
Software Security @maxplanckpress (#MPI_SP), PhD @NUSComputing, Dipl.-Inf. @TUDresden_de
Research Group: https://t.co/BRnFNNgynB
 Hacking culture in the 90's had very strong values. It had a value system outside of and different from normal society. Fuzzing was for the dumb kids.
Hacking culture in the 90's had very strong values. It had a value system outside of and different from normal society. Fuzzing was for the dumb kids.
 Whitebox fuzzing is most effective because it can, in principle, *prove* the absence of bugs.
Whitebox fuzzing is most effective because it can, in principle, *prove* the absence of bugs.
 More info about those two heuristics:
More info about those two heuristics:
 Motivation
Motivation
 It was tremendously exciting to get so many perspectives from so many junior and senior researchers across different disciplines. This was only a random curiosity of mine but it seemed to hit a nerve. I loved the positive, constructive tone in the thread.
It was tremendously exciting to get so many perspectives from so many junior and senior researchers across different disciplines. This was only a random curiosity of mine but it seemed to hit a nerve. I loved the positive, constructive tone in the thread.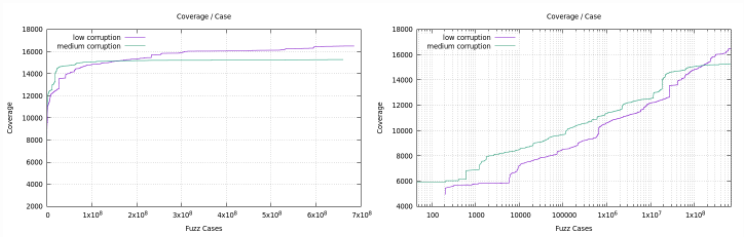
 In Chrome, libFuzzer found 4k bugs and 800 vulns. In OSS-Fuzz, libFuzzer found 2.4k bugs (AFL found 500 bugs) over the last three years.
In Chrome, libFuzzer found 4k bugs and 800 vulns. In OSS-Fuzz, libFuzzer found 2.4k bugs (AFL found 500 bugs) over the last three years.