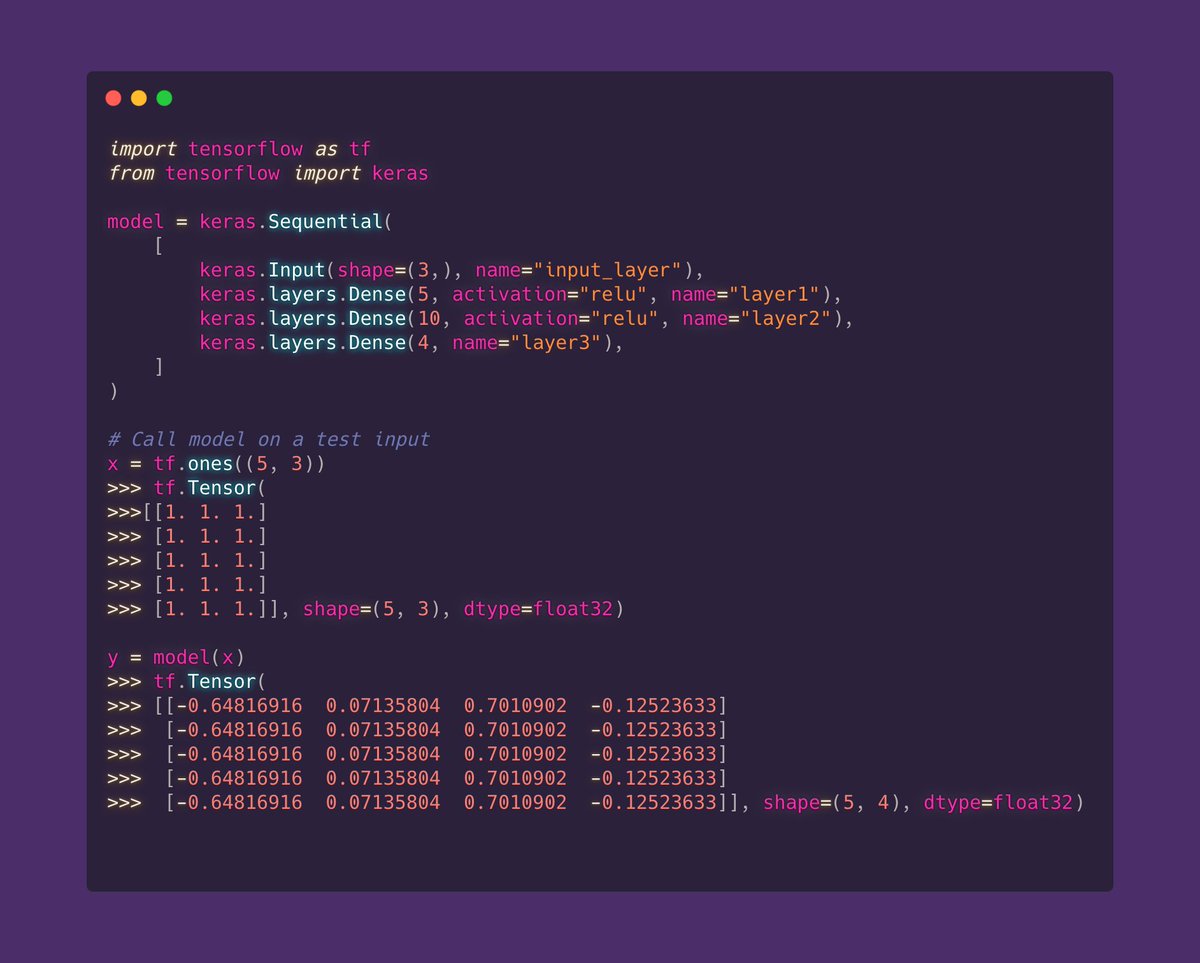
Sometimes you need to build a Machine Learning model that cannot be expressed with the Sequential API
For these moments, when you need a more complex model, with multiple inputs and outputs or with residual connections, that's when you need the Functional API!
[2.46 min]
1/8🧵
For these moments, when you need a more complex model, with multiple inputs and outputs or with residual connections, that's when you need the Functional API!
[2.46 min]
1/8🧵
The Functional API is more flexible than the Sequential API.
The easiest way to understand is to visualize the same model created using the Sequential and Functional API
2/8🧵
The easiest way to understand is to visualize the same model created using the Sequential and Functional API
2/8🧵


You can think of the Functional API as a way to create a Directed Acyclic Graph (DAG) of layers while the Sequential API can only create a stack of layers.
Functional is also known as Symbolic or Declarative API
3/8🧵
Functional is also known as Symbolic or Declarative API
3/8🧵

Thinking with the Graph creation in mind, given the layers A and B are "vertices", when you call:
B(A)
You're are creating an edge between them like: A ➡️ B
4/9🧵
B(A)
You're are creating an edge between them like: A ➡️ B
4/9🧵
Benefits of the Functional API:
• Plotting the model and model.summary work as expected to give a good visualization
• Debugging will happen during model definition since layers can be "type-checked"
5/9🧵
• Plotting the model and model.summary work as expected to give a good visualization
• Debugging will happen during model definition since layers can be "type-checked"
5/9🧵
The Functional API has the limitation of enable only directed acyclic graphs, if you need something like a dynamic network or recursive networks, than you won't be able to build with this API
6/9🧵
6/9🧵
This blog post by @random_forests has an even better explanation of the Functional API
blog.tensorflow.org/2019/01/what-a…
7/9🧵
blog.tensorflow.org/2019/01/what-a…
7/9🧵
This guide have more information and playing with it can give you more insights about the Functional API:
tensorflow.org/guide/keras/fu…
8/9🧵
tensorflow.org/guide/keras/fu…
8/9🧵
One good example of Functional API usage is on this tutorial: tensorflow.org/hub/tutorials/…
YAMNet has 3 outputs. To use it to extract audio embedding, the model has to be able to deal with multiple outputs! It's perfect for a Functional API.
9/9🧵
YAMNet has 3 outputs. To use it to extract audio embedding, the model has to be able to deal with multiple outputs! It's perfect for a Functional API.
9/9🧵
• • •
Missing some Tweet in this thread? You can try to
force a refresh