
To the "do it all" IT folks or new #SOC analysts that need a little help - a thread for you.
Cheat sheets and example queries for Endgame, CS Falcon, ATP, and CbR using a recent incident as the starting point.
cc: thanks to @AshwinRamesh94 for the query work
Cheat sheets and example queries for Endgame, CS Falcon, ATP, and CbR using a recent incident as the starting point.
cc: thanks to @AshwinRamesh94 for the query work
Yesterday we stopped a #ransomware attack at a customer where initial entry was a remote admin connection from a 3p IT provider
- Attacker had admin
- Connected to host via ConnectWise (RDP)
- Opened CMD shell to open PS download cradle to deploy SODINOKIBI from hastebin[d]com
- Attacker had admin
- Connected to host via ConnectWise (RDP)
- Opened CMD shell to open PS download cradle to deploy SODINOKIBI from hastebin[d]com

The attacker ransomed 1 host - but by removing access 6 min after the attack started - stopped it from becoming a much bigger issue.
Let's walk through a question or two we asked along the way using different EDR tech....
Let's walk through a question or two we asked along the way using different EDR tech....
First up: @EndgameInc
Let's look at process events where the args contain our delivery domain and evil PS:
Process argument events:
process where command_line ==”*hastebin.com*” or command_line == “*Invoke-CVUYDBVIUPNEXMR*”
Cheat sheet below.
Let's look at process events where the args contain our delivery domain and evil PS:
Process argument events:
process where command_line ==”*hastebin.com*” or command_line == “*Invoke-CVUYDBVIUPNEXMR*”
Cheat sheet below.


Let's also ask: How often does CMD / PS spawn from ScreenConnect.ClientService.exe? The remote admin tool.
Here's the EQL search:
process where child of [process where process_name == "ScreenConnect.ClientService.exe"] on active endpoints
It wasn't common. Detection?
Here's the EQL search:
process where child of [process where process_name == "ScreenConnect.ClientService.exe"] on active endpoints
It wasn't common. Detection?
How about CrowdStrike Falcon...
Let's use their event search here:
CommandLine=”*hastebin.com*” OR CommandLine=”*Invoke-CVUYDBVIUPNEXMR*” OR FileName=*ge4545*
Note the use of the *wildcard operator to search for the encrypted file extension
Let's use their event search here:
CommandLine=”*hastebin.com*” OR CommandLine=”*Invoke-CVUYDBVIUPNEXMR*” OR FileName=*ge4545*
Note the use of the *wildcard operator to search for the encrypted file extension
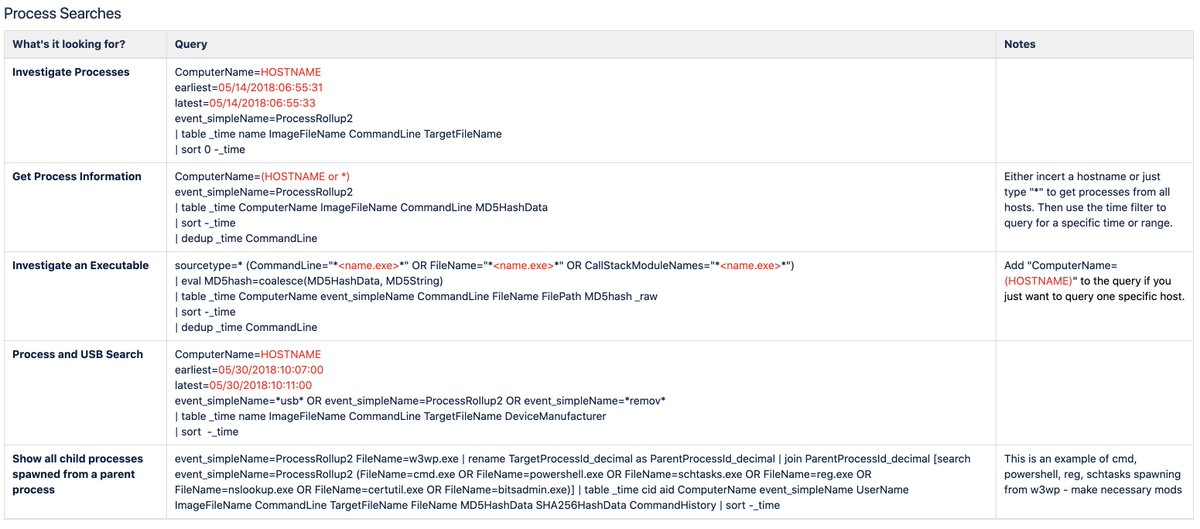
Or maybe you're running MS Defender ATP.
DeviceProcessEvents
| where FileName in~(“cmd.exe”, “powershell.exe”)
| where ProcessCommandLine has “hastebin.com”
or ProcessCommandLine has “Invoke-CVUYDBVIUPNEXMR”
I couldn't include the full query, shared below
DeviceProcessEvents
| where FileName in~(“cmd.exe”, “powershell.exe”)
| where ProcessCommandLine has “hastebin.com”
or ProcessCommandLine has “Invoke-CVUYDBVIUPNEXMR”
I couldn't include the full query, shared below

Or if your EDR wasn't mentioned above, practice searching for these IOCs:
Delivery domain ➡️ netconn to hastebin.com
Evil PS ➡️ Invoke-CVUYDBVIUPNEXMR
Encrypted file extension ➡️ ge4545
Delivery domain ➡️ netconn to hastebin.com
Evil PS ➡️ Invoke-CVUYDBVIUPNEXMR
Encrypted file extension ➡️ ge4545
Now try searching for activity more broadly:
How often do you see PowerShell download / execute a file from a remote resource?
Endgame:
sequence [process where command_line == "*iex*" and process_name in ("powershell.exe", "powershell_ise.exe")] [network where true]
How often do you see PowerShell download / execute a file from a remote resource?
Endgame:
sequence [process where command_line == "*iex*" and process_name in ("powershell.exe", "powershell_ise.exe")] [network where true]
CrowdStrike Falcon:
FileName="powershell.exe" AND CommandLine="* iex *"
(the spaces in between iex is important to remove fp wildcard matching)
FileName="powershell.exe" AND CommandLine="* iex *"
(the spaces in between iex is important to remove fp wildcard matching)
Once you have the ContextProcessID_decimal value, use that in this query to determine outbound network connections:
(ContextProcessId_decimal=<enter_value> OR TargetProcessId_decimal=<enter_value>) AND NetworkConnectCount_decimal >=1
(ContextProcessId_decimal=<enter_value> OR TargetProcessId_decimal=<enter_value>) AND NetworkConnectCount_decimal >=1
Windows Defender ATP:
union DeviceProcessEvents, DeviceNetworkEvents
| where ProcessCommandLine has “iex”
or ProcessCommandLine has “invoke-expression”
| where FileName in~(“powershell.exe”, “powershell_ise.exe”)
| where isnotempty(RemoteUrl)
union DeviceProcessEvents, DeviceNetworkEvents
| where ProcessCommandLine has “iex”
or ProcessCommandLine has “invoke-expression”
| where FileName in~(“powershell.exe”, “powershell_ise.exe”)
| where isnotempty(RemoteUrl)
Carbon Black:
cmdline:”iex” AND (process_name:powershell.exe OR process_name:powershell_ise.exe) AND netconn_count:[1 TO *]
Before, "well actually" enters the chat. Good to include processes loading system.management.automation
modload:system.management.automation*
cmdline:”iex” AND (process_name:powershell.exe OR process_name:powershell_ise.exe) AND netconn_count:[1 TO *]
Before, "well actually" enters the chat. Good to include processes loading system.management.automation
modload:system.management.automation*
The above were basic queries to help you learn the tools.
Think about the questions you want to ask and practice asking them using EDR.
Don't forget to learn about host containment. Learn how it works, how to use it.
It could be a thing that ends up saving your org.
Think about the questions you want to ask and practice asking them using EDR.
Don't forget to learn about host containment. Learn how it works, how to use it.
It could be a thing that ends up saving your org.
Or try this....
1. Open PS
2. wmic /node:localhost process call create “cmd.exe /c notepad”
3. winrs:localhost “cmd.exe /c calc”
4. Interrogate your SIEM and EDR
5. Practice containment
6. Do it again
7. Talk about what this mean as a team
1. Open PS
2. wmic /node:localhost process call create “cmd.exe /c notepad”
3. winrs:localhost “cmd.exe /c calc”
4. Interrogate your SIEM and EDR
5. Practice containment
6. Do it again
7. Talk about what this mean as a team
• • •
Missing some Tweet in this thread? You can try to
force a refresh



