
Iterative migrations are the future, and @opentelemetry is leading the way! #KubeCon #CloudNativeCon @ccaramanolis
https://twitter.com/danielbryantuk/status/1329487348774674433
Next up: Wojciech Tyczyński of SIG Scalability on the necessary k8s and etcd changes to scale to clusters with 15k+ nodes.
First off, scalability isn't really number of nodes, but a lot of factors that may scale with cluster size.
#KubeCon #CloudNativeCon
First off, scalability isn't really number of nodes, but a lot of factors that may scale with cluster size.
#KubeCon #CloudNativeCon
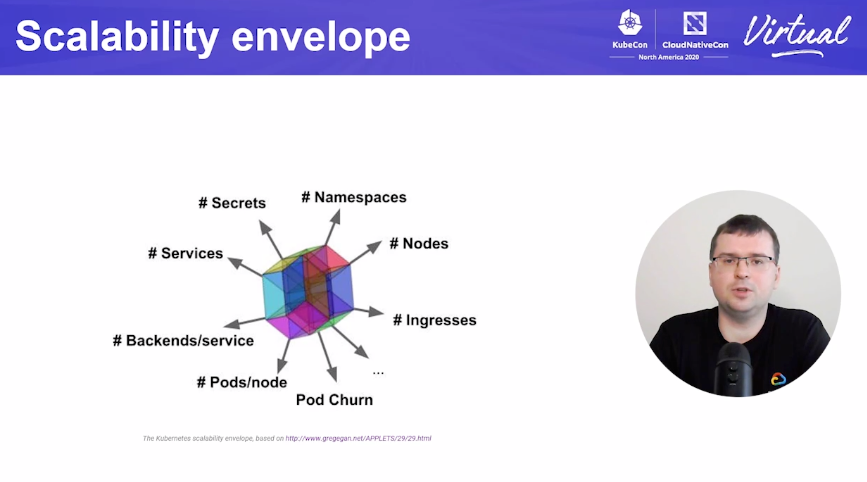
Starting with real life usecases: @TwitterEng currently running on mesos clusters, which can handle 40-60k nodes in a single cluster
But scalability work affects everyone! This makes all clusters more reliable and performant.
#KubeCon #CloudNativeCon
But scalability work affects everyone! This makes all clusters more reliable and performant.
#KubeCon #CloudNativeCon
You can't talk about K8s scalability without etcd. Minimized the number of blocking read/write operations. This can happen if you have a lot of custom resources in a smaller cluster too (now available in @etcdio 3.4)
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon

Another bottleneck is apimachinery and how it bookmarks requests, speeds up issues with latency (GA in @kubernetesio 1.17)
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon

Networking with a medium-sized node cluster, apiserver has to send a lot of data due to Endpoints storing data per pod, quickly becomes an issue for deploys of larger services. EndpointSlices introduced to mitigate this (Beta in @kubernetesio 1.19)
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon

Next up, Storage: Immutability to secret and confimap API so that kubelet does not need to watch for changes, reduces load on control plane (also @kubernetesio 1.19)
Golang memory allocation was also a bottleneck (!!!), benefits the whole ecosystem
#KubeCon #CloudNativeCon
Golang memory allocation was also a bottleneck (!!!), benefits the whole ecosystem
#KubeCon #CloudNativeCon
Very important slide, K8s scalability is not isolated. The rest of your infrastructure needs to scale too (Note: I will also emphasis network integration!!!)
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon

By the way, some of the K8s limits/thresholds are documented here: github.com/kubernetes/com…
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon
Next up: SIG App-Delivery presents how to solve everyday problems with the landscape (CI/CD, image build/app def, scheduling/orchestration) @resouer @AloisReitbauer #CloudNativeCon #KubeCon

BTW I'm also keeping an eye on the Kata Containers Performance on ARM talk! I'm very excited by the recent developments in lightweight VMs like @katacontainers as well as ARM arriving in the cloud via Graviton at @awscloud
#CloudNativeCon #KubeCon
#CloudNativeCon #KubeCon

I love interactive demos like podtato-head (github.com/cncf/podtato-h…), because I am a kinesthetic learner-- so staring at slides does not work well for me! You can also get a feel for the different UX of each technology
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon
"What if I want Heroku but on K8s?"
KubeVela is the recommendation, using Open application Model (OAM) with developer-centric primitives, but is also highly extensible. These are the kind of abstractions I like!
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon
KubeVela is the recommendation, using Open application Model (OAM) with developer-centric primitives, but is also highly extensible. These are the kind of abstractions I like!
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon

Next, evaluating more complex use cases (where all the challenges are!) Stateful workloads, databases, external dependencies, etc, all exist in the real world. Maybe I should check out SIG App-Delivery? 🤔
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon
@resouer @AloisReitbauer
#CloudNativeCon #KubeCon

@lbernail gives more stories on K8s scalability issues and complex problems with "How the OOM-killer Deleted my Namespace", this is gonna be fun :)
#CloudNativeCon #KubeCon
#CloudNativeCon #KubeCon

`helm upgrade` remove a resource from chart deletes it from the cluster, but why did it takes 4 days? 🤔
#CloudNativeCon #KubeCon @lbernail
#CloudNativeCon #KubeCon @lbernail

If the Namespace controller can't discover all resources in the cluster, it does nothing.
Controller-manager throws an error: cannot find metrics-server
Metrics-server was OOM-killed, got restarted, then starts working again.
#CloudNativeCon #KubeCon @lbernail
Controller-manager throws an error: cannot find metrics-server
Metrics-server was OOM-killed, got restarted, then starts working again.
#CloudNativeCon #KubeCon @lbernail

But why was metrics-server failing in the first place?
Metrics-server deployed on cluster with old and new nodes, issue with image change. Scheduled onto "bad" node.
#CloudNativeCon #KubeCon @lbernail
Metrics-server deployed on cluster with old and new nodes, issue with image change. Scheduled onto "bad" node.
#CloudNativeCon #KubeCon @lbernail


Next issue: Rolling out a new image, and Nodes became NotReady after a few days. Weird because not related to kubelet or runtime.
Why? `describe nodes` shows container runtime is down, but containerd is fine.
After looking at the kubelet logs, they find an error
@lbernail
Why? `describe nodes` shows container runtime is down, but containerd is fine.
After looking at the kubelet logs, they find an error
@lbernail

Noticed that there is lock logic in CNI and it is hanging.
Take a goroutine dump to find blocked goroutines.
Able to reproduce the issue with a blocked Delete command and tracked it to a bug in the netlink library used by the Lyft CNI plugin (wow, so low level!)
@lbernail
Take a goroutine dump to find blocked goroutines.
Able to reproduce the issue with a blocked Delete command and tracked it to a bug in the netlink library used by the Lyft CNI plugin (wow, so low level!)
@lbernail



How a single app can overwhelm the control plane (this one sounds familiar to me...)
Starts with Apiservers unhealthy and cannot reach etcd, etcd getting OOM-killed. There was a spike in requests, esp. list calls (very expensive)
@lbernail #KubeCon #CloudNativeCon
Starts with Apiservers unhealthy and cannot reach etcd, etcd getting OOM-killed. There was a spike in requests, esp. list calls (very expensive)
@lbernail #KubeCon #CloudNativeCon



List calls when there is NO resourceVersion bypasses the cache and reads directly against etcd (o no...)
Setting RV=0 (much faster, filters on cache) vs RV=""
Note: Informers are much better than List b/c of cache behavior
@lbernail #KubeCon #CloudNativeCon
Setting RV=0 (much faster, filters on cache) vs RV=""
Note: Informers are much better than List b/c of cache behavior
@lbernail #KubeCon #CloudNativeCon


Wow, maybe `kubectl get` should allow setting RV=0? 🤔
BACK TO THE INCIDENT: WHODUNNIT?
K8s audit logs: a single user is responsible: nodegroup controller, with a recent upgrade that checks pods for deletion protection (with LIST...) 🙃
@lbernail #KubeCon #CloudNativeCon
BACK TO THE INCIDENT: WHODUNNIT?
K8s audit logs: a single user is responsible: nodegroup controller, with a recent upgrade that checks pods for deletion protection (with LIST...) 🙃
@lbernail #KubeCon #CloudNativeCon

Learnings:
- apiservice extensions are sus
- weird low-level issues are sus
- large clusters are sus
@lbernail #KubeCon #CloudNativeCon
- apiservice extensions are sus
- weird low-level issues are sus
- large clusters are sus
@lbernail #KubeCon #CloudNativeCon

I wasn't able to watch @robertjscott's talk on AZ-Aware routing but read the slides; this is Very Important if you are running in multiple zones/regions!
1. Standardized topology labels
2. Topology Aware Routing
3. Performance and Scalability (via EndpointSlice)
#KubeCon
1. Standardized topology labels
2. Topology Aware Routing
3. Performance and Scalability (via EndpointSlice)
#KubeCon

Next talk: 10 More Weird Ways to Blow Up Your Kubernetes @AirbnbEng with Jian Cheung and Joseph Kim
More on the theme of learning from incidents :)
First issue: 56k replicasets in one namespace
We were testing a new feature (related to zone topology)
#KubeCon
More on the theme of learning from incidents :)
First issue: 56k replicasets in one namespace
We were testing a new feature (related to zone topology)
#KubeCon


Mutating time bomb:
Something weird going on HPA and replicasets
Back to initial error: patch bug with mutating admission controller
#KubeCon
Something weird going on HPA and replicasets
Back to initial error: patch bug with mutating admission controller
#KubeCon


Zero to Autoscaling AKA Autoscaling Edges Cases:
When migrating to HPA, you can scale down to zero:
- when current replicas is 0, 1
- when migrating deployment logic (e.g. to Spinnaker)
- when using alternative "deploy" methods (e.g. kubectl scale)
#KubeCon #CloudNativeCon
When migrating to HPA, you can scale down to zero:
- when current replicas is 0, 1
- when migrating deployment logic (e.g. to Spinnaker)
- when using alternative "deploy" methods (e.g. kubectl scale)
#KubeCon #CloudNativeCon



K8s Master Issues:
- Do NOT drain the masters, unless you want to play 52 card pickup
- Running out of memory -> alerts firing everywhere -> everyone ssh loses access to nodes (o no...)
A single large service deploy that is CrashLooping (esp. with high maxSurge) is problematic
- Do NOT drain the masters, unless you want to play 52 card pickup
- Running out of memory -> alerts firing everywhere -> everyone ssh loses access to nodes (o no...)
A single large service deploy that is CrashLooping (esp. with high maxSurge) is problematic
Meanwhile, keeping an eye on KubeVela, this looks really legit. Has anyone used it?
#KubeCon #CloudNativeCon
#KubeCon #CloudNativeCon

Next Blow up: kube2iam blows us up, again
AWS Auth & Kubernetes Do Not Always Play Nice
#KubeCon #CloudNativeCon
AWS Auth & Kubernetes Do Not Always Play Nice
#KubeCon #CloudNativeCon

Even if you use all the CPU cores on a machine, you can still get throttled 🙃
Doesn't affect performance too much, but we learned a lot about throttled periods and what to actually measure.
#KubeCon #CloudNativeCon
Doesn't affect performance too much, but we learned a lot about throttled periods and what to actually measure.
#KubeCon #CloudNativeCon

One of my favorite outages: JVM Garbage collection behavior & CPU throttling leads to catastrophic OOMs
Lots of learnings from JVM tuning, adjusting CPU throttling behavior/metrics, to adjusting backpressure (esp. in service proxy / envoy layer)
#KubeCon #CloudNativeCon
Lots of learnings from JVM tuning, adjusting CPU throttling behavior/metrics, to adjusting backpressure (esp. in service proxy / envoy layer)
#KubeCon #CloudNativeCon

• • •
Missing some Tweet in this thread? You can try to
force a refresh


