
A few months ago, I wrote an economics dissertation on whether machine learning models are getting harder to find. Here’s a summary of what I found:
Some background. @ChadJonesEcon, @johnvanreenen and others wrote an awesome article that found that ideas are getting harder to find: in semiconductors, agricultural production and medicine, research productivity has been declining steadily.
In my dissertation, I explored to how this story holds up for machine learning. I used a dataset on the top performing ML models on 93 machine learning benchmarks—mostly related to computer vision and NLP—and data on research input derived from data on publications.
Standard R&D-based growth models imply a tight relationship between technological progress and research effort. I exploited this to estimate a ‘knowledge production function’—commonly found in macro models—that describes how tech evolves with stock of existing knowledge.
I found that the marginal returns of researchers are rapidly declining. There is what’s called a “standing on toes” effect: researcher productivity declines as the field grows. Because ML has recently grown very quickly, this makes better ML models much harder to find. 

On the other hand, I find that progress now makes progress in the future easier. This is called a “standing-on-the-shoulders” effect (innovations today are bootstrapped by previous progress).
A “standing-on-the-shoulders” effect in ML is on the whole not that surprising: it seems that finding one approach to solving one task can often be repurposed to solve other, related tasks (e.g. transformers, attention, etc.)
There are thus two conflicting effects: Adding researchers today results in reduced productivity of other researchers (a “standing-on-toes” effect). OTOH, additional researchers can make future researchers more productive by enabling them to ‘stand on their shoulders’.
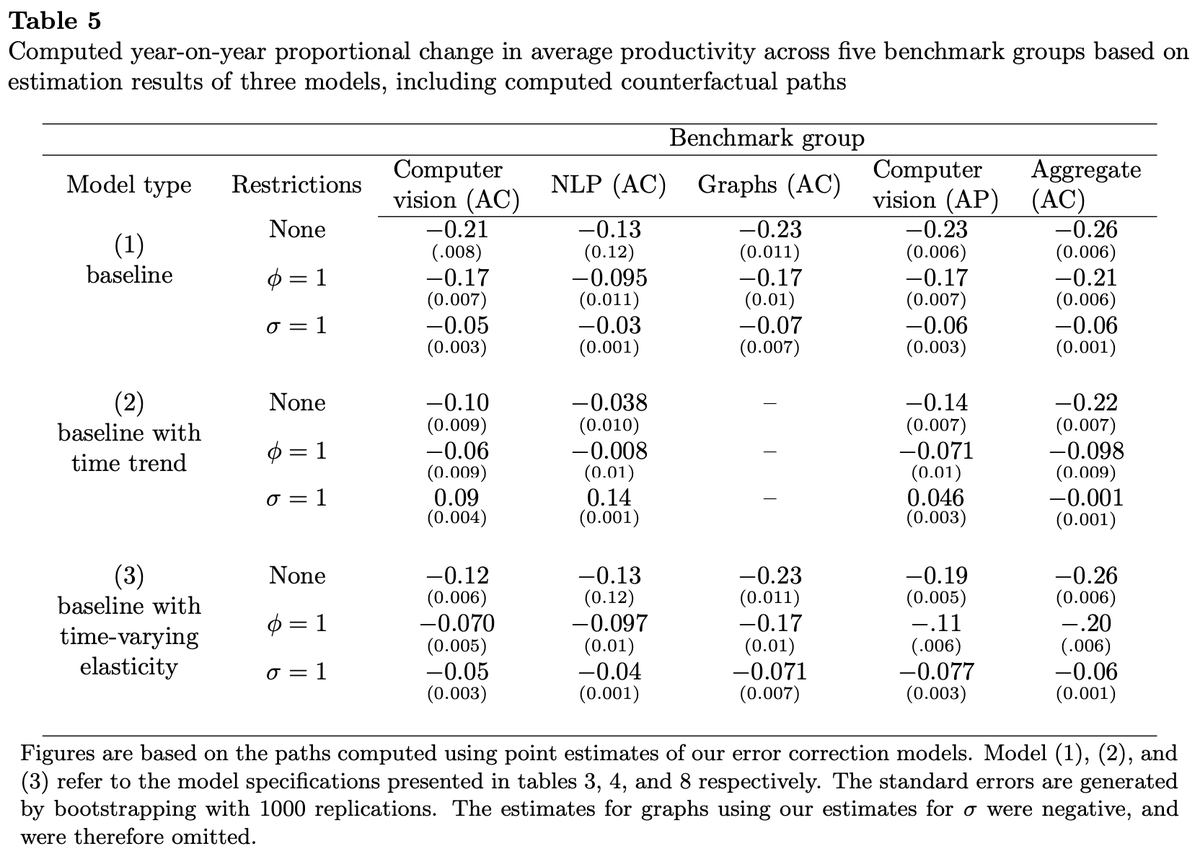
It turns out that the “standing-on-toes” effect dominates. I estimate that overall research productivity declined by between 4% to 26% (depending on which sub-field and which model).
This is in line with (if not slightly higher than) @ChadJonesEcon, @johnvanreenen et al. Part of this drop in productivity is due to it becoming harder to beat SOTA performance on benchmarks that are close to ideal performance (e.g. nearing 100% accuracy), but most of it isn’t.
I compute counterfactual technology paths, to see what would have happened if getting closer to ideal performance did not negatively affect researcher productivity, and still mostly find yearly % declines of productivity in the double digits.
References. @ChadJonesEcon, @johnvanreenen's awesome paper: aeaweb.org/articles?id=10…
My dissertation can be accessed here: tamaybesiroglu.com/s/AreModels.pdf
My dissertation can be accessed here: tamaybesiroglu.com/s/AreModels.pdf
• • •
Missing some Tweet in this thread? You can try to
force a refresh


