
Sigmoid is one of most commonly used activation functions.
However, it has a serious weakness: Sigmoids often make the gradient disappear.
This can leave the network stuck during training, so they effectively stop learning.
How can this happen?
🧵 👇🏽
However, it has a serious weakness: Sigmoids often make the gradient disappear.
This can leave the network stuck during training, so they effectively stop learning.
How can this happen?
🧵 👇🏽
Let's take a look at the Sigmoid function first.
Notice below that as 𝑥 tends to ∞ or -∞, the function flattens out.
This can happen for instance when the previous layer separates the classes very well, mapping them far away from each other in the feature space.
Notice below that as 𝑥 tends to ∞ or -∞, the function flattens out.
This can happen for instance when the previous layer separates the classes very well, mapping them far away from each other in the feature space.
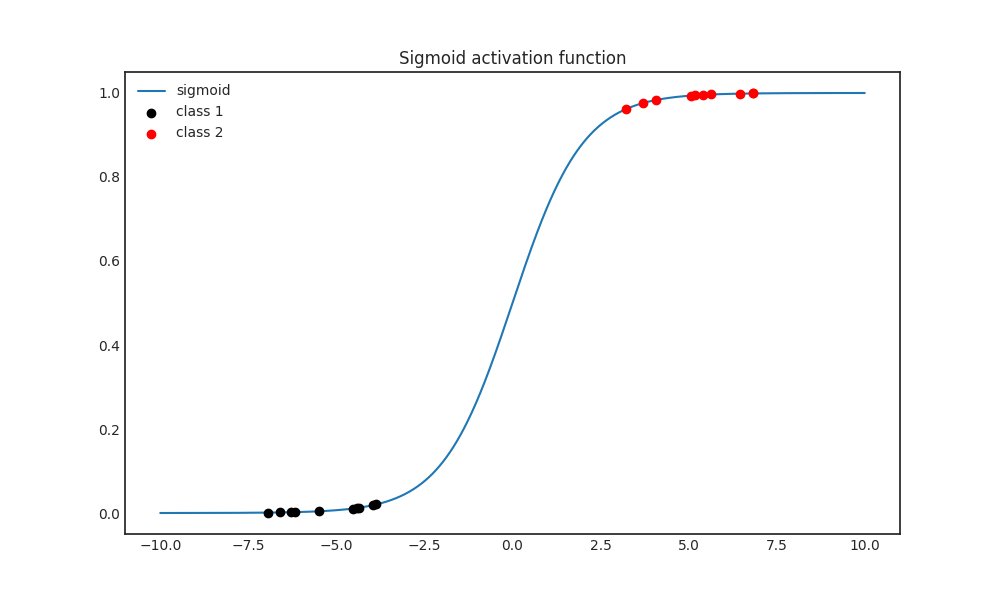
Why is this a problem?
Flatness means that the derivative is close to zero, as shown in the figure below.
Flatness means that the derivative is close to zero, as shown in the figure below.

However, a neural network just a series of function compositions. (Each layer is a function.)
Because of the chain rule, a single small derivative can have a huge impact on the magnitude of the gradient.
This phenomenon is called "vanishing gradients".
Because of the chain rule, a single small derivative can have a huge impact on the magnitude of the gradient.
This phenomenon is called "vanishing gradients".

When this happens, the weight updates are going to be extremely tiny. In essence, the network stops learning at this point.
How can this be fixed?
Simple: with activation functions without vanishing derivatives :)
How can this be fixed?
Simple: with activation functions without vanishing derivatives :)
Back in the day, ReLU (short for Rectified Linear Unit), was created exactly to solve this problem.
Eventually, ReLU also turned to be problematic, since it can cause neurons to "die" and stop being updated.
Eventually, ReLU also turned to be problematic, since it can cause neurons to "die" and stop being updated.
In the end, there is no single activation function that works the best in every setting.
Finding one to suit the task is a matter of experimentation, like many things regarding machine learning.
Finding one to suit the task is a matter of experimentation, like many things regarding machine learning.
• • •
Missing some Tweet in this thread? You can try to
force a refresh








