
Yesterday, I ended up in a debate where the position was "algorithmic bias is a data problem".
I thought this had already been well refuted within our research community but clearly not.
So, to say it yet again -- it is not just the data. The model matters.
1/n
I thought this had already been well refuted within our research community but clearly not.
So, to say it yet again -- it is not just the data. The model matters.
1/n
We show this in our work on compression.
Pruning and quantizing deep neural networks amplifies algorithmic bias.
arxiv.org/abs/2010.03058 and arxiv.org/abs/1911.05248
Pruning and quantizing deep neural networks amplifies algorithmic bias.
arxiv.org/abs/2010.03058 and arxiv.org/abs/1911.05248
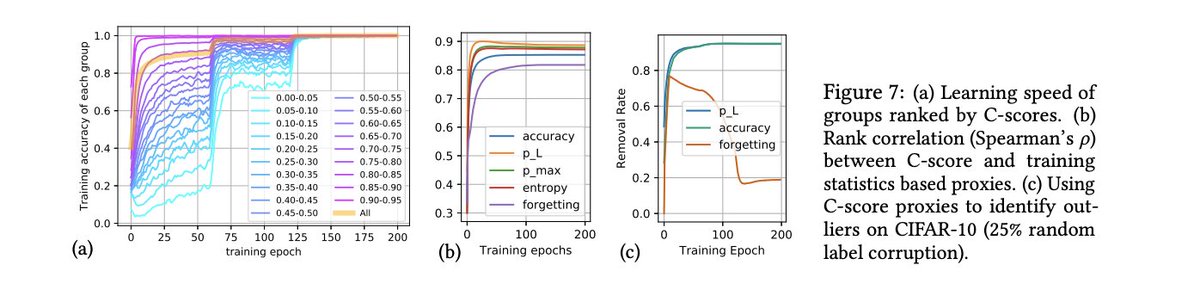
Work on memorization and variance of gradients (VoG) shows that hard examples are learnt later in training, and that learning rates impact what is learnt.
bit.ly/2N9mW2r, arxiv.org/abs/2008.11600
So, early stopping disproportionately impacts certain examples.
bit.ly/2N9mW2r, arxiv.org/abs/2008.11600
So, early stopping disproportionately impacts certain examples.
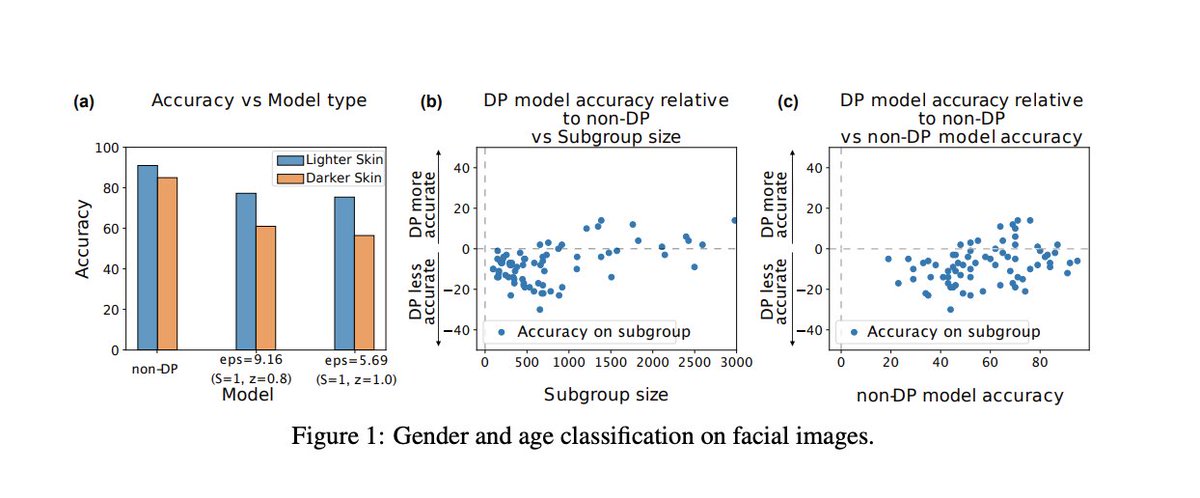
Models which are guaranteed to be differentially private introduce disparate impact on model accuracy.
arxiv.org/pdf/1905.12101… and
bit.ly/3dgOfCs
arxiv.org/pdf/1905.12101… and
bit.ly/3dgOfCs
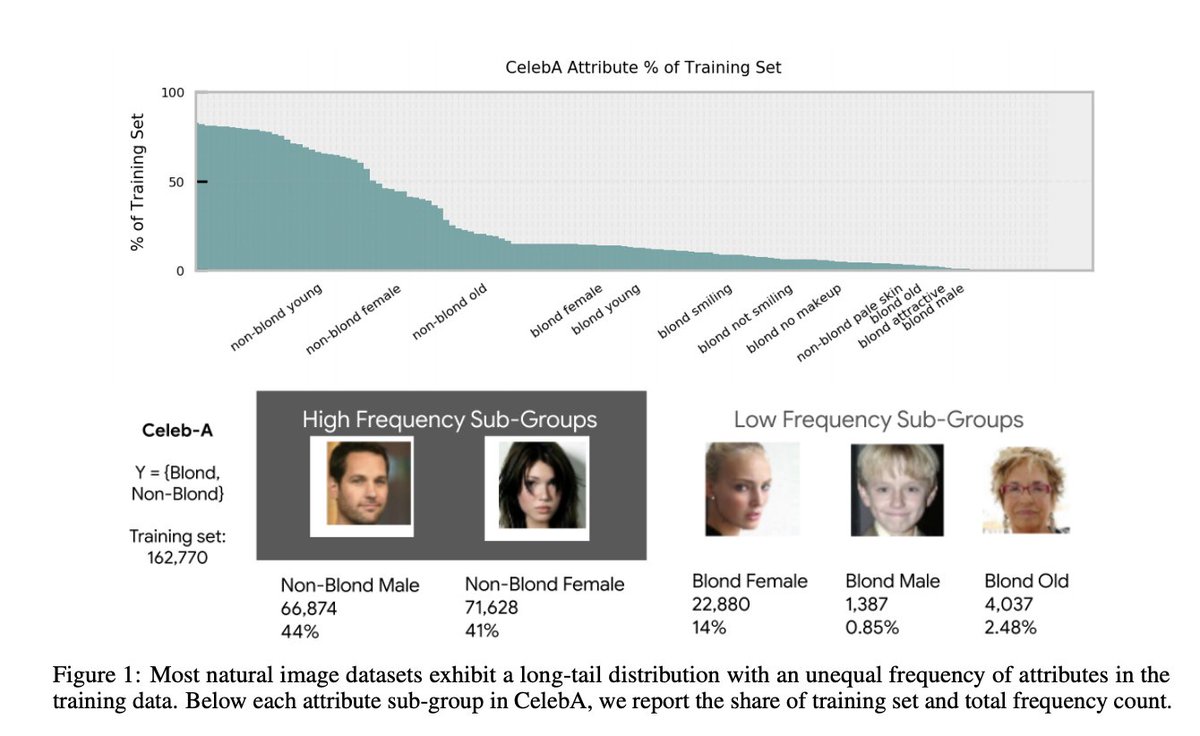
One of the reasons the model matters is because notions of fairness often coincide with how underrepresented features are treated.
Treatment of the long-tail appears to depend on many factors, including memorization bit.ly/3qnru3v, capacity and objective.
Treatment of the long-tail appears to depend on many factors, including memorization bit.ly/3qnru3v, capacity and objective.
So, let's dissuade ourselves of the incorrect notion that the model is independent from considerations of algorithmic bias.
This simply isn't the case. Our choices around model architecture, hyper-parameters and objective functions all inform considerations of algorithmic bias.
This simply isn't the case. Our choices around model architecture, hyper-parameters and objective functions all inform considerations of algorithmic bias.
These were a few quick examples -- but plenty of important scholarship I have not included in this thread -- including important work on the relationship between robustness and fairness. A welcome invite to add on additional work which is considering these important trade-offs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



