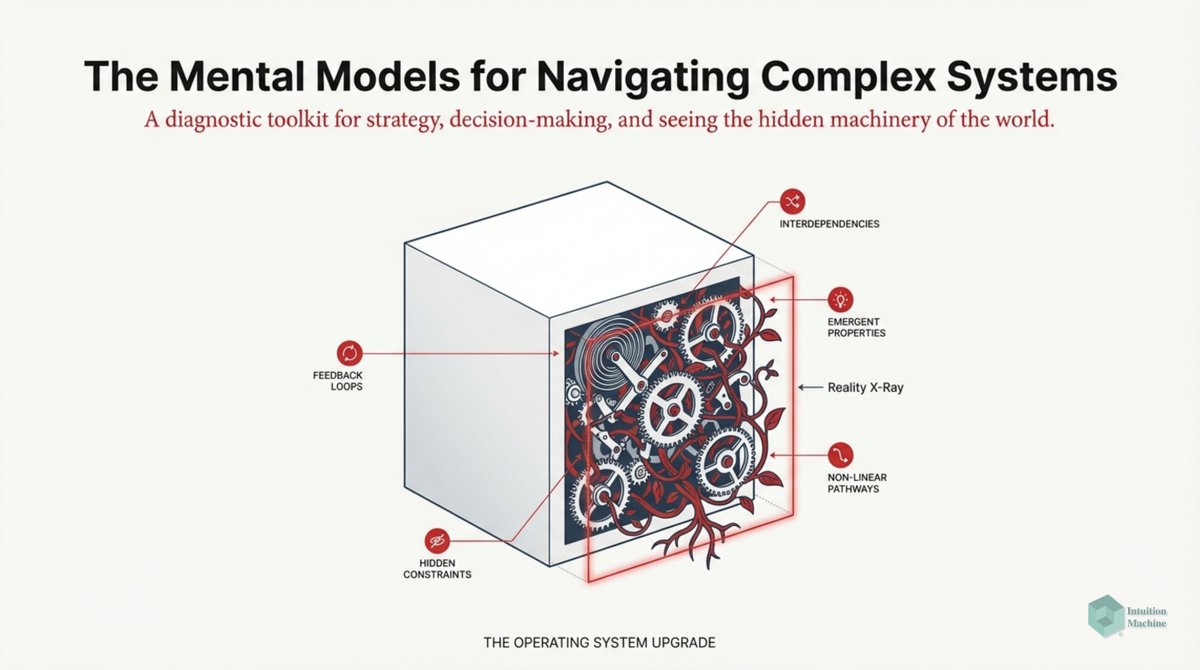
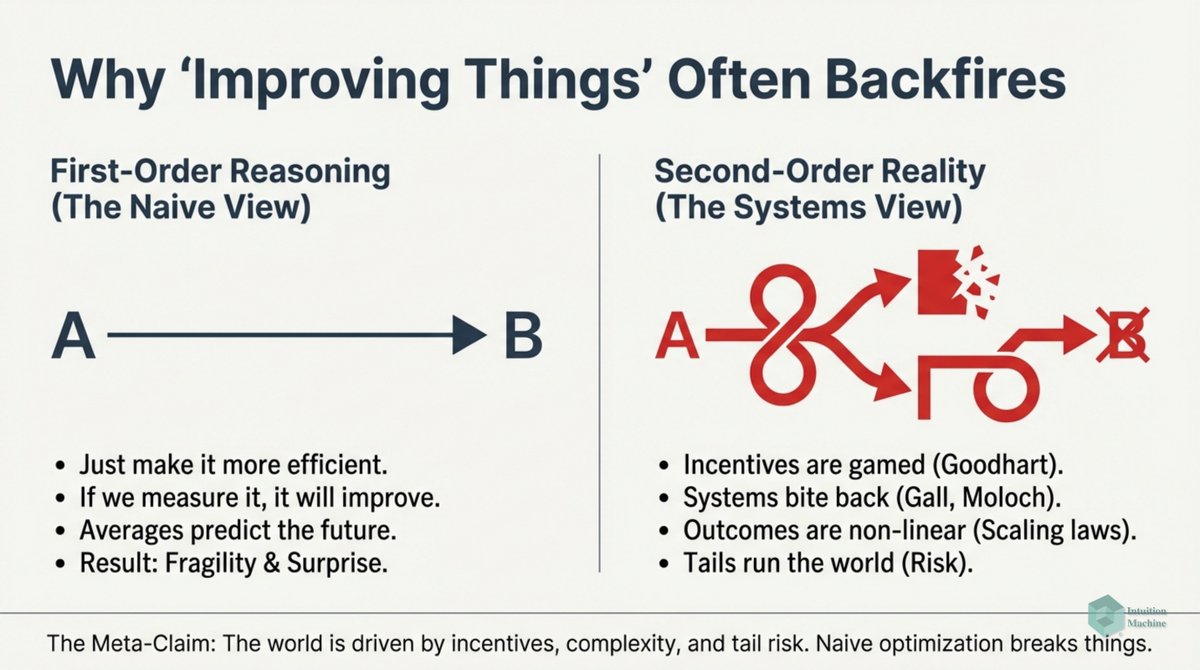
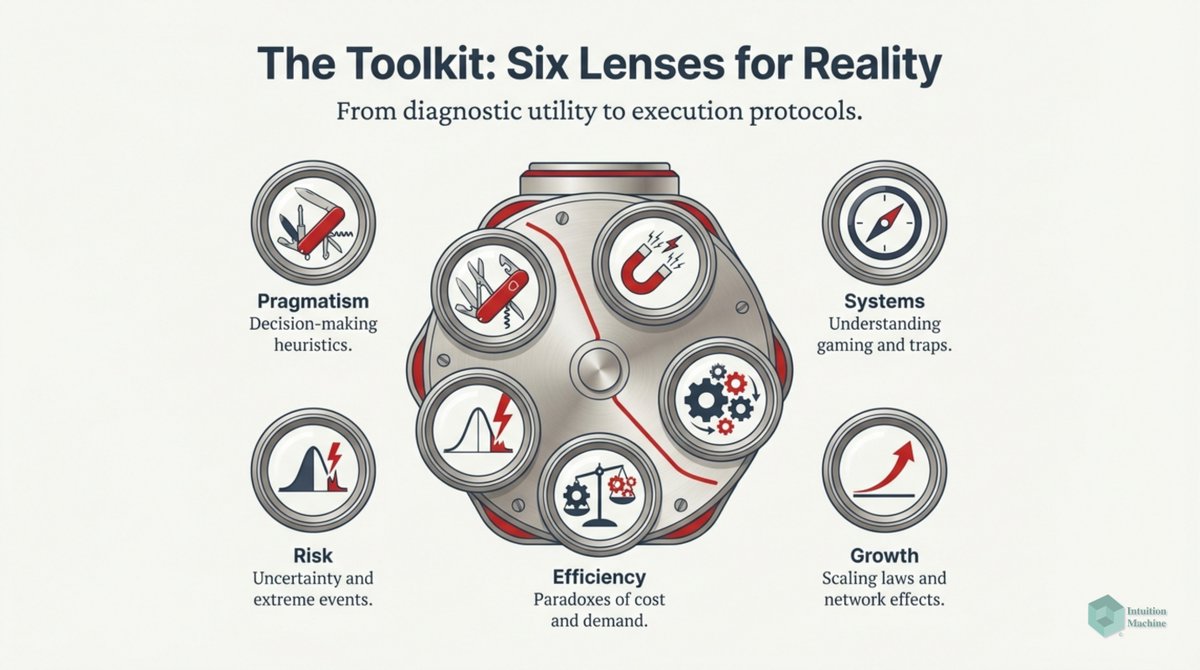
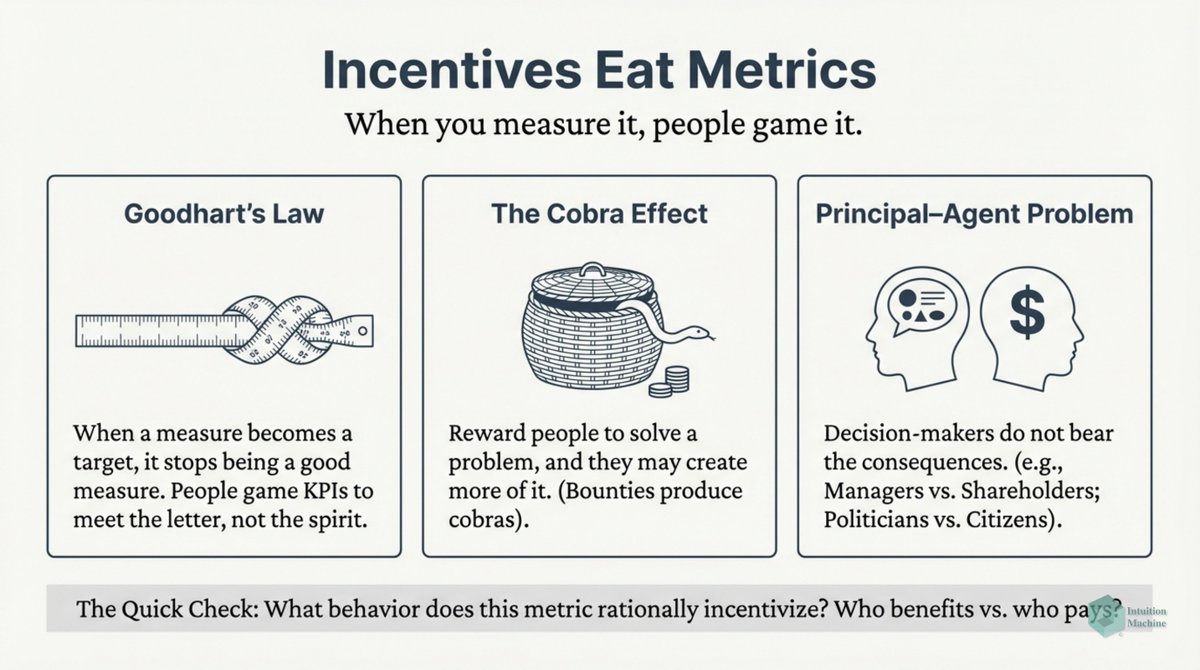
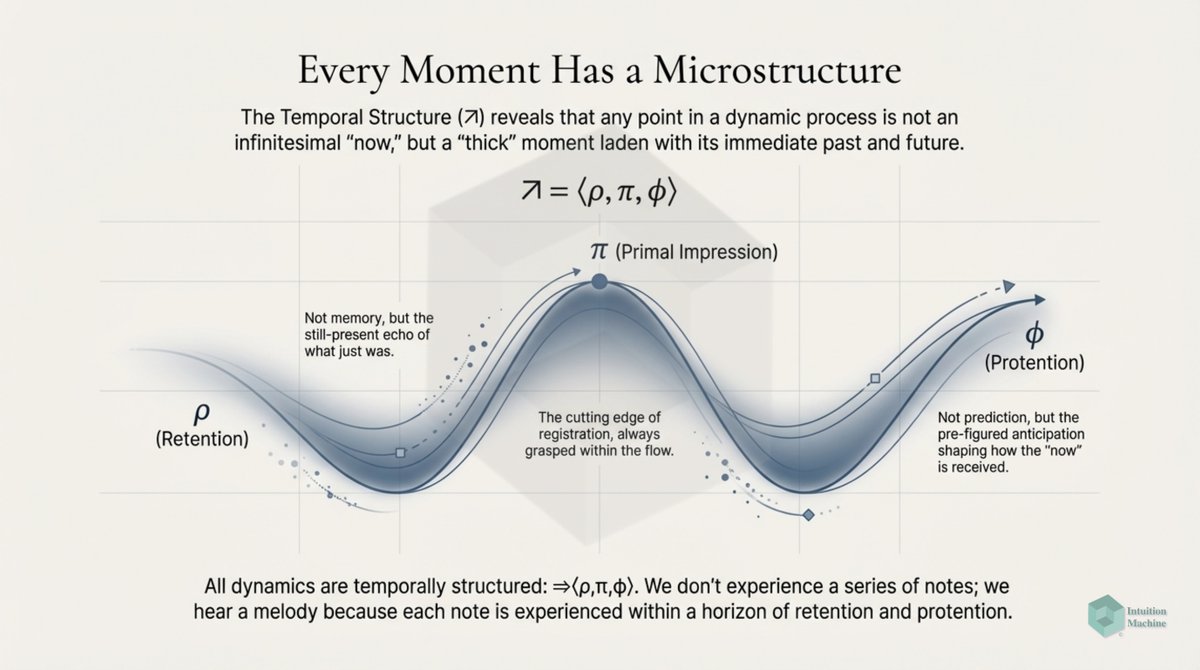
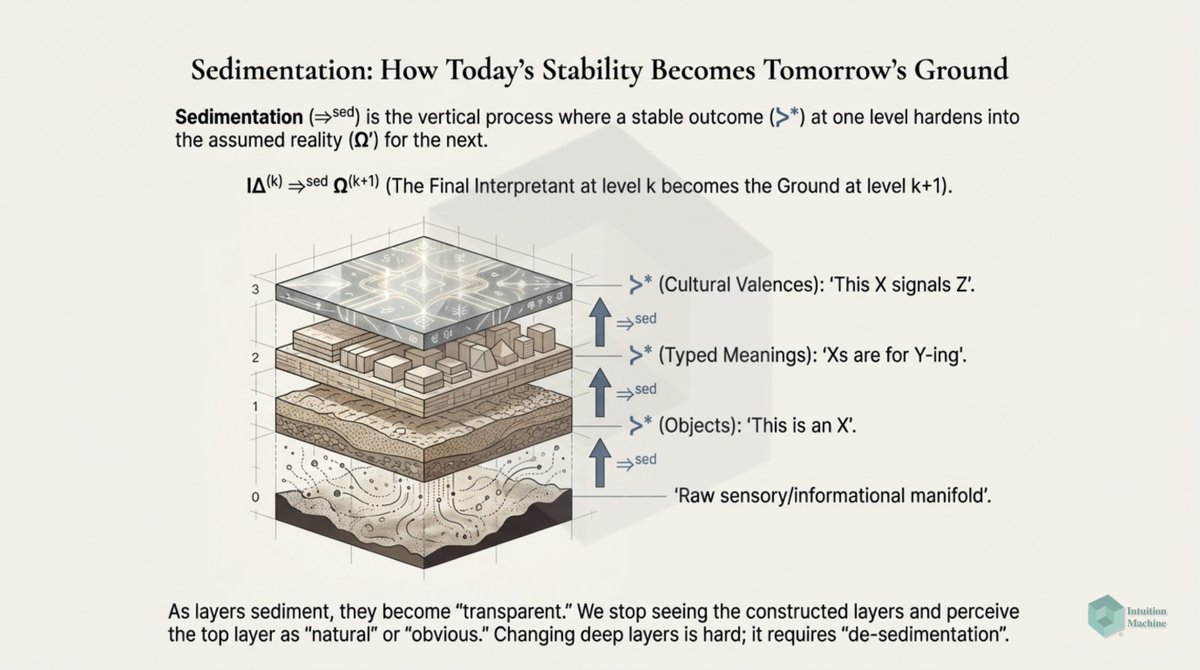
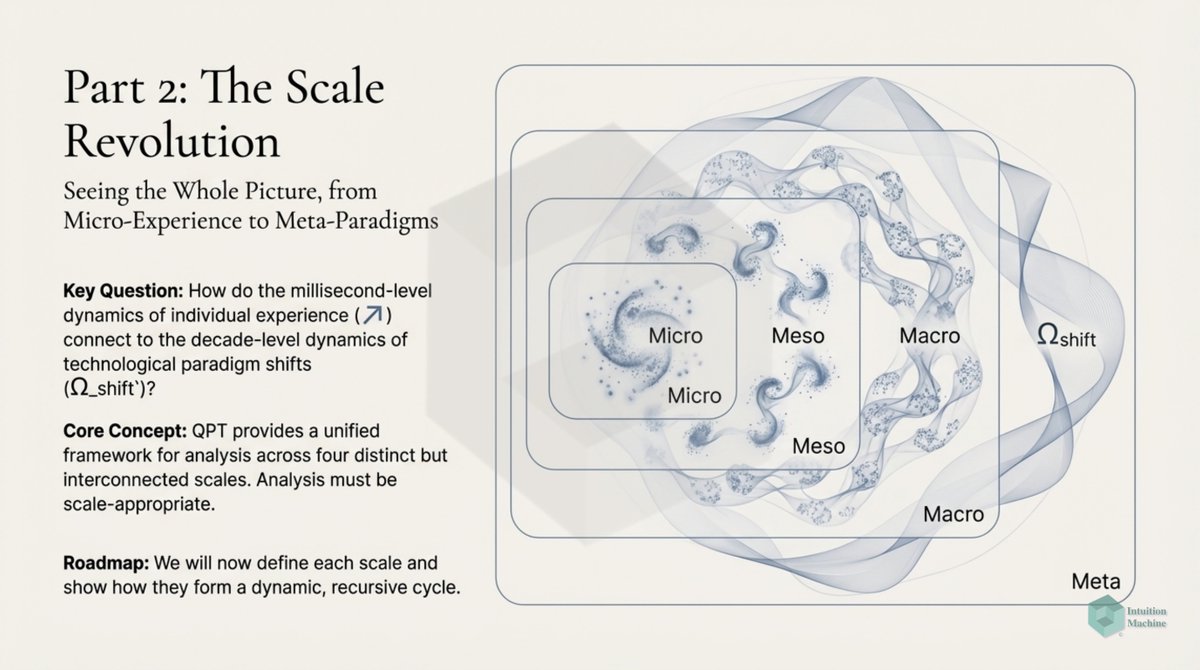
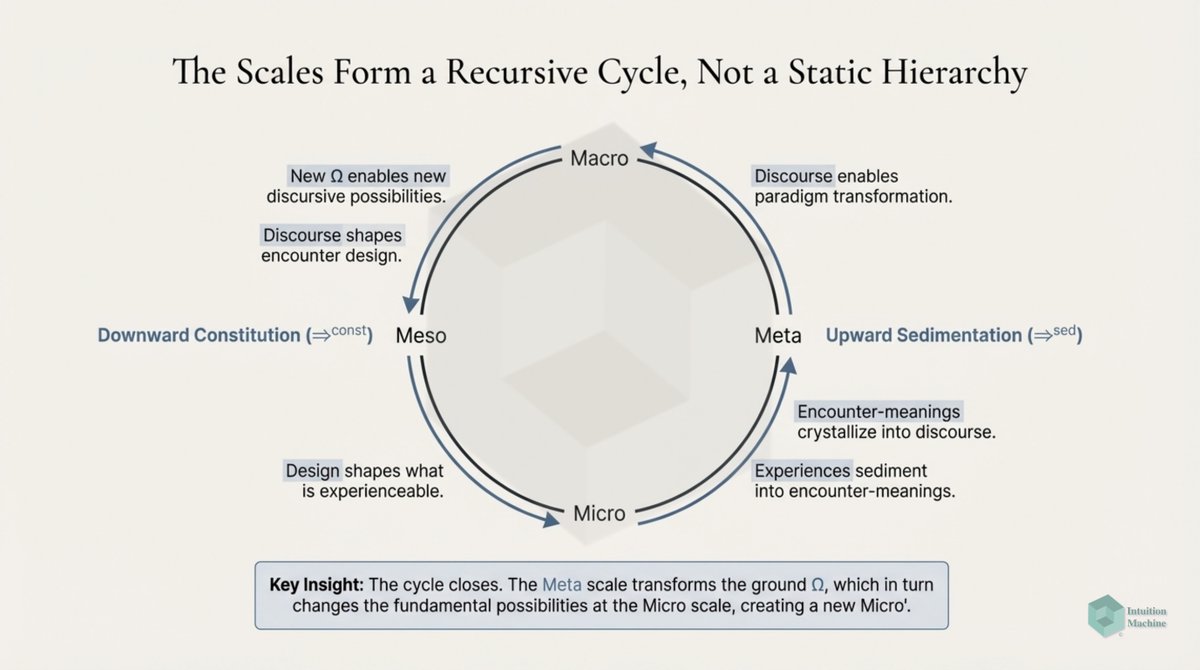
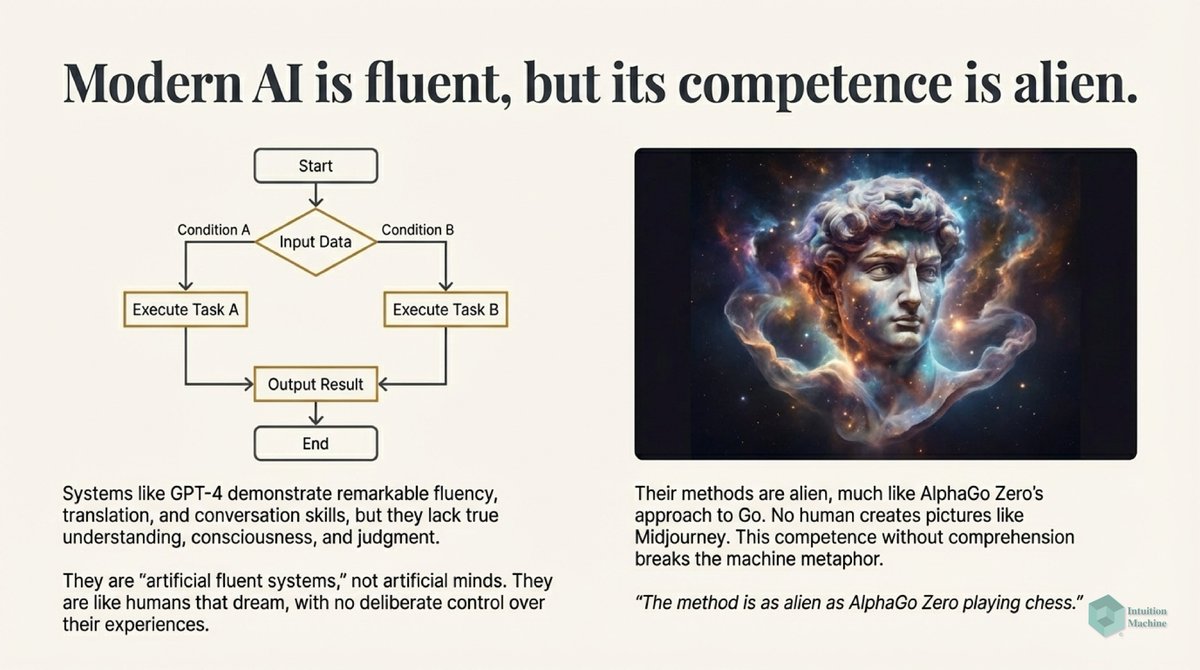
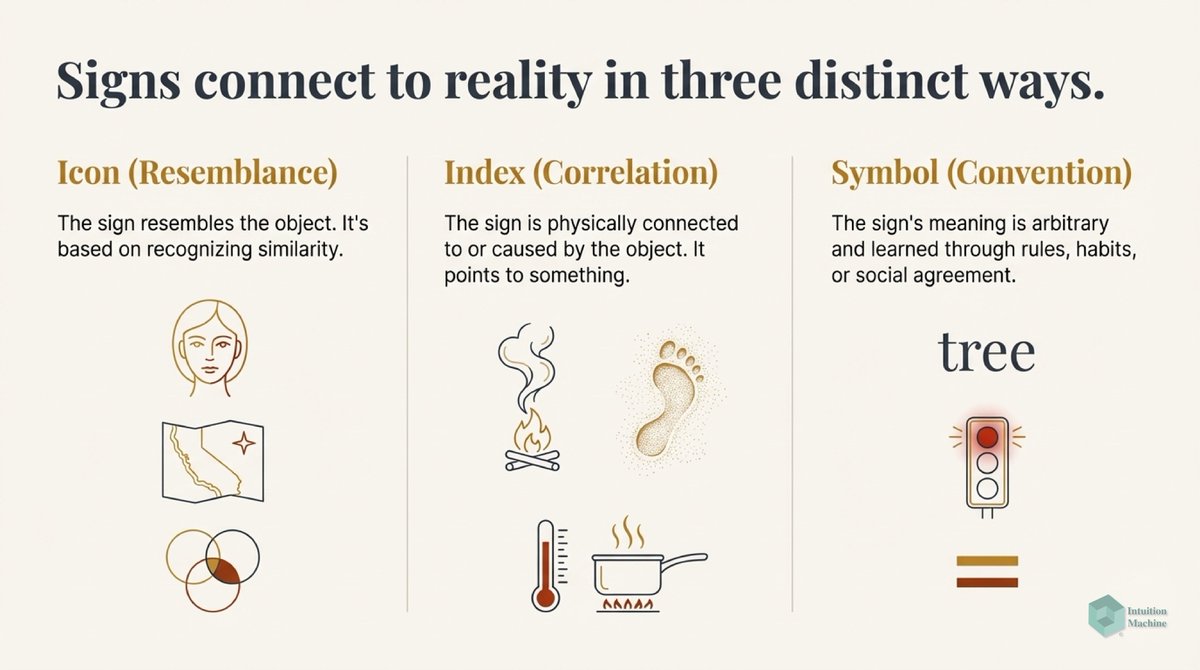
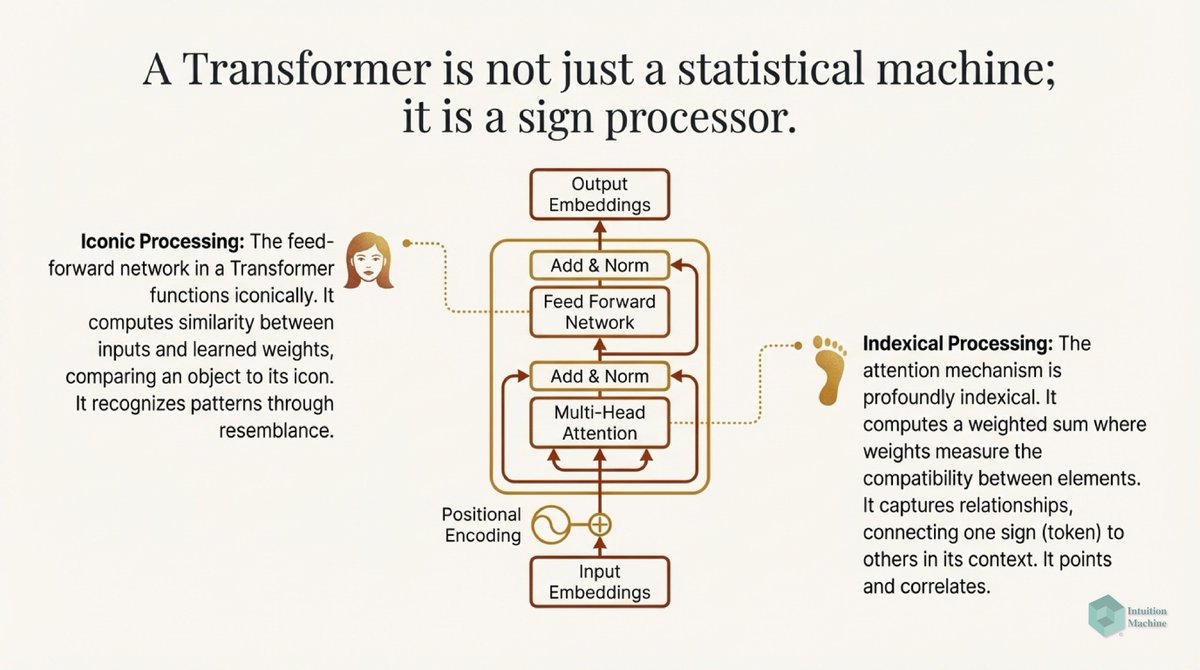
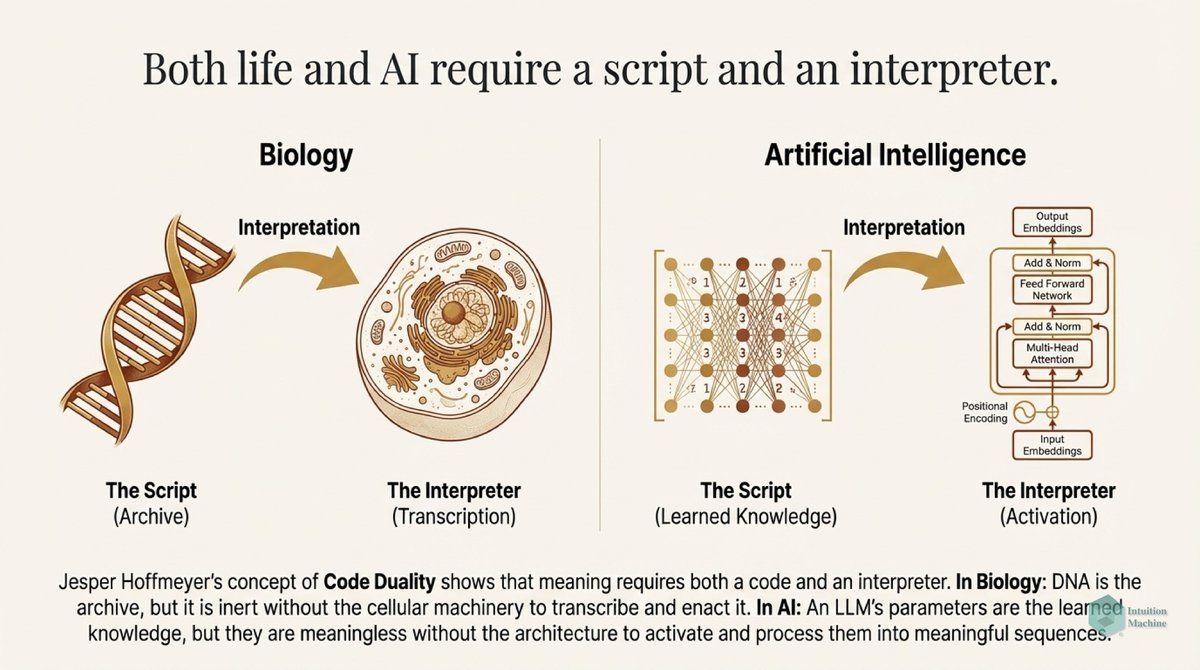
Raise your hand if you are get triggered by machine learning people who claim to understand intelligence when they never read a word on cybernetics, semiotics, enactivism or ecological psychology? #ai
More generally, they have never read any text about the importance of subjectivity to intelligence.
Seems like the 'shut up and calculate' mode of science continues to dominate the agenda. :-(
The saddest thing is that these are the same people who want to drive the conversation on AI ethics.
No wonder that we are heading straight over a cliff. This mechanistic objective view of reality leads us to building nothing but a mechanistic objective reality. Good luck living in a future world being nothing but a cog in the machinery.
• • •
Missing some Tweet in this thread? You can try to
force a refresh