
*MLP-Mixer: An all-MLP Architecture for Vision*
It's all over Twitter!
A new, cool architecture that mixes several ideas from MLPs, CNNs, ViTs, trying to keep it as simple as possible.
Small thread below. 👇 /n
It's all over Twitter!
A new, cool architecture that mixes several ideas from MLPs, CNNs, ViTs, trying to keep it as simple as possible.
Small thread below. 👇 /n
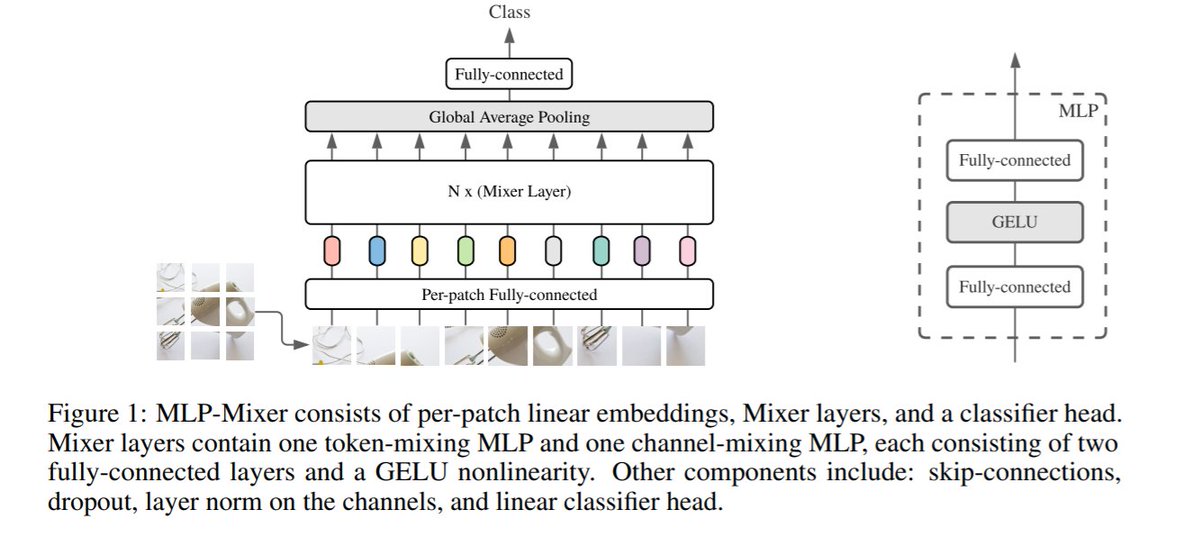
The idea is strikingly simple:
(i) transform an image into a sequence of patches;
(ii) apply in alternating fashion an MLP on each patch, and on each feature wrt all patches.
Mathematically, it is equivalent to applying an MLP on rows and columns of the matrix of patches. /n
(i) transform an image into a sequence of patches;
(ii) apply in alternating fashion an MLP on each patch, and on each feature wrt all patches.
Mathematically, it is equivalent to applying an MLP on rows and columns of the matrix of patches. /n

There has been some discussion (and memes!) sparked from this tweet by @ylecun, because several components can be interpreted (or implemented) using convolutive layers (eg, 1x1 convolutions).
So, not a CNN, but definitely not a "simple MLP" either. /n
So, not a CNN, but definitely not a "simple MLP" either. /n
https://twitter.com/ylecun/status/1390543133474234368
The results, as you would guess from the Twitter virality, are good, especially when you go to extremely large sizes.
In what appears to have become a standard, many results are from the internal JFT-300M dataset, which is definitely not good for reproducibility. /n
In what appears to have become a standard, many results are from the internal JFT-300M dataset, which is definitely not good for reproducibility. /n

I have seen many discussions about the "smaller inductive bias" of this architecture.
If we go by code and simplicity, this might be true, but I honestly find it extremely hard to understand "how much" architectural bias or properties we have here. /n
If we go by code and simplicity, this might be true, but I honestly find it extremely hard to understand "how much" architectural bias or properties we have here. /n

Anyway, paper is here: arxiv.org/pdf/2105.01601…
Already quite a lot of implementations: paperswithcode.com/paper/mlp-mixe…
Video by @ykilcher :
/n
Already quite a lot of implementations: paperswithcode.com/paper/mlp-mixe…
Video by @ykilcher :
/n
Kudos to all authors! Judging by the amount of interest and discussion, this is already set to become a strong baseline (or more?) along which to compare.
@neilhoulsby @tolstikhini @__kolesnikov__ @giffmana @XiaohuaZhai @TomUnterthiner @JessicaYung17 @keysers @kyosu @MarioLucic_
@neilhoulsby @tolstikhini @__kolesnikov__ @giffmana @XiaohuaZhai @TomUnterthiner @JessicaYung17 @keysers @kyosu @MarioLucic_
• • •
Missing some Tweet in this thread? You can try to
force a refresh


