
This week, let's talk about model building a little.
In the TensorFlow world, the simplest way of building a model is with a Sequential model.
But what is it and how to do it?
[4 minutes]
1/9🧵
In the TensorFlow world, the simplest way of building a model is with a Sequential model.
But what is it and how to do it?
[4 minutes]
1/9🧵


First, let's go over some basics.
The goal here is to build a Neural Network, or in other words, create a set of neurons, distributed in layers and connected by weights.
Each Layer applies some computation on the values or tensors it receives.
2/9🧵
The goal here is to build a Neural Network, or in other words, create a set of neurons, distributed in layers and connected by weights.
Each Layer applies some computation on the values or tensors it receives.
2/9🧵
The simplest way to create this NN is to just do a plain stack of layers where each layer has exactly one input and one output.
This is exactly what a Sequential model does
3/9🧵
This is exactly what a Sequential model does
3/9🧵
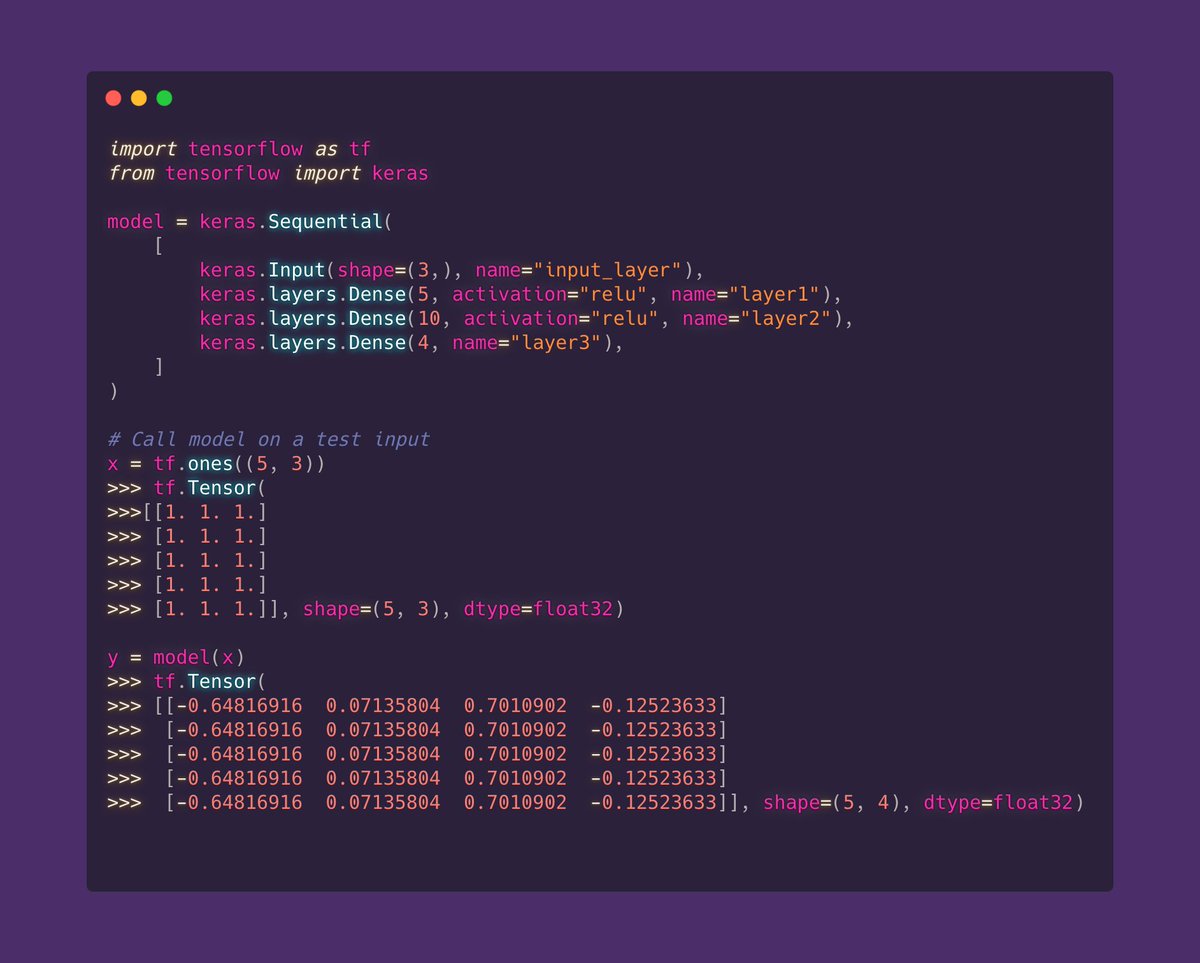
After you have your model, you can access each layer and it's weights.
You might want to do that if you want to do feature extraction for example
4/9🧵
You might want to do that if you want to do feature extraction for example
4/9🧵

You can also visualize the model structure using the summary method
This can you give some insights of the intermediate shapes and help fix issues
💡:layer1 and layer2 (or any layer that is not input or output) is also known as a hidden layer
5/9🧵
This can you give some insights of the intermediate shapes and help fix issues
💡:layer1 and layer2 (or any layer that is not input or output) is also known as a hidden layer
5/9🧵

If you want a more visual version, you can also use tf.keras.utils.plot_model(model)
This shows a more visual version of the model.
💡: Both this and the summary will work even if you build your model not using a Sequential model.
6/9🧵
This shows a more visual version of the model.
💡: Both this and the summary will work even if you build your model not using a Sequential model.
6/9🧵

You should NOT use a Sequential model when:
• Your model or any layer needs multiple inputs or outputs
• You need a non-linear model
• You need layer sharing
7/9🧵
• Your model or any layer needs multiple inputs or outputs
• You need a non-linear model
• You need layer sharing
7/9🧵
Here is a full tutorial with the code I've used: tensorflow.org/guide/keras/se…
I highly recommend going over and play with it.
It's 15 minutes that will help you.
8/9🧵
I highly recommend going over and play with it.
It's 15 minutes that will help you.
8/9🧵
This is not the only way to build a model.
I'll come back to this during the week with the other techniques.
Stay "tuned" 🤓
9/9🧵
I'll come back to this during the week with the other techniques.
Stay "tuned" 🤓
9/9🧵
• • •
Missing some Tweet in this thread? You can try to
force a refresh






