1/ Last week, I did a presentation for a client that included (among other things), a discussion of DynamoDB and MongoDB.
Operational concerns aside, I think the biggest difference is this:
DynamoDB is authoritarian, while MongoDB is libertarian.
Operational concerns aside, I think the biggest difference is this:
DynamoDB is authoritarian, while MongoDB is libertarian.
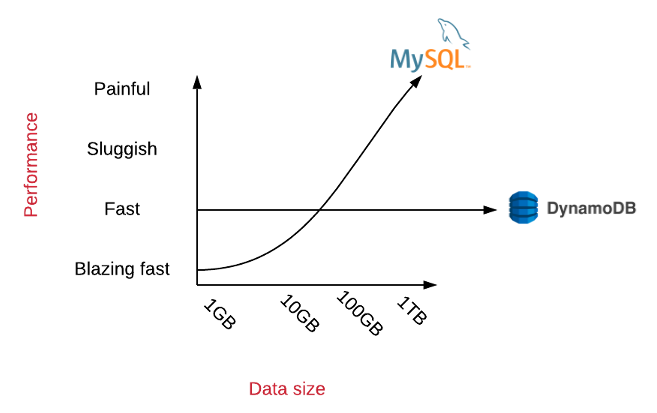
2/ If you've watched my talks, you've seen a slide like this. I like to discuss how DynamoDB partitions work and how they help keep DynamoDB performance consistent as your application scales.
For more, see my reinvent talk here:
For more, see my reinvent talk here:

3/ In DynamoDB, most requests require the partition key which immediately routes the request to the proper partition.
Because this is an O(1) operation, you can easily horizontally scale without decreasing performance.
Because this is an O(1) operation, you can easily horizontally scale without decreasing performance.

4/ MongoDB is very similar! You can shard your data across multiple nodes. Data is placed according to a user-defined shard key that assigns documents to shards.
The terminology is different (partitions vs. shards; request router vs. mongos), but the purpose is the same.
The terminology is different (partitions vs. shards; request router vs. mongos), but the purpose is the same.
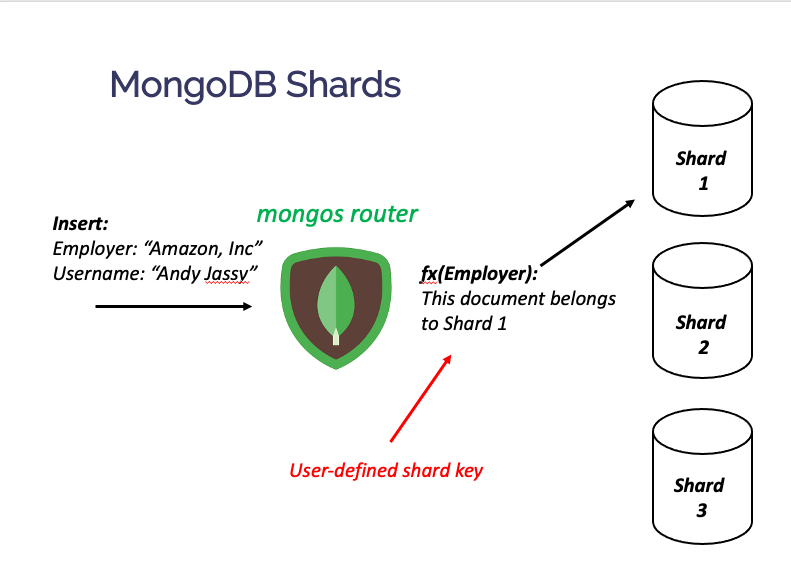
5/ For both DDB & Mongo, a request that includes the partition key or shard key is efficient. It goes directly to the relevant node and executes the operation.
Most of my DDB advice applies equally to Mongo.
The difference is for requests that *don't* have the partition key.
Most of my DDB advice applies equally to Mongo.
The difference is for requests that *don't* have the partition key.
6/ With DynamoDB, you have two choices for requests that don't have the partition key:
- Add a secondary index
- Use a Scan (not recommended).
This fits what what I call DynamoDB's guiding principle: "Do not allow operations that won't scale."
- Add a secondary index
- Use a Scan (not recommended).
This fits what what I call DynamoDB's guiding principle: "Do not allow operations that won't scale."

7/ With MongoDB, there's no such limitation. You can make a request without the shard key.
However, if you do so, it will do a scatter-gather query by hitting each of the shards individually, then combining and returning the results.
Note that this adds load to each node.
However, if you do so, it will do a scatter-gather query by hitting each of the shards individually, then combining and returning the results.
Note that this adds load to each node.

8/ MongoDB's guiding philosophy is a little different. I described it as: "Make it easy* for developers."
It could also be "Sure, why not?"
* - When I say 'easy' here, I mean to write & execute the query. There are short- & long-term costs associated with this. See next tweet.
It could also be "Sure, why not?"
* - When I say 'easy' here, I mean to write & execute the query. There are short- & long-term costs associated with this. See next tweet.

9/ There are trade-offs in everything, so there's no one answer here.
With DynamoDB, you have a short-term cost of additional modeling and a long-term cost around flexibility.
With MongoDB, you have a short-term cost of ... actual cost ... and a long-term cost of scalability.
With DynamoDB, you have a short-term cost of additional modeling and a long-term cost around flexibility.
With MongoDB, you have a short-term cost of ... actual cost ... and a long-term cost of scalability.

10/ From a data-modeling perspective, you need to choose the one that resonates with you.
And note that there are a ton of other factors -- operations model, billing model, Lambda-friendliness -- that come into play as well.
The big point is that flexibility isn't without cost!
And note that there are a ton of other factors -- operations model, billing model, Lambda-friendliness -- that come into play as well.
The big point is that flexibility isn't without cost!
• • •
Missing some Tweet in this thread? You can try to
force a refresh