Happy to share our new preprint with Edwin de Beurs, in which we recommend to solve the current dilemma "So-Many-Scales-For-The-Same-Construct" (e.g. for depression) by mandating a common metric, not by mandating a common measure.🧵
psyarxiv.com/m4qzb/
psyarxiv.com/m4qzb/
We introduce the problem of scale proliferation, and how it impacts not only science, but also communication (between researchers & policy makers; between clinicians; between clinicians & clients; etc).
A harmonization proposal is to mandate specific measures (e.g. PHQ9 for depression), introduced by @wellcometrust @NIH @mirandarwolpert.
@pravpatalay & I discuss the challenges of this approach in detail here:
acamh.onlinelibrary.wiley.com/doi/full/10.11…
@pravpatalay & I discuss the challenges of this approach in detail here:
acamh.onlinelibrary.wiley.com/doi/full/10.11…
In our new piece, Edwin & I instead suggest common metrics similar to IQ scores: independent of the specific instrument, and simplify communication.
We introduce several metrics, and focus on T-Scores & Percentile Ranks, discussing their calculation, merits & shortcomings.
We introduce several metrics, and focus on T-Scores & Percentile Ranks, discussing their calculation, merits & shortcomings.
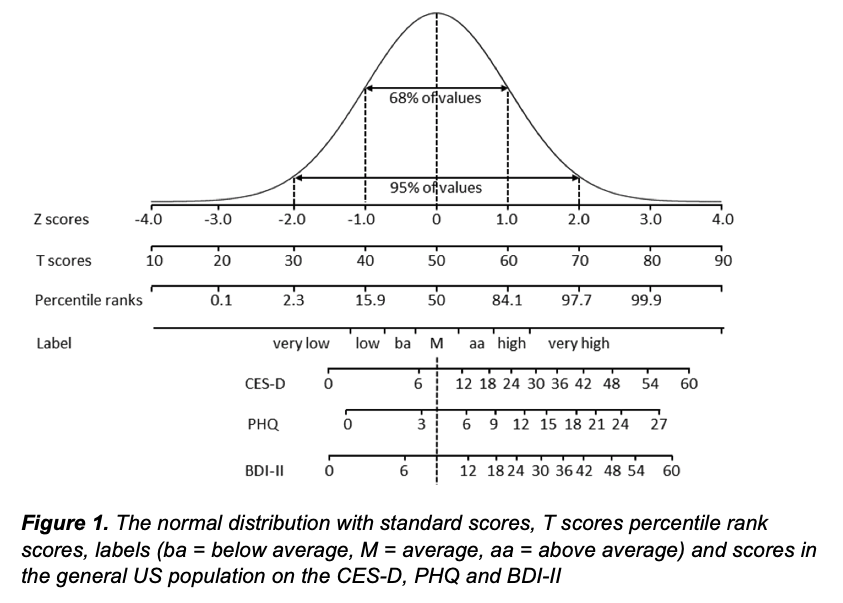
We provide empirical examples using 3 depression questionnaires to demonstrate the current confusion, and the benefits and utility of common metrics.
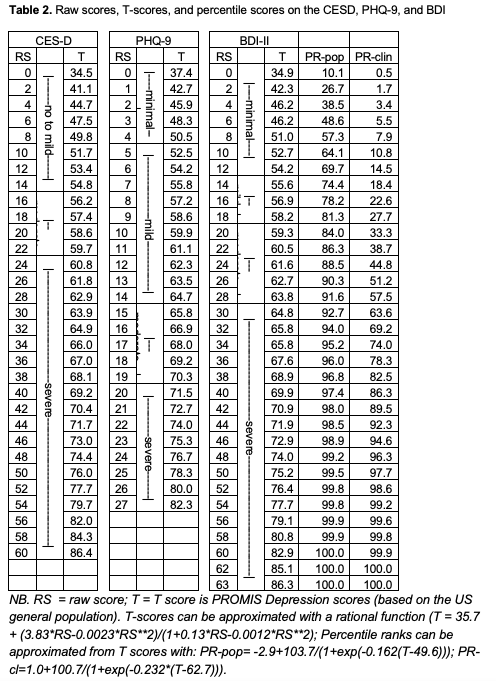
We conclude that T-scores & percentile ranks may aid measure harmonization & interpretation of test results, enhance the communication about tests results among professionals, and ease explaining their meaning to clients.
Curious to hear your thoughts! End 🧵
Curious to hear your thoughts! End 🧵

PS: Massive shoutouts to @pravpatalay whose previous work on this was a big inspiration for Edwin & me to think about common metrics, & to @mirandarwolpert for starting a public debate on this issue in clinical psych!
PS2: I expect some pushback on this proposal from a content validity perspective. Would be really interested in your thoughts on this. I.e. can you harmonize X Y and Z if they aim to measure the same thing, but they don't actually do so?
Lots of responses already, thanks so much! My view: Standard scores allow us to see how *exceptional* a test result is, independent of the content it measures. E.g. you can compare how exceptional someone is on 3 IQ subtests, even if these subtests are uncorrelated.
This allows you to compare the result of scales assessing different constructs, or scales aiming (but failing) to assess the same. What we gain from comparing Standard scores of personality scale vs PTSD scale isn't clear to me, but of course it can be done.
But facing the reality of current measure chaos, there seems a lot to be gained from comparing T-Scores of mental health measures, especially considering that they are usually moderately correlated with each other and impairment; and that psychopathology is transdiagnostic.
Some methodological ways to address this were proposed in the thread. I'll be looking into these in some detail and see if I can provide a response. Maybe the paper would also lend itself to a few commentaries, Gary already proposed one: "jingle-jangle on steroids" ;)
• • •
Missing some Tweet in this thread? You can try to
force a refresh