
[#Fuzzing Evaluation] How do we know which fuzzer finds the largest number of important bugs within a reasonable time in software that we care about?
A commentary on @gamozolabs' perspective.
(Verdict: Strong accept).
A commentary on @gamozolabs' perspective.
(Verdict: Strong accept).
YES! We need to present our plots on a log-x-scale. Why? mboehme.github.io/paper/FSE20.Em…
Two fuzzers. Both achieve the same coverage eventually. Yet, one performs really well at the beginning while the other performs really well in the long run. (What is a reasonable time budget? 🤔)
Two fuzzers. Both achieve the same coverage eventually. Yet, one performs really well at the beginning while the other performs really well in the long run. (What is a reasonable time budget? 🤔)
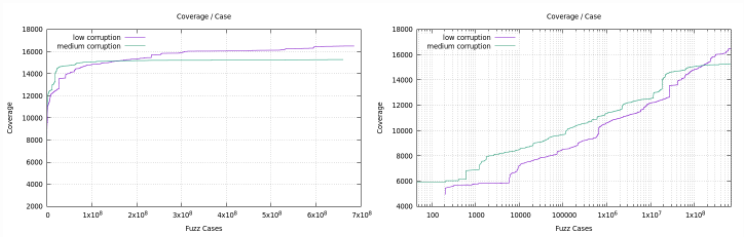
Nice! I agree, comparing *time-to-same-coverage* provides more information about fuzzer efficiency than comparing coverage-at-a-given-time.

On a log-x-scale, you might be able to see convergence. You can confidently extrapolate by one or two orders of magnitude. Running the campaign 10 days or 100 days instead of 1 day is not practical, though.
In papers, we should prefer coverage plots over tables.
In papers, we should prefer coverage plots over tables.

Excellent point! This is part of the answer for "How do we compare techniques instead of their implementations?"
(More on that in my talk at #FuzzConEurope2020).
(More on that in my talk at #FuzzConEurope2020).

I agree, scalability is an important property of a fuzzer, but it is "orthogonal" to other properties. E.g., if I work on a power schedule, I could compare my schedule against the baseline on a single core & assume perfect scaling. Scaling is an independent research question.

I fully agree that we should study all kinds of fuzzer properties. The problem with subject-specific fuzzers is that you can't just throw them on the next random subject. It's like trying to build a custom car for everyone who needs a car. It would just not be scalable/practical.

In summary, go read @gamozolabs' blog post!
The FuzzBench team has been doing an awesome job! For them, there are some nice feature requests (e.g., use default log-x-scale, report coverage over fuzz cases, evaluate scalability). For us, fuzzer evaluation is an open challenge.
The FuzzBench team has been doing an awesome job! For them, there are some nice feature requests (e.g., use default log-x-scale, report coverage over fuzz cases, evaluate scalability). For us, fuzzer evaluation is an open challenge.
LibFuzzer, AFL++, and HonggFuzz went through major performance improvements -- enabled by FuzzBench.

(From the FuzzBench team via github.com/google/fuzzben…)



