Snippet 1 from the #NeurIPS2020 tutorial: @balajiln What do we mean by uncertainty and out-of-distribution robustness? nips.cc/virtual/2020/t… 


Snippet 2: On even simple benchmarks, neural networks are not only poor at generalizing to OOD but also degrade in their uncertainty estimates.

Snippet 3: There are a number of applications where uncertain & robust methods are already being used. It's at the heart of many AI & ML areas.

Snippet 4: @balajiln How do we measure the quality of uncertainty? Here's a toy example for weather forecasting.

Snippet 5: @balajiln Another popular way is to examine proper scoring rules, which assess the fit to the overall data distribution.

Snippet 6: @balajiln How do we measure the quality of robustness? For benchmarks, evaluate models according to a _general_ collection of shifts. This assesses the model's ability to be invariant to many real-world OOD (different magnitudes and OOD types). Don't overfit to one.

Snippet 7: @latentjasper Neural nets with SGD capture data uncertainty well, fitting an overall distribution to the data. But it doesn't capture model uncertainty.

Snippet 8: @latentjasper Probabilistic machine learning in one slide

Snippet 9: @latentjasper Bayesian neural networks with SGD follow a simple recipe. Check out the Approximate Inference symposium to dive even deeper approximateinference.org

Snippet 10: @latentjasper You can explicitly reason about predictive behavior by examining the NN correspondence to Gaussian processes.

Snippet 11: @latentjasper A perhaps more intuitive approach for model uncertainty is ensemble learning. Just build a collection of models and aggregate.

Snippet 12: @latentjasper Bayes and ensembles are not simply special cases of one another, enabling categorical wins for both fields. Important to understand each modality to analyze problems!

Snippet 13: @latentjasper To get Bayesian models to work well requires important considerations, e.g., interpretation, training dynamics, model specification.

Snippet 14: @latentjasper There are a number of simple baselines to try: temperature scaling, MC dropout, deep ensembles, hyperparameter ensembles, bootstrap, SWAG.

Snippet 15: @latentjasper Bootstrap flat out doesn't work for deep nets. Check out a very relevant @NeurIPS2020 workshop: …cant-believe-its-not-better.github.io @AaronSchein

Snippet 16: What's the core vision for uncertainty & robustness? Continually improve our methods as we move further in the age of computing

Snippet 17: Two recent directions advancing this frontier: marginalization, which aggregates multiple network predictions; and priors & inductive biases, which engrain predictive invariances with respect to shift.

Snippet 18: For marginalization, advance the frontier by understanding ensembles as a giant model. How do we better share information across the network?

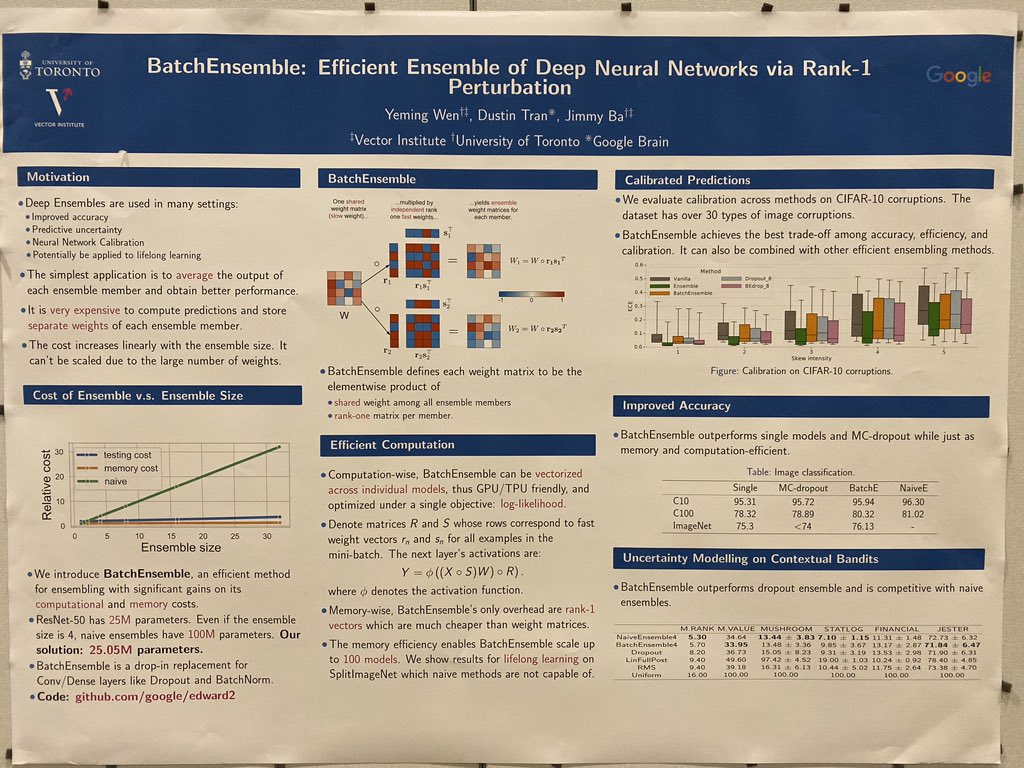
Snippet 19: Bridge this gap by sharing parameters. Apply low-rank weight perturbations to decorrelate individual ensemble members!

Snippet 20: An simpler approach suggests obtaining strong ensembles may be possible purely through implicitly learned subnetwork paths. Treat the overall ensemble as a single model. But no perturbations required.

Snippet 21: How do we specify the prior? So.... many.. challenges. Thinking about functional behavior is often the most intuitive! But how do you actually enforce such behavior?

Snippet 21: Stop thinking about just probability distributions. Leverage the inductive biases of core DL techniques like data augmentation. They precisely encourage functional behavior!
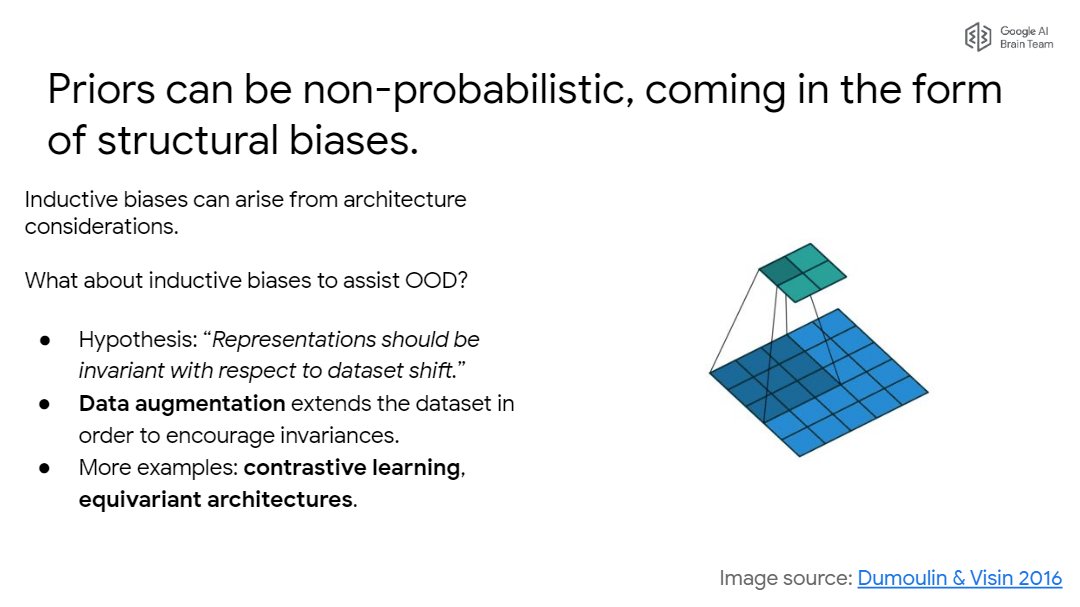
Snippet 23: Another important invariance to capture: distance awareness!

Snippet 24: Open challenge of scale. This raises both existential questions and huge opportunities for robustness (diverse tasks) and uncertainty (model parallelism).

Snippet 25: Open challenge of understanding. We're on the cusp of breakthroughs bridging the gap from theory to practice with progress in analyses like generalization theory of deep nets.

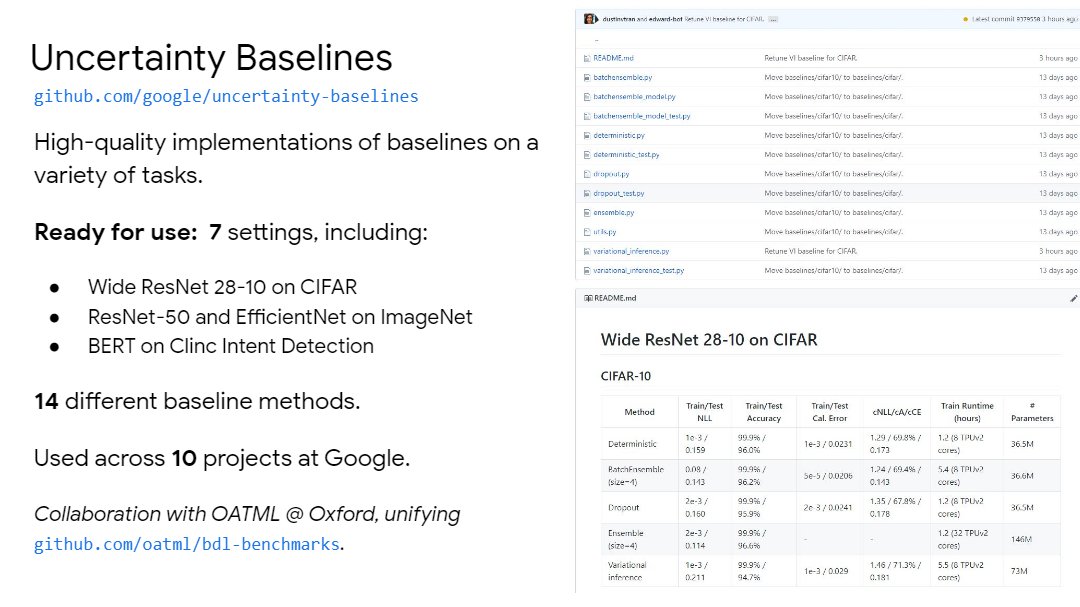
Snippet 26: Open challenge of benchmarks. Announcing Uncertainty Baselines lead by
@zacharynado
to easily build upon well-tuned methods! Joint effort with
@OATML_Oxford github.com/google/uncerta…
@zacharynado
to easily build upon well-tuned methods! Joint effort with
@OATML_Oxford github.com/google/uncerta…
Snippet 27: Open challenge of benchmarks. Announcing Robustness Metrics lead by @MarioLucic_ & Josip Djolonga to comprehensively study the robustness of DL models. Check it out to evaluate your trained models. github.com/google-researc…

• • •
Missing some Tweet in this thread? You can try to
force a refresh