In typical space-cowboy style, @ylecun, donning no slides, but only a whiteboard on Zoom, explains how all the various self-supervised models can be unified under an Energy Based view. #NeurIPS #SSL workshop 

In fact, @ylecun sketches that the probabilistic view of loss functions for self-supervised training is harmful us as it concentrates all probability mass on the data manifold, obscuring our navigation in the remaining space. #NeurIPS #SSL workshop
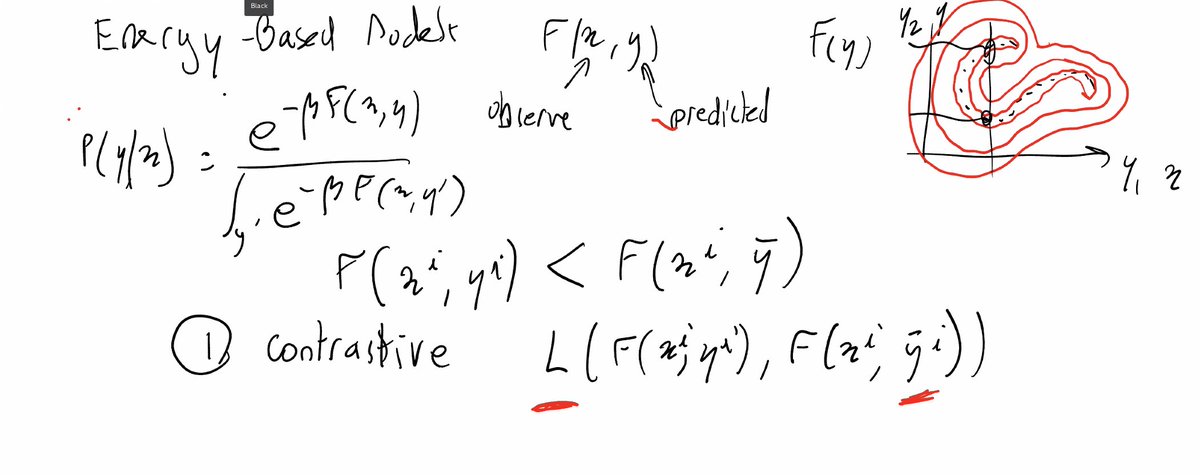
En passant, @ylecun points out the trick why BYOL by Grill et al. from @DeepMind does not collapse despite the lack of negative examples: a magic batch normalization.
And @ylecun, off the cuff, conjectures a hidden connection between contrastive learning and GAN's... to be continued for sure. #NeurIPS2020. One could argue that a pretty decent keynote for #SSL workshop...
Unless that red thing is actually Trump's hairdo manifold...
• • •
Missing some Tweet in this thread? You can try to
force a refresh


