
Akurasi bagus nggak menjamin modelnya pasti bagus juga. Kok bisa?
Confusion Matrix: In a Nutshell
.
.
.
A thread
Confusion Matrix: In a Nutshell
.
.
.
A thread
Suatu hari, seorang data scientist diminta klien dari sebuah rumah sakit untuk membangun sebuah model machine learning yang bisa mendeteksi dini adanya gejala tumor otak pada pasien balita 

Lalu singkat cerita, data selesai di preprocessing dan modeling selesai. Pertanyaannya, kira-kira gimana cara si DS bisa mengukur performa modelnya? Cukupkah akurasi yang tinggi bisa membuat dia bilang ke klien kalau modelnya ‘works well’?
The problem is, kasus yang diprediksi -- balita penderita tumor otak -- itu secara statistik sendiri jarang banget terjadi lho temen-temen.
Statistically speaking, dari 100.000 balita, peluang terdiagnosis kanker itu ada 23 anak. Dan dari 23 anak tersebut, hanya 5 anak yang berpeluang terdiagnosis kanker tumor otak. Artinya apa? Datanya juga akan sangat minim dibandingkan dengan data balita sehat.
Kasus ini disebut juga dengan kasus data yang imbalanced. Nah, kasus yang seperti ini bisa juga nih jadi contoh di mana performa model yang sebenarnya mungkin aja nggak bisa terukur hanya dengan akurasi nya. So, terus gimana?
Yess, this is when the confusion matrix comes to the rescue!
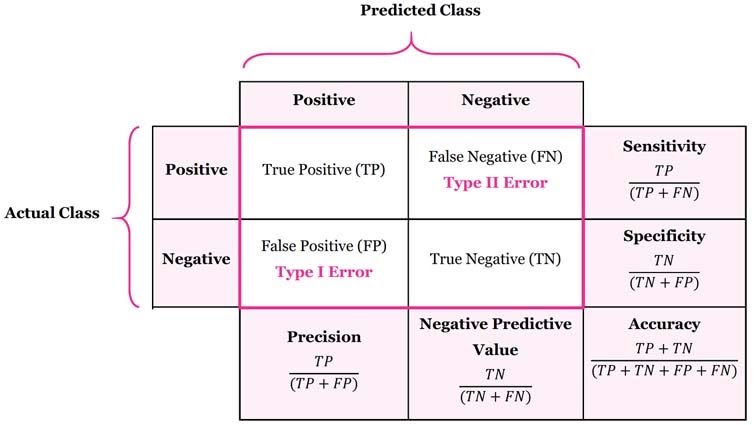
In a nutshell, confusion matrix adalah sebuah matriks yang isinya berupa evaluasi kinerja model secara keseluruhan. Confusion matrix biasanya berbentuk tabel atau matriks 2x2 untuk klasifikasi biner, meskipun bisa juga untuk klasifikasi multi kelas (nxn).
Layaknya raport semesteran, confusion matrix nunjukkin gimana sih performa model selama menjalani proses pembelajaran? Apakah model sudah memiliki kompetensi mengklasifikasikan kelas dengan baik atau masih banyak bingungnya? (bingung ~> confusion)
Untuk membuat confusion matrix, hasil prediksi model saat training kita catat dan agregatnya dipetakan ke dalam tabel yang berisi kombinasi dari kelas hasil ‘perkiraan’ model dengan kelas ‘sebenarnya’.

Nah ada 4 kemungkinan: model menebak kelas positif dan benar (True Positive), model menebak kelas positif tapi sayangnya salah (False Positive), model menebak kelas negatif dan benar (True Negative), serta model menebak kelas negatif tapi salah (False Negative)

Dari tebakan yang salah (False), ada 2 tipe error atau kesalahan: Type I Error (False Positive) dan Type II Error (False Negative). Nah, konsep ini yang nanti akan kita pakai lagi, so diinget yaa!

As a side note, nama kelas ‘Positif’ atau ‘Negatif’ dan posisi sumbunya ini arbitrary, sok bisa diganti sesuai kebutuhan, konteks, dan selera. Buat klasifikasi email spam nih misalnya, mungkin aja diperoleh confusion matrix seperti ini.

Kita bisa eksplor banyak hal tentang model kita dari confusion matrix. Salah satunya mengevaluasi performa model dengan beraneka performance metrics yang bisa diturunkan dari confusion matrix ini. Apa aja? Yuk, kita kupas satu persatu!
Pertama-tama dan yang paling utama, siapa coba yang nggak kenal sama yang satu ini, accuracy! Nah sederhananya, accuracy (akurasi) adalah metrics yang nunjukkin: dari SEMUA prediksi model, berapa banyak sih yang bener?

Dari model klasifikasi spam tadi, kalau dihitung diperoleh accuracy = (45+30)/(45+20+5+30) = 75%. Artinya, dari semua hasil tebakan model, banyaknya tebakan yang benar itu 75%.
Sifatnya yang sangat general ini mungkin yang membuat accuracy jadi metrics yang paling dikenal dan sering digunakan untuk evaluasi model secara umum. Padahal selain accuracy, ada lagi lho metrics yang nggak kalah gokilnya, precision!

Kalau precision ini nunjukkin: Dari semua prediksi ‘positif’ model, berapa banyak sih yang bener? Contoh dari model spam tadi diperoleh precision = (45)/(45+5) = 90%. Itu artinya, dari semua tebakan ‘spam’ model, 90% nya itu benar-benar spam.

Serupa tapi tak sama, ada yang namanya recall! Kalau recall sendiri nunjukkin: Dari seluruh dataset kelas ‘positif’, berapa banyak sih yang ditebak ‘positif’ juga oleh model?

Kalau dalam model spam tadi, diperoleh recall = 45/(45+20) = 69.23%. Itu artinya, 69.23% dari email yang emang beneran spam, terdeteksi sebagai ‘spam’ juga oleh model. Recall dikenal juga dengan sebutan sensitivity atau true positive rate (TPR).

See, banyak banget informasi yang bisa kita peroleh dari ‘matriks kebingungan’ ini. Dari sana, kita bisa lakukan banyak hal termasuk salah satunya mengevaluasi model klasifikasi yang kita buat.
Nah dari penjelasan tadi, mungkin ada yang udah kebayang kenapa accuracy-only itu bisa misleading, apalagi kalau datanya imbalanced. Contoh sederhananya dalam kasus klasifikasi tumor otak si DS di awal tadi.
Anggap dataset terdiri dari 1000 data dengan jumlah kelas ‘normal’ sebanyak 900 data. Artinya, data kelas ‘tumor’ hanya tersedia sebanyak 100 data aja. Dengan proporsi seperti ini (90%:10%), jelas kita berhadapan dengan kasus data imbalanced.
Dalam kasus ini, tentu kita sepakat kalau model yang mengklasifikasi SEMUA DATA adalah kelas ‘normal’, is simply dumb. But believe it or not, the very same model, kalau kita liat stats accuracy-nya, kita bisa dapat 900/(900+100) = 90% accuracy!
Makanya, penting banget buat hati-hati dalam pemilihan metrics evaluasi model. Terus gimana min cara milih metrics yang sesuai? Nah, masih inget kan sama tipe-tipe error yang mimin singgung di awal? This is the time when they come in handy!

Sebenarnya, pengennya sih sebisa mungkin semua error diminimalisir, baik type I error maupun type II error. Tapi, ada kalanya salah satu error jauh lebih bahaya jika dibiarkan dibandingkan error lainnya, tergantung kasusnya masing-masing.
Contoh, dalam klasifikasi apakah suatu email ‘positif’ spam atau tidak, type I error (false positive/FP) bisa jadi jauh lebih penting daripada type II error (false negative/FN). Kenapa?
Karena kejadian ada email spam yang lolos (false negative) ke inbox mungkin lebih bisa ditoleransi, daripada ada email penting yang kesaring (false positive) dan akhirnya masuk spam dan baru kebaca 3 bulan setelah email dikirim (based on true story😀)
Nah untuk model klasifikasi kelas spam dengan asumsi kayak tadi, kira-kira metrics apa nih yang cocok buat menggambarkan seberapa powerful sih model kita?
Yess, karena kita ingin FP turun serendah mungkin, kita bisa pilih Precision sebagai metrics yang perlu kita naikkan semaksimal mungkin. Gimana, kebayang?

Another pub quiz! Kalau kasus model klasifikasi kelas tumor otak di awal tadi, kira-kira nih metrics apa yaa yang cocok buat menggambarkan performa model yang sebenarnya?
Nah, berbeda dengan spam, untuk rare disease detection, kejadian pasien yang sebenarnya menderita namun lolos screening (false negative) jauh lebih penting dibandingkan pasien sehat namun diprediksi sakit (false positive) oleh model. Kenapa?
Karena untuk kejadian false negative, pasien dengan senangnya akan pulang dan mengira bahwa dirinya baik-baik saja, tanpa mengetahui hal yang terjadi sebenarnya. Akibatnya, kanker yang diidapnya dapat terus berkembang sampai menjadi kronis.
Nah, tentu kita nggak mau dong model kita memakan korban, sehingga untuk kasus klasifikasi tumor otak ini kita usahain FN serendah mungkin. Artinya, kita bisa pilih model dengan Recall yang semaksimal mungkin agar model bekerja sesuai harapan.

Kalau FP dan FN nya sama-sama penting gimana min? Nah, metrics yang bisa dipakai salah satunya adalah F-beta. F-beta score dengan beta = 1, atau dikenal dengan F1-score, merupakan metrics yang berupa rata-rata harmonik dari Recall dan Precision.

Sebenernya masih banyaakk metrics turunan dari confusion matrix. Buat klasifikasi yang ngeluarin proba misalnya, ada ROC-AUC, kurva PR, dan lain-lain. Pengen dibahas juga tapi kayaknya threadnya udah kepanjangan hehe. Kapan kapan lagi aja yaa
Nah, insight apa nih yang bisa kita ambil?
Performance metrics itu nggak melulu soal akurasi. Accuracy is not the one and only metric yang bisa dipakai buat evaluasi model, terkhusus model klasifikasi kelas. Usahain banget milih metrics itu yang sesuai dengan konteks dan use case nya.
Selain itu, ternyata jadi DS nggak cuma tentang skill data aja, tapi juga harus paham domain knowledge dari use case yang sedang dihadapi. Artinya, DS juga harus bisa komunikasi dengan ahli di bidang terkait, baik bisnis, keuangan, maupun medis
Kalau kalian udah punya domain knowledgenya dan ingin belajar menjadi Data Scientist di bidang tersebut, yuk gabung di non degree program Data Scientist Pacmann.AI! Kalian akan belajar dari basic loh, silahkan cek kurikulumnya di bit.ly/brosurpacmannai yaa 🤩
Atau kalau mau langsung daftar, bisa banget ke bit.ly/PendaftaranNon… dan jangan lupa pakai kode EARLYBIRD3 untuk mendapatkan potongan harga hingga 500k! See you! 😊👋🏼

• • •
Missing some Tweet in this thread? You can try to
force a refresh



