
Что стоит знать в фреймворке (для определенности pytorch):
- как строится вычислительный граф (у тензоров есть backward-функция, за которую можно дернуть для бекпропа)
- как представлять данные (условно складываем картинки в тензора [bs, channels, height, width])
- как строится вычислительный граф (у тензоров есть backward-функция, за которую можно дернуть для бекпропа)
- как представлять данные (условно складываем картинки в тензора [bs, channels, height, width])
- как вычисляется лосс (давайте опросом, что должно быть у сети для многоклассовой классификации в голове?)
Пояснения на всякий случай:
- в доку не подглядывать!
- FC=Linear (иначе не лезло)
- если не понимаете о чем речь => reply с вопросом
Пояснения на всякий случай:
- в доку не подглядывать!
- FC=Linear (иначе не лезло)
- если не понимаете о чем речь => reply с вопросом
- как управлять оптимизатором (обход весов, lr scheduling, grad_clip..)
- как мерить скорость и утилизацию железа (tqdm, watch nvidia-smi, profiler..)
- как дебажить наны (forward_hook, backward_hook)
- как сериализовать модель (torch.save, jit.trace, jit.script)
- как мерить скорость и утилизацию железа (tqdm, watch nvidia-smi, profiler..)
- как дебажить наны (forward_hook, backward_hook)
- как сериализовать модель (torch.save, jit.trace, jit.script)
+ вдогонку микровопрос про бекпроп.
У нас есть MLP (несколько Linear слоев с нелинейностями или без), можно ли инициализировать матрицу весов нулями?
У нас есть MLP (несколько Linear слоев с нелинейностями или без), можно ли инициализировать матрицу весов нулями?
+ второй микровопрос, можно ли инициализировать матрицу весов нулями в двух Linear слоях подряд?
Попробуем как в старые добрые на доске, но без доски.
Если x не нулевой и градиенты на выход придут ненулевые, то W изменится на первой итерации и дальше все будет хорошо.
Могут ли градиенты быть не нулевыми? Зависит от дальнейшего графа :) еще один сломанный FC не даст учиться
Если x не нулевой и градиенты на выход придут ненулевые, то W изменится на первой итерации и дальше все будет хорошо.
Могут ли градиенты быть не нулевыми? Зависит от дальнейшего графа :) еще один сломанный FC не даст учиться
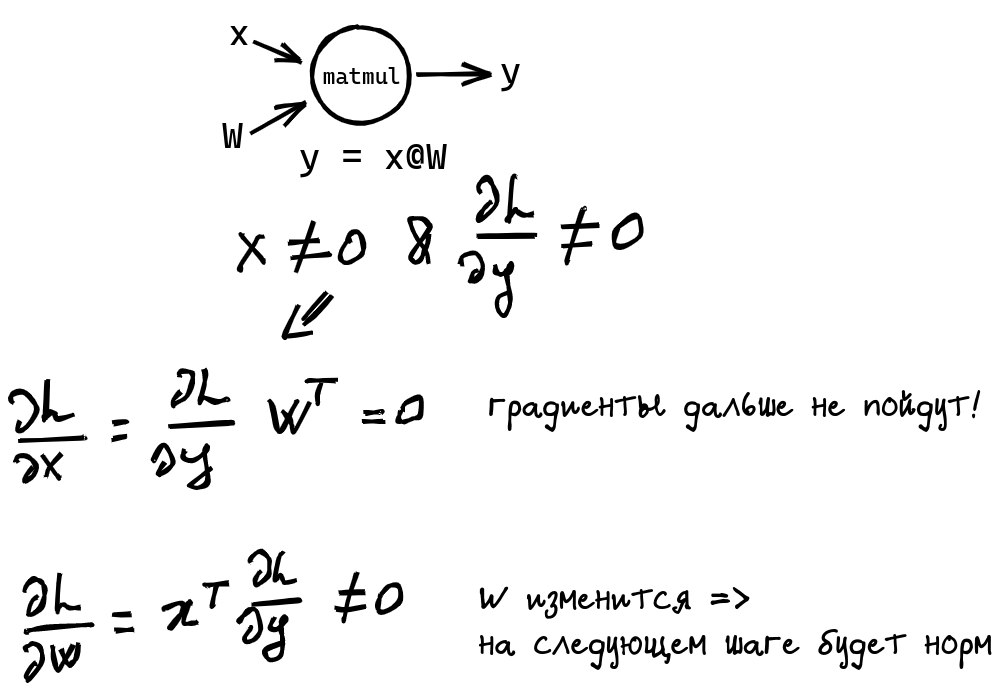
• • •
Missing some Tweet in this thread? You can try to
force a refresh


