In this thread, I will discuss the amazing power of Sanskrit Samāsas (compound nouns) and why they offer the ideal terminology for discussing complex ideas. All Indian languages borrow Sanskrit Samāsas, but this expressive power needs to be rekindled afresh for the modern world. 

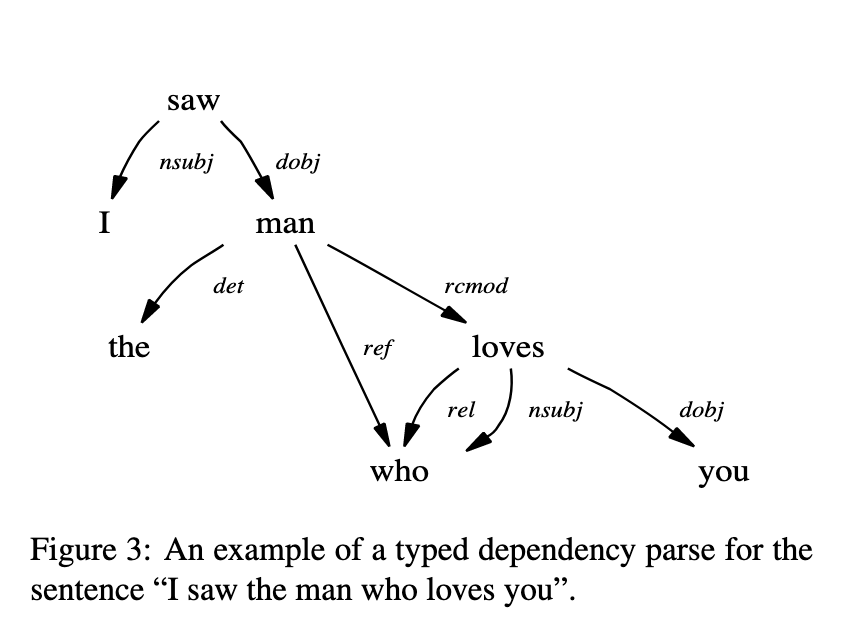
The picture that you see above is a "Parse Tree", which shows the conceptual dependencies between the different constituents of a word. The word's meaning is derived from the individual constituents, as well as from the relationship between them, given by the shape of the tree.
There are many types of parse trees, based on various theories of linguistics. The most common representation in European languages like English, which have a relatively fixed word order, is called a phrase structure tree. This is the tree for an example sentence in English.

In the above example, "the cat which is lying on the mat" is a complex concept. There is no single word for that in English. So you express it through a relative clause (here, an adjective clause "which is lying on the mat").
In Sanskrit, you can create a single word for it. 😀
In Sanskrit, you can create a single word for it. 😀
Here is another type of a parse tree, called a "dependency tree", used for free word order languages, like in India. Instead of following the order of words in the sentence, we depict the relationship in meaning between different words. The head-node is elaborated by child-nodes.
Dependency grammars are a fantastic tool in AI. Why? When we grasp the conceptual relationships between the words, we can apply that to many tasks: language translation, question answering, information extraction etc. Here is an example from Google's dependency parser software.
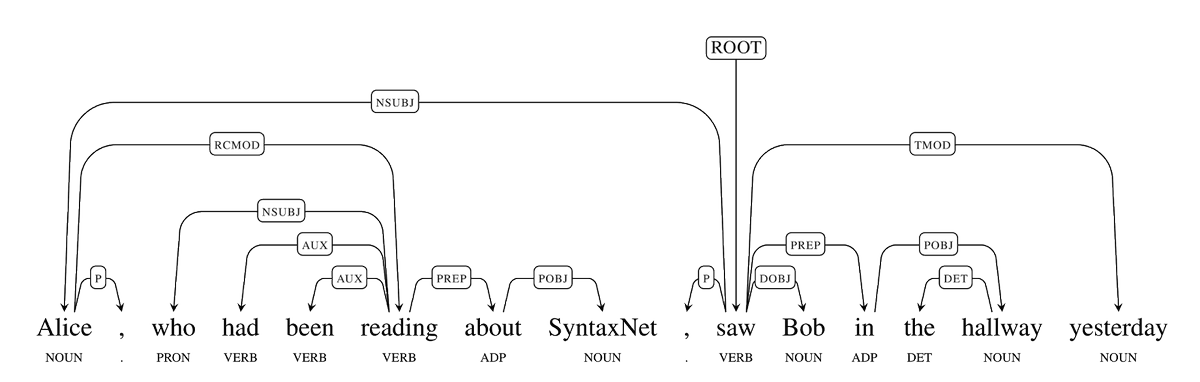
In the above example, "Alice,who had been reading about Syntaxnet" is a complex concept. You can see it has a full sentence within. In natural human languages, sentences can be embedded within other sentences using such tricks, generating parse-trees that can go many levels deep.
Now, here is the interesting thing. In Sanskrit, if needed, the relative clause "who had been reading about Syntaxnet" can be compressed into a single word.
A full dependency tree is snapped into a word.
Why would you want to do that? 😀
I will explain that in the following.
A full dependency tree is snapped into a word.
Why would you want to do that? 😀
I will explain that in the following.
But we can already see that something strange is going on with Sanskrit. When we are able to produce a single word equivalent to a complex sentence, we can see there are uncountable number of words in Sanskrit. So any dictionary for Sanskrit, unlike English, would be inadequate.
Other languages possess such capacity to a smaller degree. For example, if you are reading a German text and encounter a long word, you can try looking it up in a dictionary, but you will often not find it. In order to understand the word, you must break it at the right places.
In German, the compound is often a noun preceded by nouns or adjectives. If you try to build a dependency tree for these relationships, you will usually get a chain, each link qualifying the one that comes after it. Here is an example, "Fingerspitzengefühl" (finger-tip-feeling).
In contrast, the power of Sanskrit grammar is that you can have a very complex dependency tree for a single word, snapping almost entire sentences into one word.
Even a fairly complex algebraic expression can be compressed into a single word, like here.
Even a fairly complex algebraic expression can be compressed into a single word, like here.
https://twitter.com/vakibs/status/1285524024492089346?s=20
Before we see how such a thing is even possible, consider the title of any famous work of Sanskrit literature. Almost always a single word.
"Rāmāyana" (The journey of Rāma)
"Kirātārjunīyam" (The story of the hunter and Arjuna)
"Ābhijñānaśākuntalam" (The remembrance of Śakuntala)
"Rāmāyana" (The journey of Rāma)
"Kirātārjunīyam" (The story of the hunter and Arjuna)
"Ābhijñānaśākuntalam" (The remembrance of Śakuntala)
The most powerful dependency grammar that exists for any human language, even today, is one of the oldest: the Ashṭādhyāyi of Pāṇini. This Sanskrit grammatical tradition is the reason behind its extraordinary power of word formation.
All Indian languages borrow that power.
All Indian languages borrow that power.
For a treatise on the gigantic creative power of a spoken human language, Ashṭādhyāyi is also extraordinarily short. Just 4000 odd Sūtras (computational rules) generate the entire language.
And the vast majority of these rules are about *word-formation*, not sentence formation.
And the vast majority of these rules are about *word-formation*, not sentence formation.
The creative power of Sanskrit comes not just from Pānini’s work, but the millennia old grammatical tradition preceding it. It is already incipient in Vedic verses, arguably the oldest world literature. The Vedic chants are the reason why Indian languages have a free word order.
In order to memorize the verses precisely, the verses are sung in varying permutations, such as Ghanāpātha. The verse’s meaning should not change as the words are being shuffled around. This is ensured by case infections, which produce a free word order.
Sanskrit is a highly inflected language with seven cases (eight, when we count the Sambōdhanā vāchaka: salutation). Word morphology changes based on the case, gender, tense etc. This helps in disambiguating the parse tree, since the qualifier and the qualified must agree in case.
In the dependency tree, the head of any full sentence is a verb. All other words must explain their relationship to the verb. The 7 cases which specify the so-called “lexical relationship” are known in Sanskrit as Vibhakti. The actual semantic role they perform is called Kāraka.
The 7 cases of Sanskrit are preserved in Slavic languages. So in these languages, it is possible to shuffle the words around without losing meaning. German has only 4 cases. So shuffling is possible to a limited degree. English has very little case, so it has a fixed word order.
We should ask why there are just 7 cases in Sanskrit? My theory is that this is because of our human brain capacity in the working memory, where we can hold roughly 7 items at any time without forgetting or confusing between them. A larger working memory comes only by training.
So when we have a sentence in a human language, at the level of meaning, it should give roughly 7 concepts, explain the relationship between them and close the package. Then the brain processes this and stores it in the memory, ready to now accept a new sentence for processing.
The genius of Sanskrit comes from assigning “Kāraka roles” to all the seven cases: Karta (Doer/Agent), Karma (Object/Theme) etc. These elevate the syntactic analysis from sentence structure to meaning-structure. Then the whole tree can be made into a single word, if wanted.
The way it is done is through the so called Tatpurusha Samāsa. Certain words are grouped as having affinities (Ākānksha) to a specific Kāraka role, and when a word compound occurs with this word, we know how to imagine the equivalent dependency tree, even if the case is missing!
For example, the 2nd Tatpurusha Samāsa is made by words like Śrita (sought-er), Atīta (freed-er), Gata (going towards-er), Prāpta (obtained-er) etc.
There are many resources online to learn about Samāsas. I found these videos to be helpful (in Hindi).
There are many resources online to learn about Samāsas. I found these videos to be helpful (in Hindi).
Similarly, the 3rd Tatpurusha Samāsa is made of words like Samam (equal), Ūnam (lack), Miśram (mix) etc.
Although languages like English have a few such words, Sanskrit has a giant compendium of such useful words. There is a rich tradition of making such compounds on the fly.
Although languages like English have a few such words, Sanskrit has a giant compendium of such useful words. There is a rich tradition of making such compounds on the fly.
Tatpurusha Samāsa is one of the many possible Samāsa (compounds). There is the Karmadhāraya Samāsa (qualifier -> noun) which occurs also in other languages. This has the tendency to produce chain-like trees. But its power is brilliantly enhanced in conjunction with other Samāsas.
Perhaps, the most delightful of Sanskrit Samāsas is the Bahuvrīhi, which is an exocentric compound that means something apart from both the words in the compound. It appears rarely in other languages like English: e.g, a "sabretooth" is a tiger. But Sanskrit has loads of them.
But the critical power of Sanskrit comes from the so-called Avyayībhāva Samāsa. It is comparable to the Greek and Latin prefixes and suffixes (para-, syn-, peri-, -cule), which are the workhorses of scientific terminology in English. Sanskrit has a giant treasure of such Avyayās.
Here is a nice introduction to this Samāsa, from the online resource mentioned earlier.
Examples of Avyayās: Adhi- (in), Upa- (near), Nira- (not present), Anu- (suitable) and so on. These should be mastered by all scientists writing in Indian languages.
Examples of Avyayās: Adhi- (in), Upa- (near), Nira- (not present), Anu- (suitable) and so on. These should be mastered by all scientists writing in Indian languages.
If Sanskrit didn't have anything except Avyayībhāva Samāsa, it would already be a superior language to Greek/Latin in creating scientific terminology. However, in combination with the other Samāsas, it is simply matchless. It can condense any complex concept into a single word.
Finally, we have Dvandva Samāsa that replaces the conjunction in a sentence (e.g and). It can transform a list of things into a single word, putting them under an exocentric node. This completes the arsenal of tools available to transform any dependency tree into a single word.
An expert speaker in Sanskrit would know how exactly to use a Dvandva Samāsa to condense a parse tree unambiguously into a single word.
In the example I referred to earlier, "YōgaViyōga" is the Dvandva Compound embedded within to mean "sum & difference".
In the example I referred to earlier, "YōgaViyōga" is the Dvandva Compound embedded within to mean "sum & difference".
https://twitter.com/vakibs/status/1285524024492089346?s=20
There are natural pairs/lists of things in the world. For example, mother and father, wife and husband, body parts, seasons, dance forms and so on. When we use these words together in a compound, it will naturally lead to a Dvandva compound. The speakers will know automatically.
When we strip all the grammatical markers and smash the words together into a single compound word, we are naturally increasing the ambiguity. The total number of possible dependency trees that can be obtained from a Samāsa of "n" parts is a Catalan number, exponential in "n".
But the beauty of language is that speakers will use their language awareness (statistical frequency of words, poetic style etc.) to unambiguously pick the right dependency tree. This made Indian poets delight in a literary style where they created extraordinarily long words.
The longest word ever recorded in world literature is in a Telugu poem "Varadāmbikā Pariṇayam" by the queen Tirumalāmba. It is a complete Sanskrit compound with 195 Sanskrit syllables. We can see the English translation and try to imagine its complex dependency tree. 😄

It is only recently that western linguists understood the extraordinary strength of Sanskrit compounds. In this 2015 paper, the Oxford linguist John Lowe argued why Sanskrit compounds must be considered "syntactic structures" and not "lexical structures".
dx.doi.org/10.1353/lan.20…
dx.doi.org/10.1353/lan.20…
Lowe says that a word is processed as an "anaphoric island". It means the other words in a passage can refer to the word as a whole, but not to individual constituents. But not so for Sanskrit compounds.😀
Words with prefixes like "tad-", "svīya-" etc. can peek into other words.
Words with prefixes like "tad-", "svīya-" etc. can peek into other words.
"tad-" means "corresponding to that thing".
"svīya-" means "mine"
Such when such pronoun-related prefixes appear in a word, they help comment on what is happening within the dependency tree of a compound. Here is an example mentioned by Lowe.
"svīya-" means "mine"
Such when such pronoun-related prefixes appear in a word, they help comment on what is happening within the dependency tree of a compound. Here is an example mentioned by Lowe.

At this point, I have to mention that all these tools for Sanskrit Samāsa are routinely used within Telugu, and perhaps also in other Indian languages.
It is not just about Sanskrit or ancient texts in Sanskrit. This is a fully alive expressive power in many Indian languages.
It is not just about Sanskrit or ancient texts in Sanskrit. This is a fully alive expressive power in many Indian languages.
When I write a technical essay in Telugu, I often find myself compressing several words in a phrase into a single word.
E.g: "Bādhyatāyuta-kṛtimamēdhānirmāṇaṃ" బాధ్యతాయుతకృతిమమేధానిర్మాణం बाध्यतायुतकृतिममेधानिर्माणं (the development of responsible artificial intelligence)
E.g: "Bādhyatāyuta-kṛtimamēdhānirmāṇaṃ" బాధ్యతాయుతకృతిమమేధానిర్మాణం बाध्यतायुतकृतिममेधानिर्माणं (the development of responsible artificial intelligence)
What is the advantage of having such a long compound word? Then it be combined with other words to express a complex thought as a single sentence. It can have all types of case inflections (signifying kāraka roles). Such precision will not be obtained when we break the sentence.
There is an extra power, which most people don't notice. Sanskrit doesn't need any punctuation marks whatsoever. They are all superflous. We don't need commas, question marks, exclamation marks .. Nothing. A correctly formulated sentence will be 100% precise without any of that!
This exact same fecundity and precision of Sanskrit is available to other Indian languages, whenever they borrow the grammatical machinery of Sanskrit. But most people have forgotten this, after centuries of colonial rule which destroyed native traditions of scholarship.
There will be a time when full professional education, research scholarship and creative expression will return to Indian languages. When that happens, people will see how *inadequate* the current expression in English is. I hope this time occurs soon, in our own lifetimes. (END)
I forgot to mention: I once translated the titles of my scientific papers into Telugu.
All these titles are actually single words in Sanskrit, when Sandhi is applied !Just like the titles of Sanskrit literature.
In Telugu, the Sandhi is optional.
All these titles are actually single words in Sanskrit, when Sandhi is applied !Just like the titles of Sanskrit literature.
In Telugu, the Sandhi is optional.
https://twitter.com/vakibs/status/990188637798232064?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh