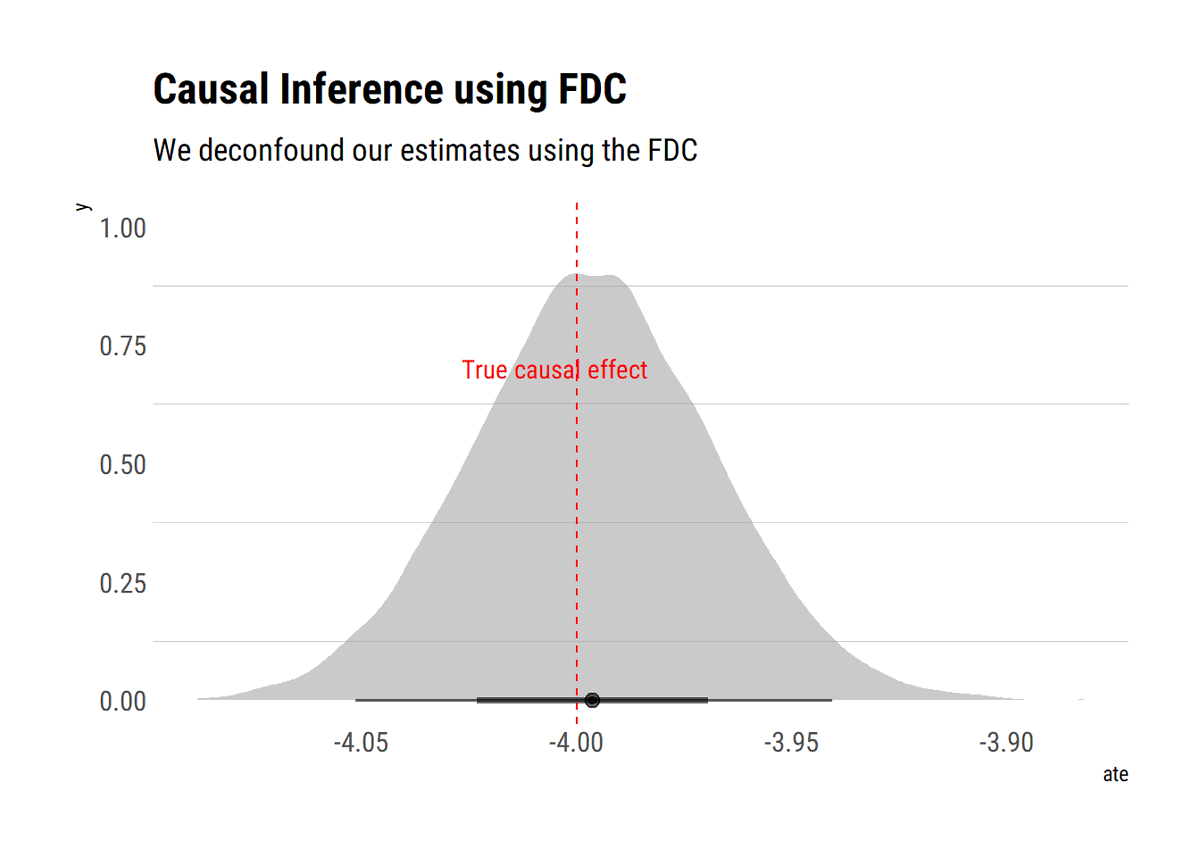
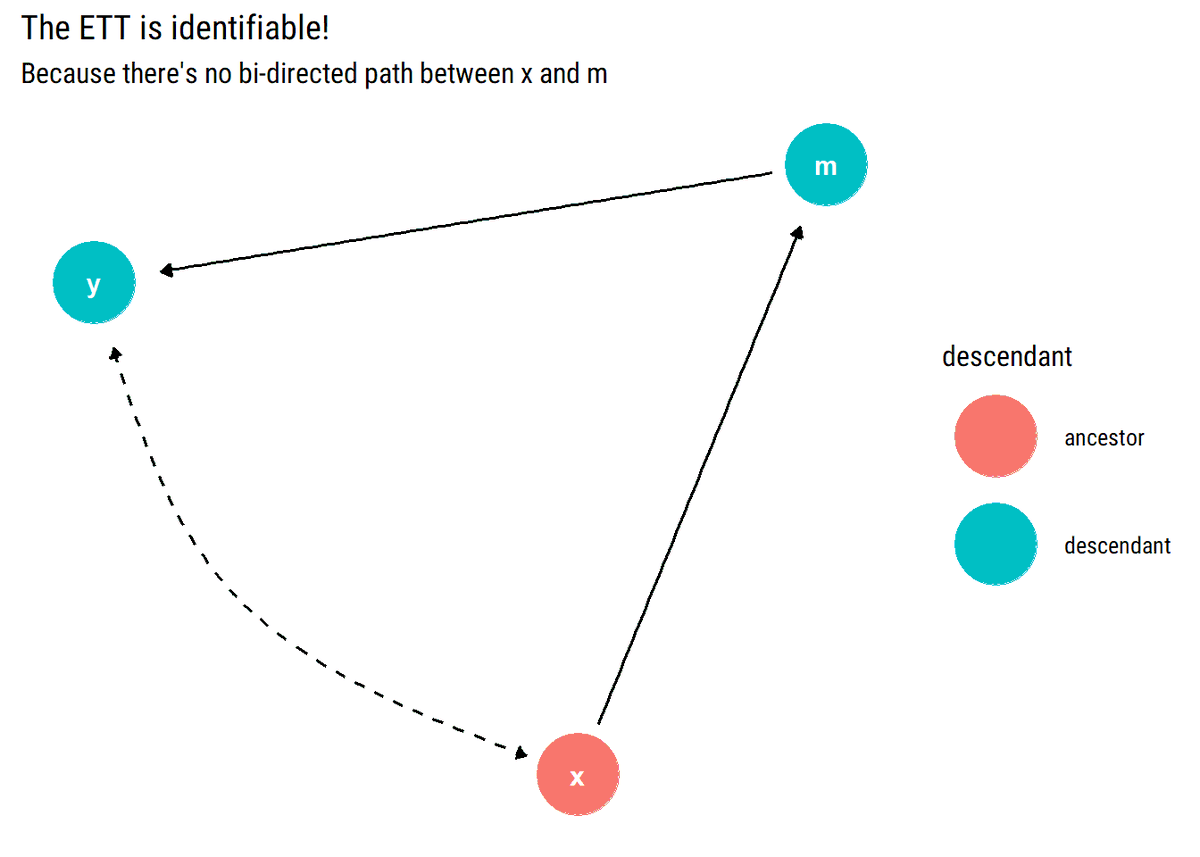
New📝Hidden common causes can derail our identification strategies. Exploiting the c-components that the hidden common causes define, @yudapearl's (et al) sufficient graphical test for identifiability: no bi-directed path between X and its descendants
david-salazar.github.io/2020/07/31/cau…
david-salazar.github.io/2020/07/31/cau…
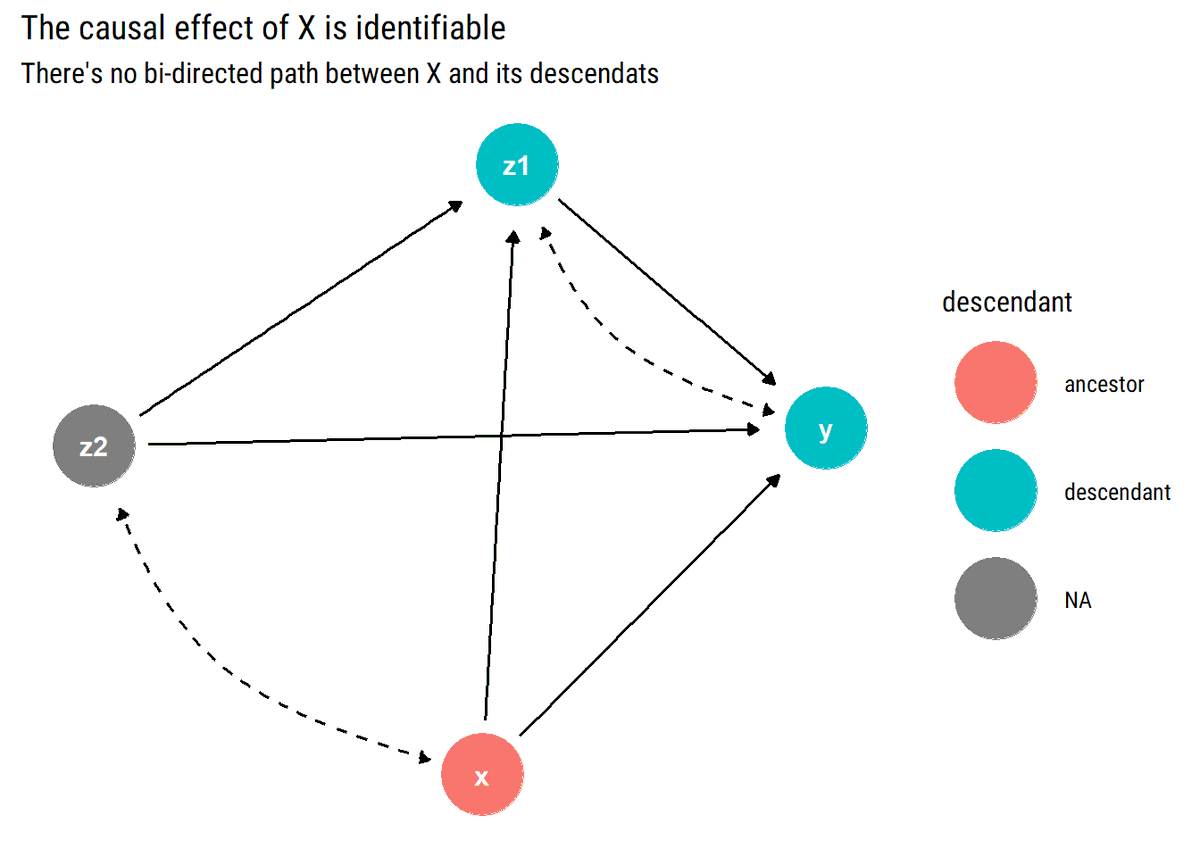
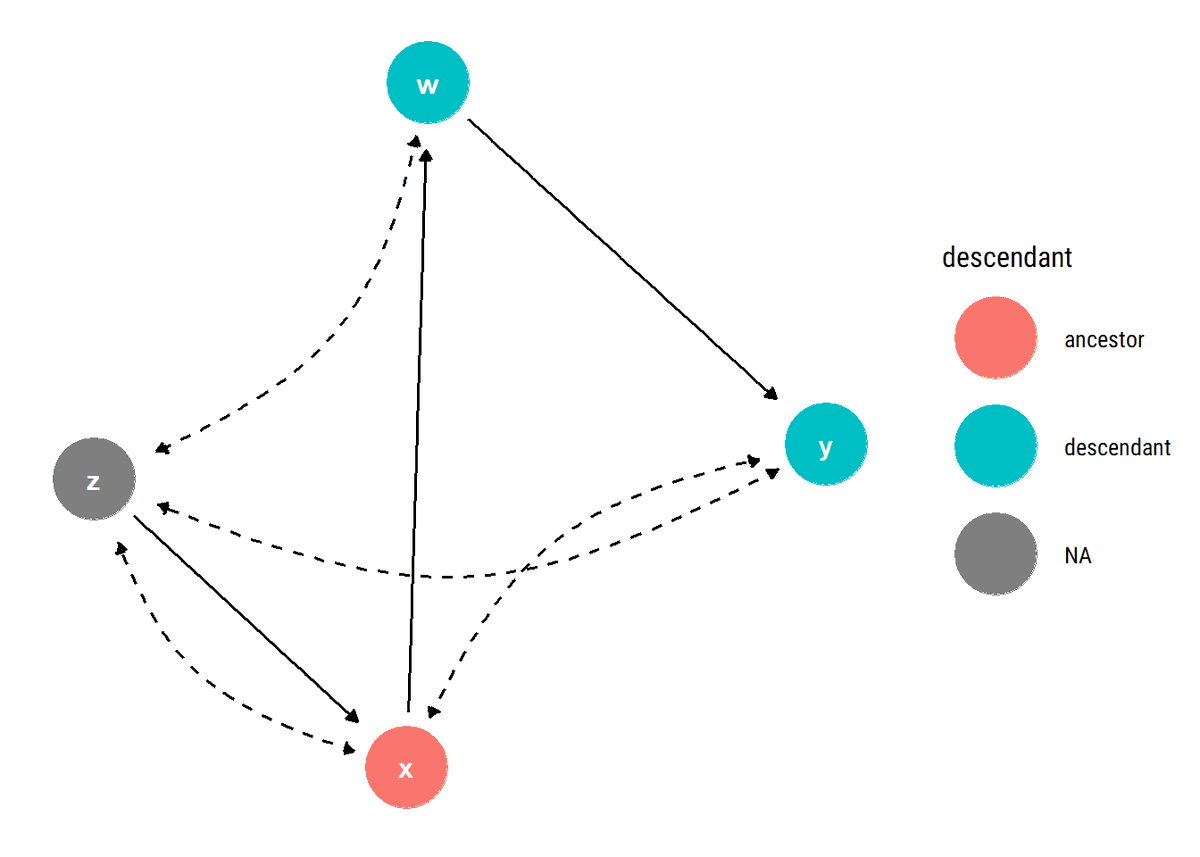
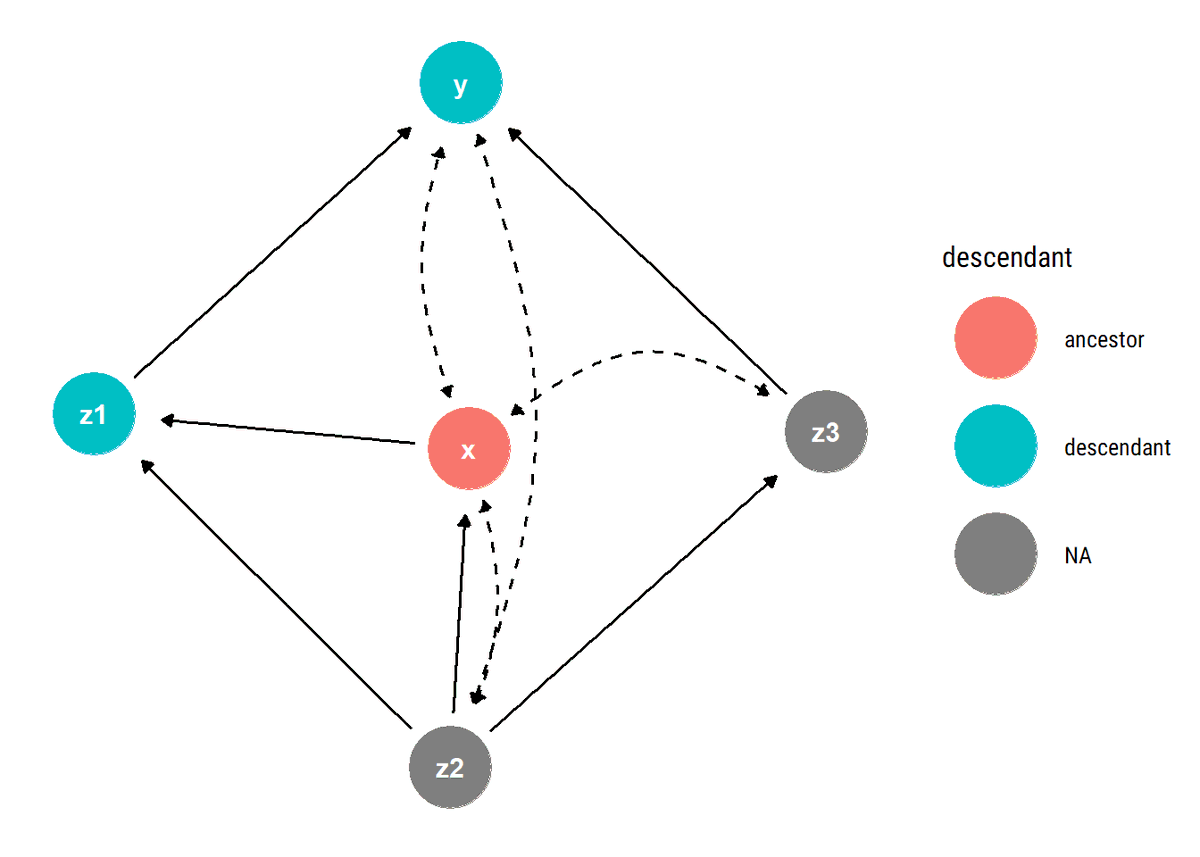
What is the intuition of our identifiability test? The key to identifiability lies not in blocking back-door paths between X and Y but, rather, in blocking back-door paths between X and any of its descendants that is also an ancestor of Y.
📝What if Frost hadn't taken the road less traveled? @yudapearl says that no RCT can solve contradiction between counterfactual's antecedent & observed world. Instead we route impact of known facts thru invariant info across worlds: background vars in SCM
david-salazar.github.io/2020/08/10/cau…
david-salazar.github.io/2020/08/10/cau…

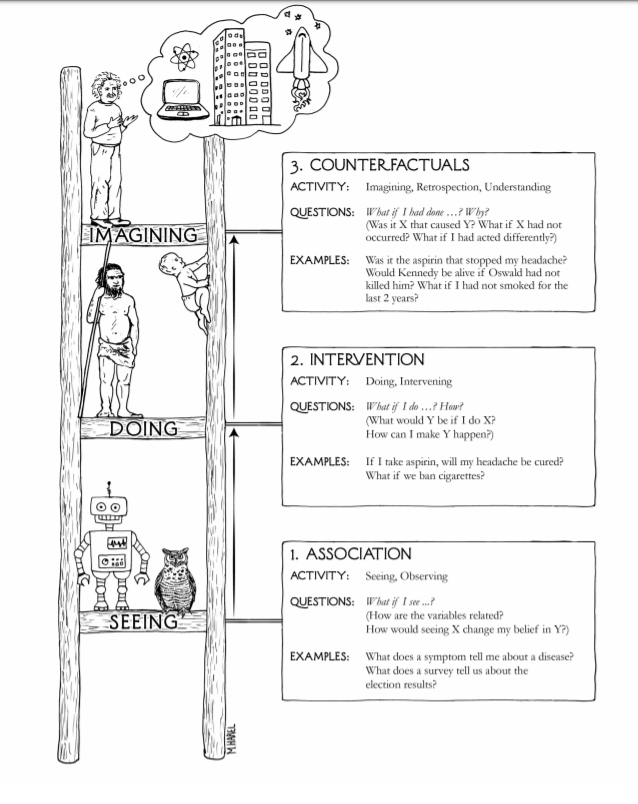
Thus, @yudapearl's ladder of causality. Just as many causal dags can't be distinguished with observational data, many SCMs imply the same interventional data. Prediction, intervention and counterfactuals form a hierarchy, each rung requiring more elaborate causal assumptions.
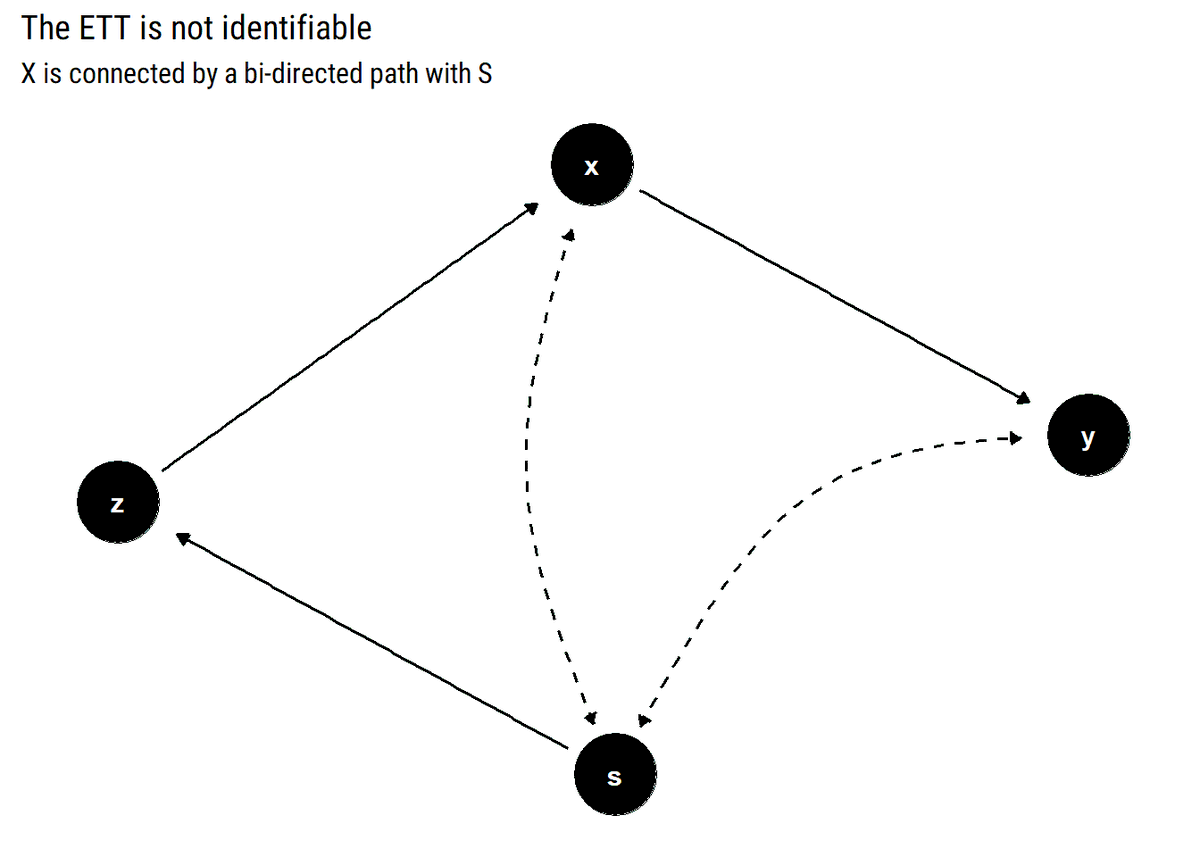
@yudapearl New📝Effect of Treatment on the Treated is a counterfactual that defies experimental evidence. By leveraging the restrictions and invariances in a causal model, @yudapearl & Shipster show that c-components are the key to identification and estimation.
david-salazar.github.io/2020/08/16/cau…
david-salazar.github.io/2020/08/16/cau…
@yudapearl New📝How can we attribute an effect to a cause? With high Probabilities of Necessity and Sufficiency. By giving them a counterfactual interpretation, @yudapearl derives sharp bounds that collapse to a point estimate under monotonicity #rstats
Blogpost:
david-salazar.github.io/2020/08/20/cau…
Blogpost:
david-salazar.github.io/2020/08/20/cau…


Mediation analysis aims to go beyond the initial Why?: i.e., disentangle direct and indirect effects (portion that passes through mediator). By giving them counterfactual definitions, @yudapearl guides us through identification and estimation.
#rstats
david-salazar.github.io/2020/08/26/cau…
#rstats
david-salazar.github.io/2020/08/26/cau…
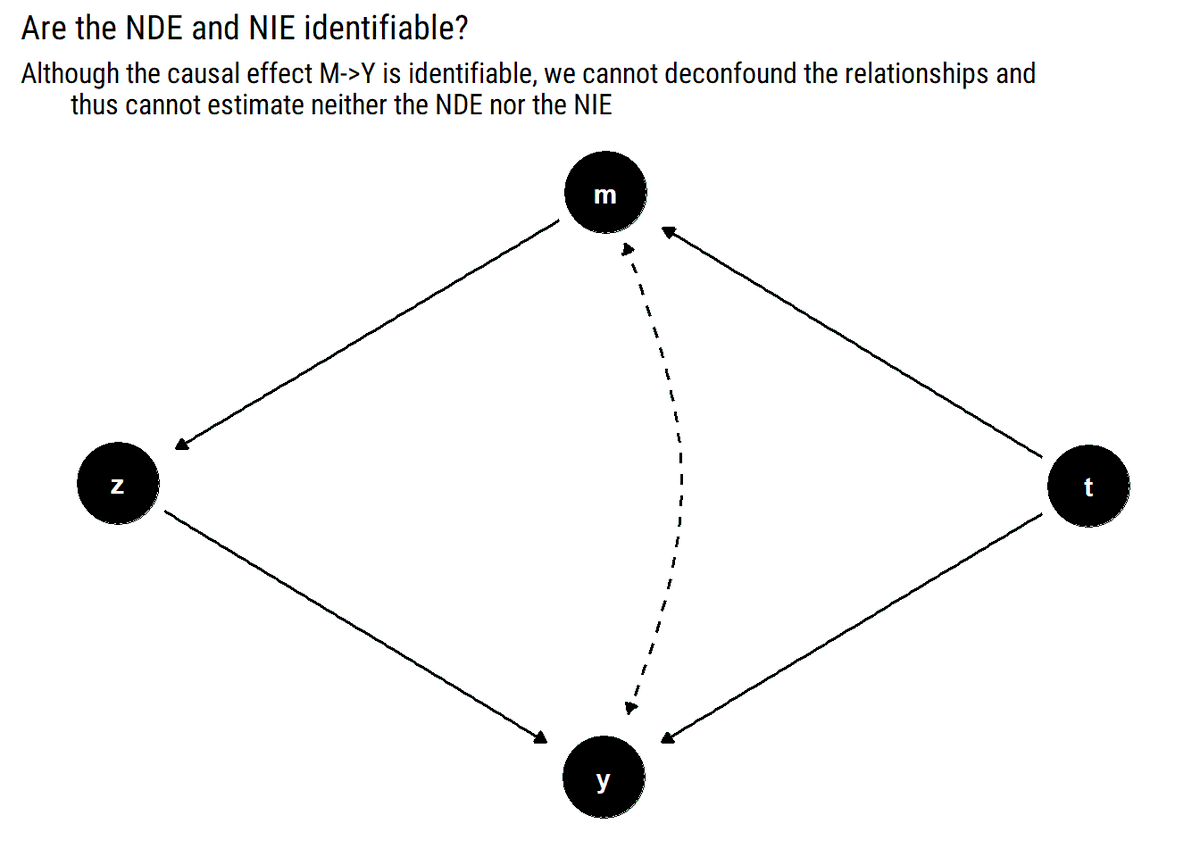
e.g., take the following example from @yudapearl (DAG below). Although the causal effects are identifiable, the Natural Direct Effect isn't. This is another example of the ladder of causation and @eliasbareinboim's CLT: experimental evidence undetermines counterfactual info
This completes my first serious look into causality. @yudapearl's fundamental point: no worthwhile insight can be gained without combining data with substantive knowledge in the form of assumptions. DAGs are the most intuitive way to state these assumptions.
@yudapearl's Ladder of Causation is a great and intuitive way of showing how one's prior knowledge (and the assumptions that encode them) must grow with the difficulty of one's task: prediction < intervention < counterfactual. Is then Data Science currently lost, then?
The most important insight I gained from @yudapearl's work? The importance of leveraging invariances. Whether the question is about causal effects or counterfactuals, they always imply change: only by leveraging what's constant across change, we can answer these questions.
Overall, @yudapearl's optimism can seem a bit callow. Yes, encoding one's assumption as clearly as possible is the first step towards having an informed discussion. I don't know if there will be a second step in the areas where DAGs shine the most: i.e., not the sciences.
As @rlmcelreath says, physics does not need DAGs. Macroeconomics, even with DAGs, cannot gain interventional knowledge. It puts DAGs in an awkward place: hard sciences don't need them; whoever is left either does not care about CI or cannot possibly gain the knowledge to climb 🪜