
Excited to share our @emnlp2020 paper on task transferability:
1) a large-scale empirical study w/ over 3,000 combinations of NLP tasks and data regimes within and across different classes of problems
2) task embedding methods to predict task transferability
1/12👇
1) a large-scale empirical study w/ over 3,000 combinations of NLP tasks and data regimes within and across different classes of problems
2) task embedding methods to predict task transferability
1/12👇
https://twitter.com/colinraffel/status/1275856152878895104


Transfer learning with large-scale pre-trained language models has become the de-facto standard for state-of-the-art performance on many NLP tasks. Can fine-tuning these models on source tasks other than language modeling further improve target task performance? 🤔
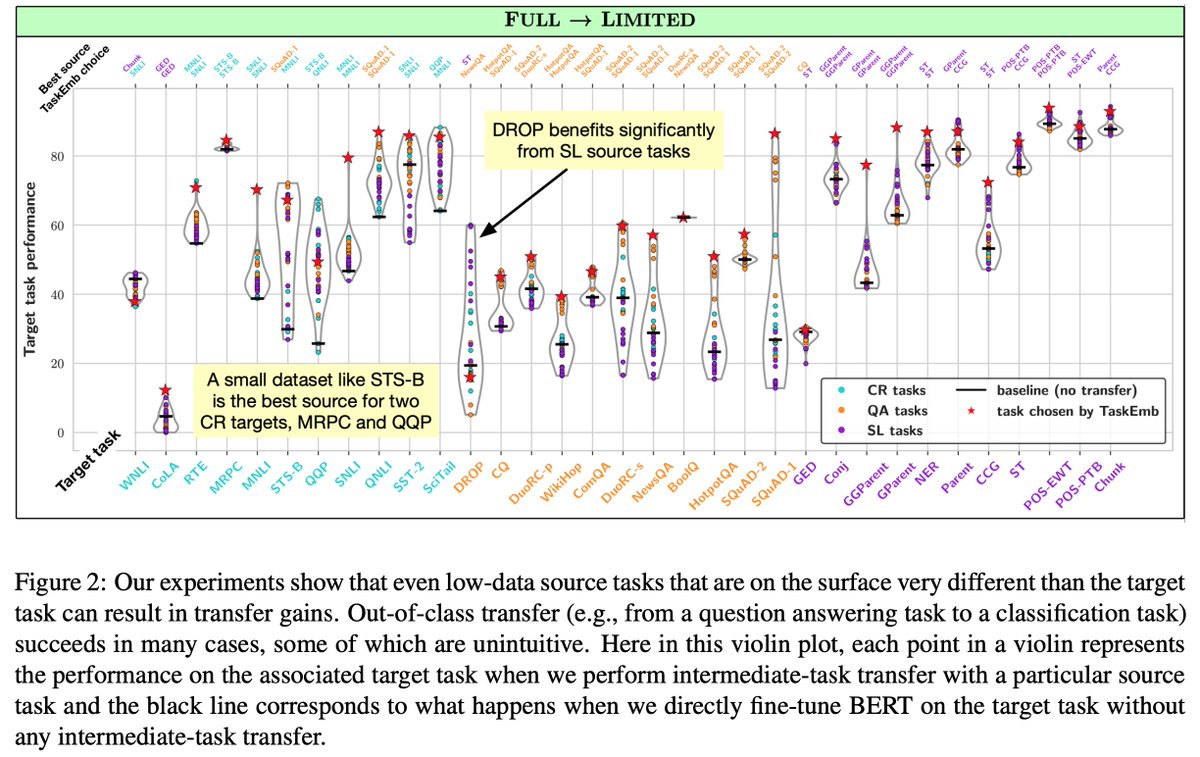
The answer is yes, as shown by Phang et al. (2018), but the conditions for successful transfer remain opaque. Which combinations of tasks can perform well in this transfer setting? 🤔 An arbitrary combination often adversely impacts target task performance (Wang et al., 2019).
To shed light on the transferability between NLP tasks, we conduct a large-scale empirical study w/ over 3,000 combinations of source/target tasks & data regimes within and across three broad classes of problems: text classification, question answering, and sequence labeling. 🔍
Our experiments show that positive transfer can occur in a diverse array of settings. Contrary to the common wisdom, transfer gains are possible even when the source dataset is small. Also, out-of-class transfer succeeds in many cases, some of which are unintuitive.

Our results reveal that factors other than source dataset size, such as the similarity between the source and target tasks, or the complexity of the source task, matter more in low-data regimes.
Is there a principled way to predict the most transferable source tasks for a novel target task? 🤔We address this challenge by developing task embedding methods that encode properties of individual tasks and can be used to reason about their relationships (w/ cosine similarity).

Our first method, TextEmb, is computed by pooling BERT’s final-layer token-level representations across an entire dataset, and as such captures properties of the text and domain. This method does not depend on the training labels and thus can be used in zero-shot transfer.

The second method, TaskEmb, is computed from BERT’s layer-wise gradients. It relies on the correlation between the fine-tuning loss function and the parameters of BERT, and encodes more information about the type of knowledge and reasoning required to solve the task.

On the meta-task of selecting the best source task for a given target task, our task embedding methods generally outperform baseline methods that use the dataset size heuristic and the gradients of the learning curve across settings.
Work done with amazing collaborators: Tong Wang, @TsendeeMTS, @murefil, @APTrizzle at @MSFTResearch; Andrew Mattarella-Micke at @Intuit AI; @MajiSubhransu, and my advisor @MohitIyyer at @umasscs.
Paper: arxiv.org/abs/2005.00770
Data and code: github.com/tuvuumass/task…
Paper: arxiv.org/abs/2005.00770
Data and code: github.com/tuvuumass/task…
Finally, this work was done with a few hundred thousand GPU jobs in several months. We couldn’t have completed it without the awesome GPU cluster operating on renewable energy at @umasscs. So, please consider doing a Ph.D. here. 😀
• • •
Missing some Tweet in this thread? You can try to
force a refresh


