
How can robots generalize to new environments & tasks?
We find that using in-the-wild videos of people can allow learned reward functions to do so!
Paper: arxiv.org/abs/2103.16817
Led by @_anniechen_, @SurajNair_1
🧵(1/5)
We find that using in-the-wild videos of people can allow learned reward functions to do so!
Paper: arxiv.org/abs/2103.16817
Led by @_anniechen_, @SurajNair_1
🧵(1/5)
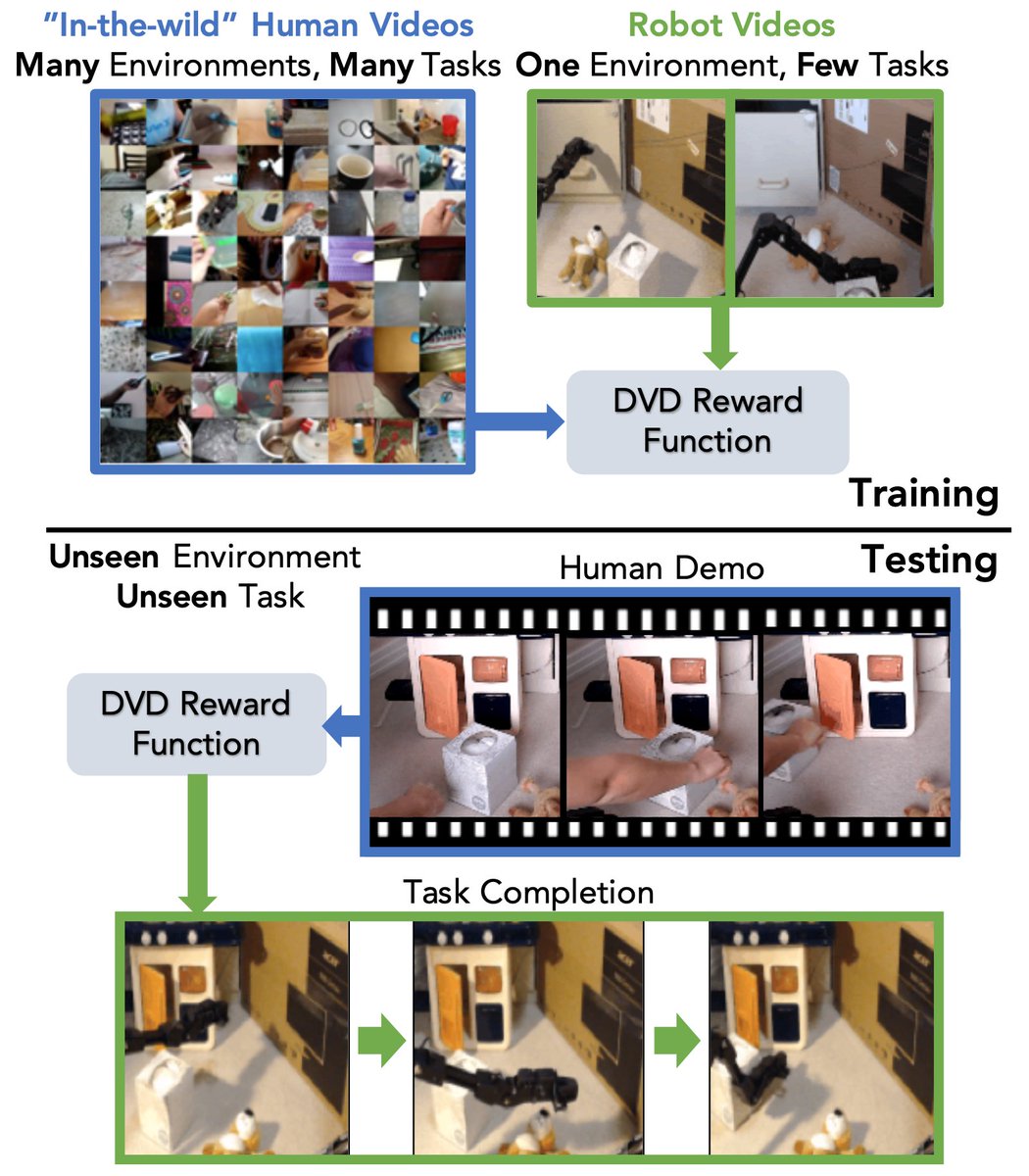
To get reward functions that generalize, we train domain-agnostic video discriminators (DVD) with:
* a lot of diverse human data, and
* a narrow & small amount of robot demos
The idea is super simple: predict if two videos are performing the same task or not.
(2/5)
* a lot of diverse human data, and
* a narrow & small amount of robot demos
The idea is super simple: predict if two videos are performing the same task or not.
(2/5)

This discriminator can be used as a reward by feeding in a human video of the desired task and a video of the robot’s behavior.
We use it by planning with a learned visual dynamics model.
(3/5)
We use it by planning with a learned visual dynamics model.
(3/5)

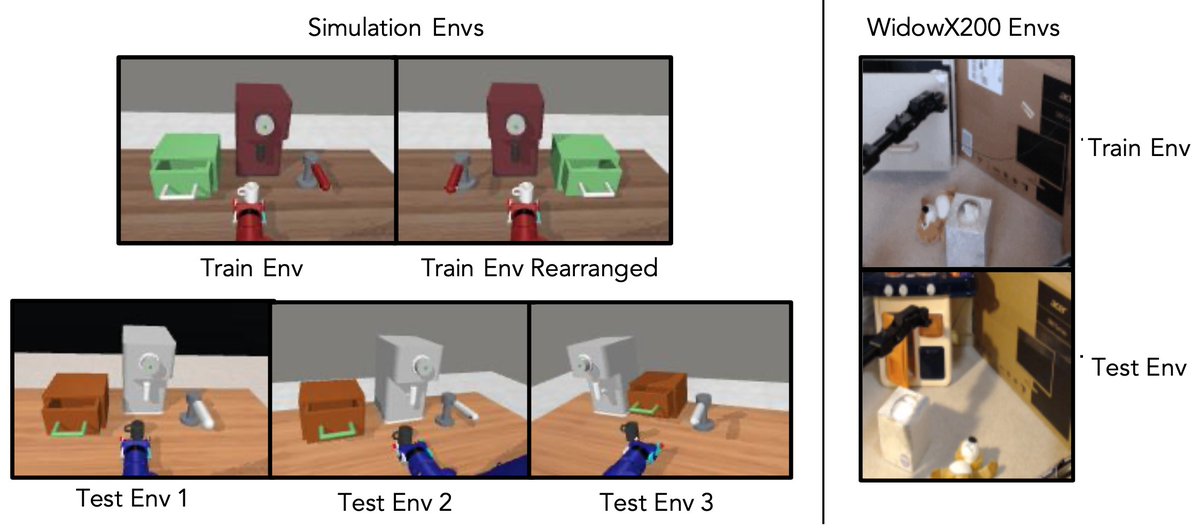
Does using human videos improve reward generalization compared to using only narrow robot data?
We see:
* 20% greater task success in new environments
* 25% greater task success on new tasks
both in simulation and on a real robot.
(4/5)
We see:
* 20% greater task success in new environments
* 25% greater task success on new tasks
both in simulation and on a real robot.
(4/5)
For more, check out:
Paper: arxiv.org/abs/2103.16817
Website: sites.google.com/view/dvd-human…
Summary video: drive.google.com/file/d/1WsOwgc…
I'm quite excited about how reusing broad datasets can help robots generalize, and this project has been a great indication in that direction!
(5/5)
Paper: arxiv.org/abs/2103.16817
Website: sites.google.com/view/dvd-human…
Summary video: drive.google.com/file/d/1WsOwgc…
I'm quite excited about how reusing broad datasets can help robots generalize, and this project has been a great indication in that direction!
(5/5)
• • •
Missing some Tweet in this thread? You can try to
force a refresh




