Say you have a completly harmless virus (IFR=0) that can spread at R0=3.3 and you can find via PCR for 19 days. How many deaths per million would you find if you test all deaths in an average european city? cc @LDjaparidze
So now that I got your attention. Let's narrow it down. Our harmless virus would be found during it's spread frenzy at a rate of
OK. It seems I have a few epidemiologists playing. Here is a curve ball. Would change the results if we "Do nothing" (let it spread unmitigated) or if we mitigate it ('lockdown, masks, etc')? I know it is harmless!! Play along.
So let's see. If we don't do anything, an R0=3.3 harmless virus would burn out pretty fast. And in doing so we sould be able to find positive deaths at a rate of roughly 589 deaths per million. 
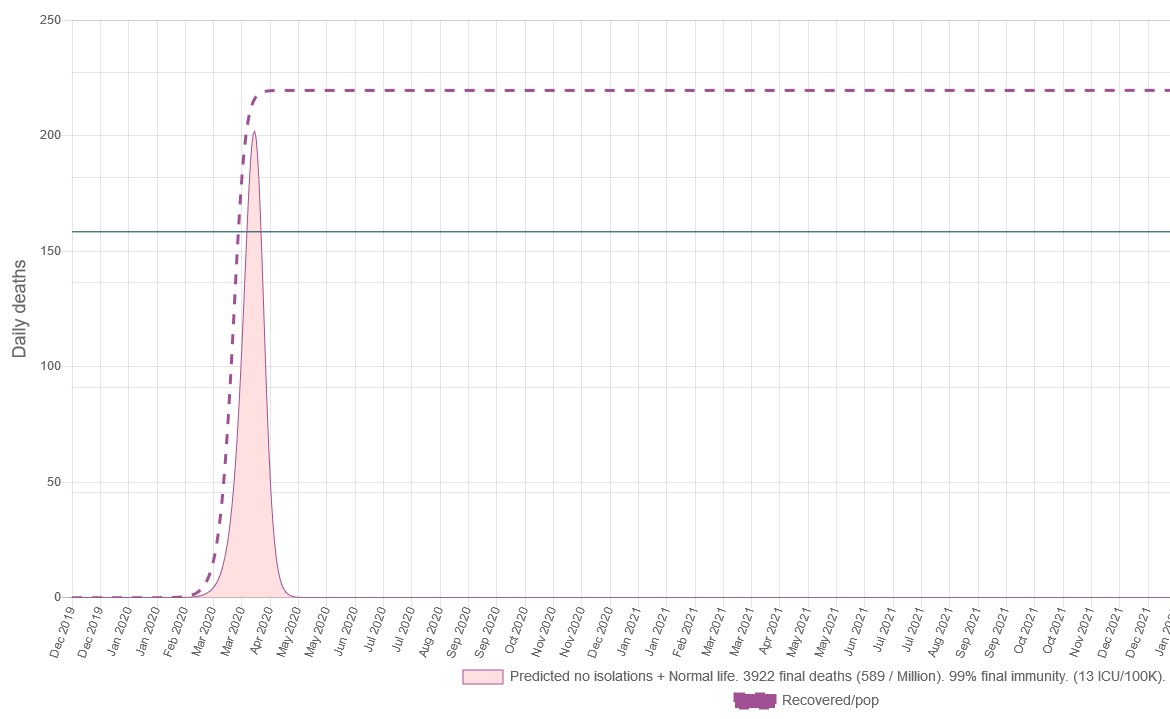
Now, if instead of "Do nothing" we pull a Madrid style mitigation for 180 days and the come back to normal life?
We mitigated, so instead of 1 very high spike now we have 2 of them. But interestingly it is lower at a rate of 530 deaths per million.
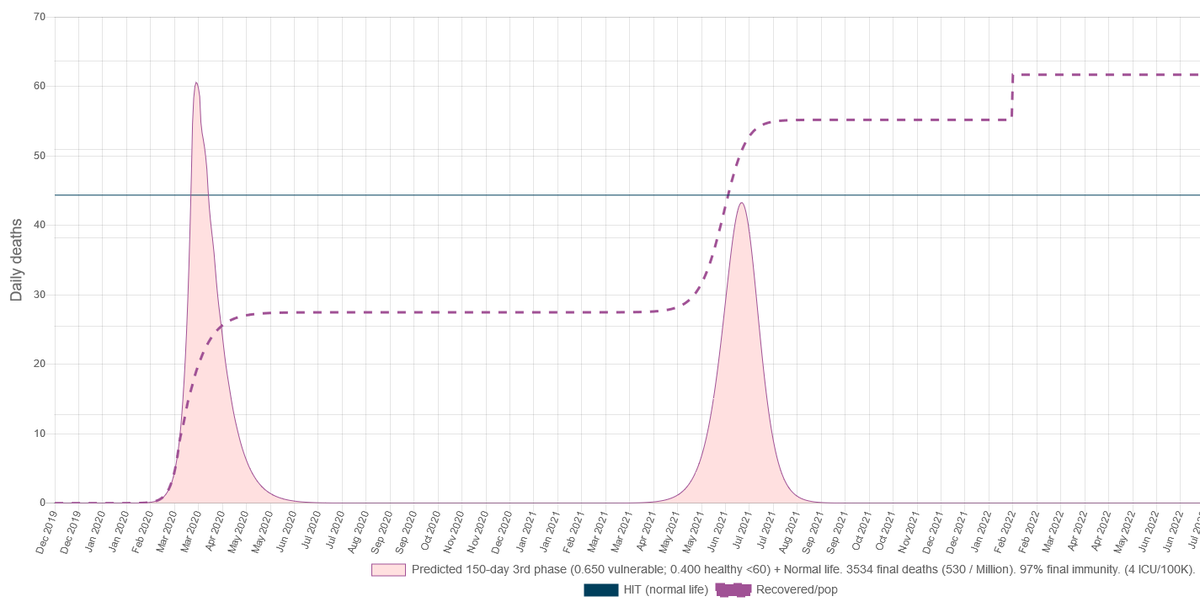
It wasn't going to be so easy. If instead of a Madrid we would have done a Stockholm?
Interestingly the height of the spike is not much different, BUT the second is much lower. The interesting thing is that we could detect our harmless virus at an outstanding rate of 353 death per million. Weird right?
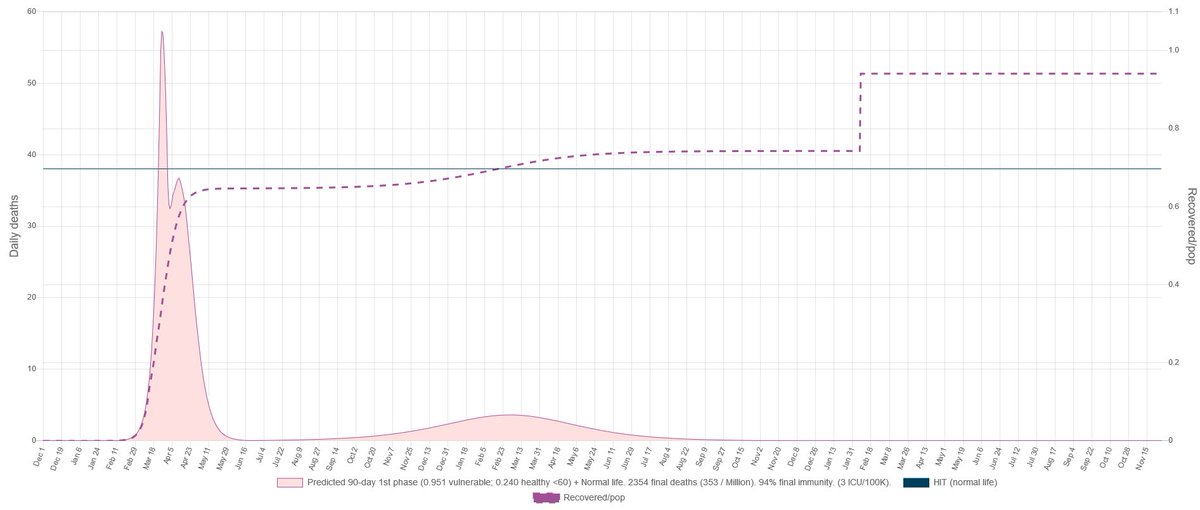
So the question is: How?
I know right... The idea that the spread of a disease can be described linearly is wrong. Whatever you think you know about the behavior, is probably wrong (weird math). Even the smallest detail can change the outcome. Certainty it's always a trap. Principles of biology.
But still, it is an interesting exercise to understand how sensible are the parameters to disturbances. Because that gives you context. Let's assume now this was Madrid. And there is a second clearly not harmless virus around.
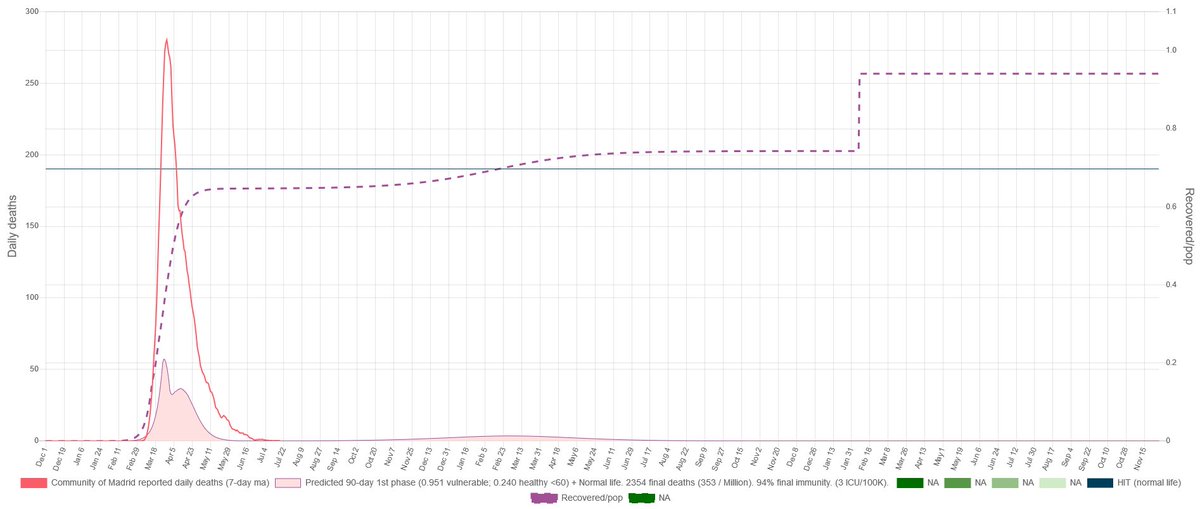
This is on our simulation how Madrid would look (given the parameter estimation we did) and how it would unfold following what has probably been happening in summer.
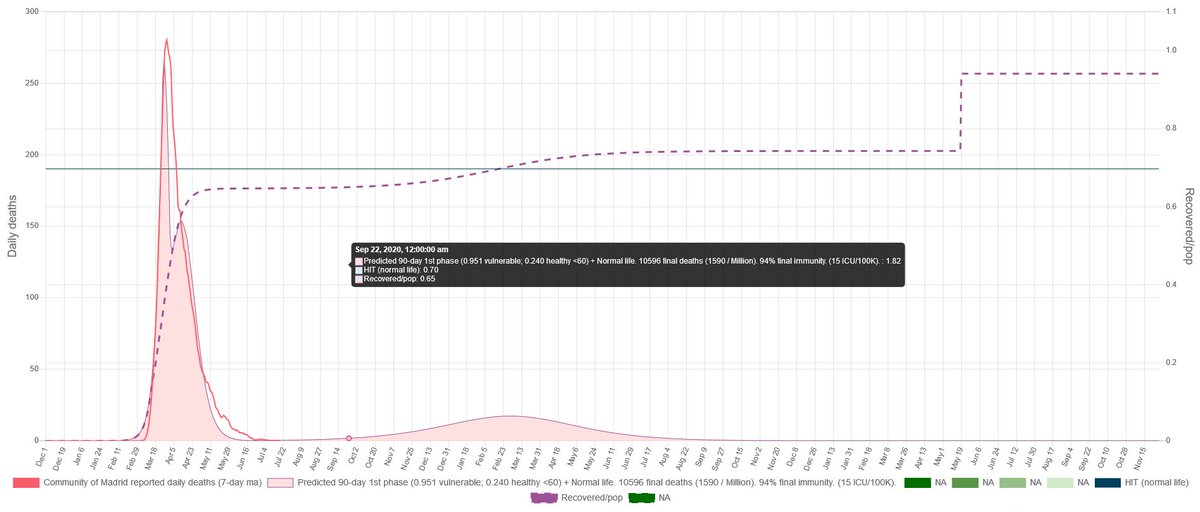
This is on our simulation how Madrid would have look (given the estimation we have for Stockholm) if it would have followed the Sweden Strategy
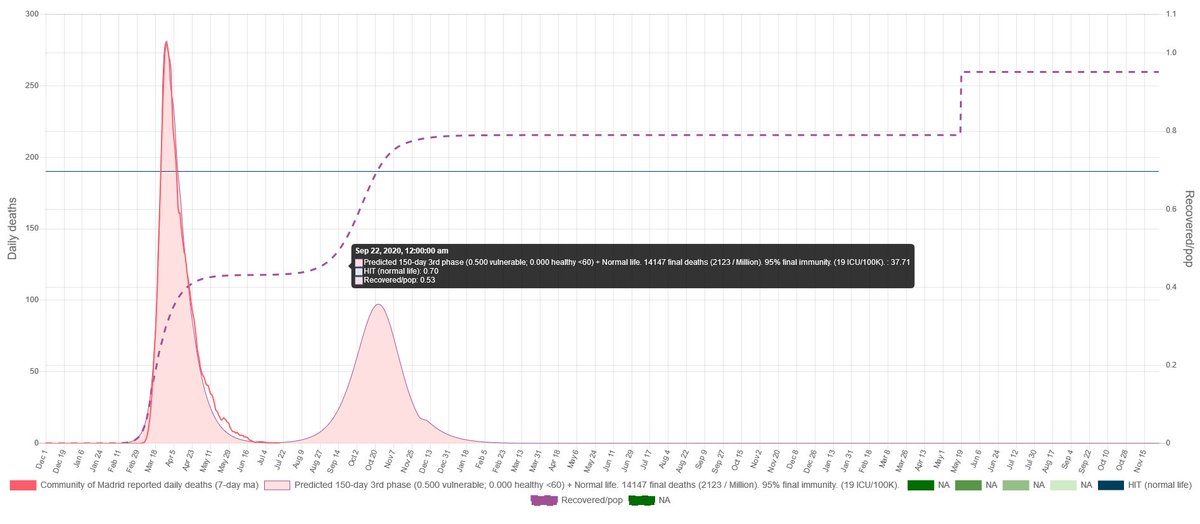
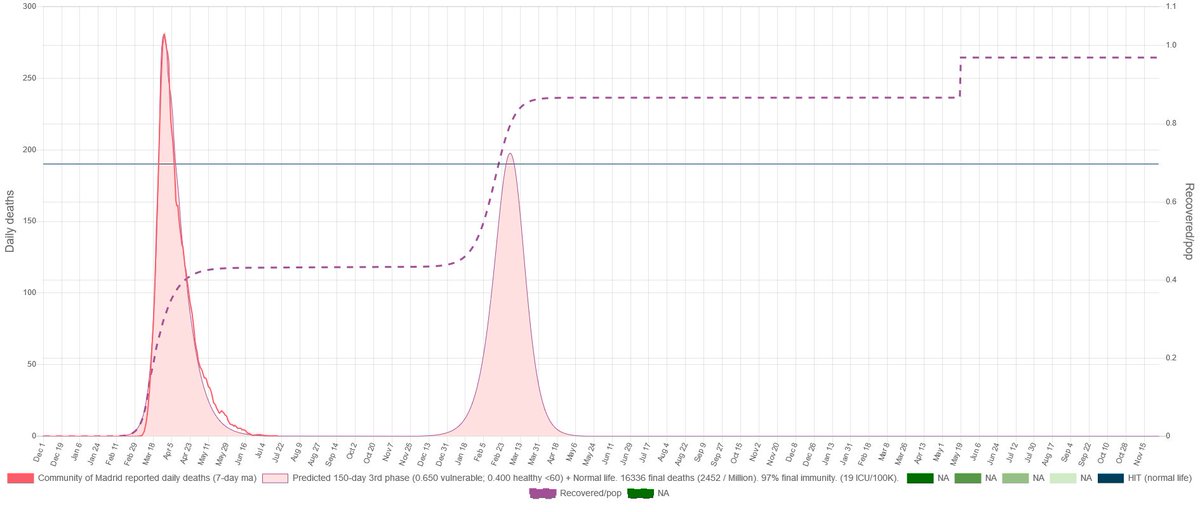
And this is how our simulation looks if Madrid continues mitigating as it would have done during the spring. Spike could start early because that would depend on our case on the seeding we do to the simulation. The overshooting could be big.
Weird math. I know.
And now the ultimate tests!! Didn't I say that the original virus was harmless? If the IFR is 0 where are all those deaths coming from?
If you need to refresh what the IFR is:
If you need to refresh what the IFR is:
https://twitter.com/federicolois/status/1308630933298466816
• • •
Missing some Tweet in this thread? You can try to
force a refresh