
Last week, "Marina" - a piano teacher who publishes free lessons her Piano Keys Youtube channel - celebrated her fifth anniversary by announcing that she was quitting Youtube because her meager wages were being stolen by fraudsters.
1/
1/

(If you'd like an unrolled version of this thread to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:)
pluralistic.net/2021/05/08/cop…
pluralistic.net/2021/05/08/cop…
Marina posted a video with a snatch of her performance of Beethoven's "Moonlight Sonata," published in 1801. The composition is firmly in the public domain, and the copyright in the performance is firmly Marina's, but it still triggered Youtube's automated copyright filter.
2/
2/
A corporate entity - identified only by an alphabet soup of initialisms and cryptic LLC names - had claimed Ole Ludwig Van's masterpiece as their own, identifying it as "Wicca Moonlight."
3/
3/
Content ID, the automated Youtube filter, flagged Marina's track as an unauthorized performance of this "Wicca Moonlight" track. Marina appealed the automated judgement, which triggered a message to this shadowy LLC asking if they agreed that no infringement had taken place.
4/
4/
But the LLC renewed its claim of infringement. Marina now faces several unpleasant choices:
* She can allow the LLC to monetize her video, stealing the meager wages she receives from the ads that appear on it
* She can take down her video
5/
* She can allow the LLC to monetize her video, stealing the meager wages she receives from the ads that appear on it
* She can take down her video
5/
* She can provide her full name and address to Youtube in order to escalate the claim, with the possibility that her attackers will get her contact details, and with the risk that if she loses her claim, she can lose her Youtube channel
6/
6/
The incident was a wake-up call for Marina, who is quitting Youtube altogether, noting that it has become a place that favors grifters over creators. She's not wrong, and it's worth looking at how that happened.
7/
7/
Content ID was created to mollify the entertainment industry after Google acquired Youtube. Google would spend $100m on filtering tech that would allow rightsholders to go beyond the simple "takedown" permitted by law, and instead share in revenues from creative uses.
8/
8/
But it's easy to see how this system could be abused. What if people falsely asserted copyright over works to which they had no claim? What if rightsholders rejected fair uses, especially criticism?
9/
9/
In a world where the ownership of creative works can take years to untangle in the courts and where judges' fair use rulings are impossible to predict in advance, how could Google hope to get it right, especially at the vast scale of Youtube?
10/
10/
The impossibility of automating copyright judgments didn't stop Google from trying to perfect its filter, adding layers of complexity until Content ID's appeal process turned into a cod-legal system whose flowchart looks like a bowl of spaghetti.
pluralistic.net/2020/12/12/fai…
11/
pluralistic.net/2020/12/12/fai…
11/
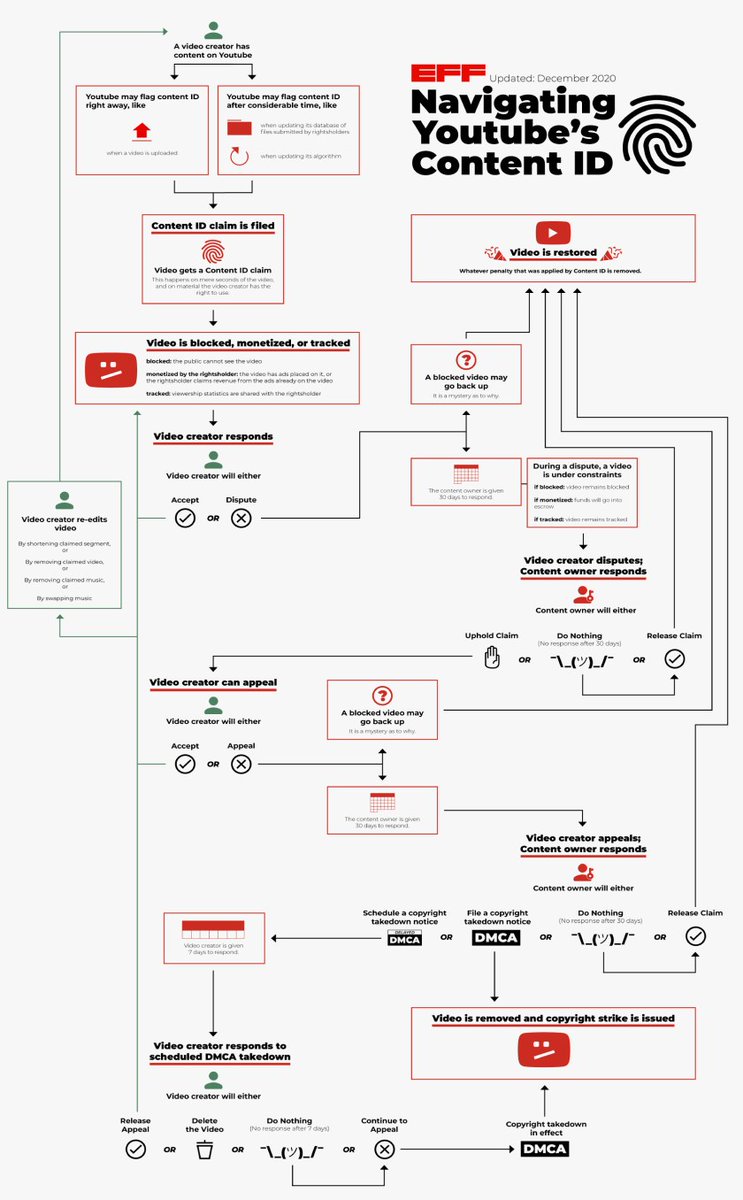
The resulting mess firmly favors attackers (wage stealers, fraudsters, censors, bullies) over defenders (creators, critics). Attackers don't need to waste their time making art, which leaves them with the surplus capacity to master the counterintuitive "legal" framework.
12/
12/
You can't fix a system broke by complexity by adding more complexity to it. Attempts to do so only makes the system more exploitable by bad actors, like blackmailers who use fake copyright claims to extract ransoms from working creators.
torrentfreak.com/youtube-strike…
13/
torrentfreak.com/youtube-strike…
13/
But it would be a mistake to think that filterfraud was primarily a problem of shadowy scammers. The most prolific filter scammers and wage-thieves are giant music companies, like Sony Music, who claim nearly ALL classical music:
pluralistic.net/2020/05/22/cri…
14/
pluralistic.net/2020/05/22/cri…
14/
The Big Tech companies argue that they have an appeals process that can reverse these overclaims, but that process is a joke. Instagram takedowns take a few seconds to file, but TWENTY-EIGHT MONTHS to appeal.
pluralistic.net/2020/05/17/che…
15/
pluralistic.net/2020/05/17/che…
15/
The entertainment industry are flagrant filternet abusers. Take Warner Chappell, whose subsidiary demonetizes videos that include the numbers "36" and "50":
dexerto.com/entertainment/…
16/
dexerto.com/entertainment/…
16/
Warner Chappell are prolific copyfraudsters. For decades, they fraudulently claimed ownership over "Happy Birthday" (!):
consumerist.com/2016/02/09/hap…
17/
consumerist.com/2016/02/09/hap…
17/
They're still at it - In 2020 they used a fraudulent claim to nuke a music theory video, and then a human being working on behalf of the company renewed the claim AFTER being informed that they were mistaken about which song was quoted in the video:
pluralistic.net/2020/03/05/war…
18/
pluralistic.net/2020/03/05/war…
18/
The fact that automated copyright claims can remove material from the internet leads to a lot of sheer fuckery. In 2019, anti-fascists toyed with blaring copyrighted music at far right rallies to prevent their enemies from posting them online.
memex.craphound.com/2019/07/23/cle…
19/
memex.craphound.com/2019/07/23/cle…
19/
At the time, I warned that this would end badly. Just a month before, there had been a huge scandal because critics of extremist violence found that automated filters killed their videos because they featured clips of that violence:
memex.craphound.com/2019/06/06/peo…
20/
memex.craphound.com/2019/06/06/peo…
20/
Since then, it's only gotten worse. The Chinese Communist Party uses copyfraud to remove critical videos from Youtube:
pluralistic.net/2020/05/27/lit…
and so does the Beverley Hills Police Department:
pluralistic.net/2021/02/10/duk…
21/
pluralistic.net/2020/05/27/lit…
and so does the Beverley Hills Police Department:
pluralistic.net/2021/02/10/duk…
21/
But despite all that, the momentum is for MORE filtering, to remove far fuzzier categories of content. The EU's #Terreg has just gone into effect, giving platforms just ONE HOUR to remove "terrorist" content:
eff.org/deeplinks/2021…
22/
eff.org/deeplinks/2021…
22/
The platforms have pivoted from opposing filter rules to endorsing them. Marc Zuckerberg says that he's fine with removing legal protections for online platforms unless they have hundreds of millions of dollars to install filters.
pluralistic.net/2021/03/25/fac…
23/
pluralistic.net/2021/03/25/fac…
23/
The advocates for a #filternet insist that all these problems can be solved if geeks just NERD HARDER to automate good judgment, fair appeals, and accurate attributions. This is pure wishful thinking. As is so often the case in tech policy, "wanting it badly is not enough."
24/
24/
In 2019, the EU passed the #CopyrightDirective, whose #Article17 is a "notice and staydown" rule requiring platforms to do instant takedowns on notice of infringement AND to prevent content from being re-posted.
25/
25/
There's no way to do this without filters, but there's no way to make filters without violating the GDPR. The EU trying to figure out how to make it work, and the people who said this wouldn't require filters are now claiming that filters are fine.
pluralistic.net/2020/09/11/pro…
26/
pluralistic.net/2020/09/11/pro…
26/
Automating subtle judgment calls is impossible, not just because copyright's limitations - fair use and others - are grounded in subjective factors like "artistic intent," but because automating a flawed process creates flaws at scale.
27/
27/
Remember when @jimmyfallon broadcasted himself playing a video game? NBC automatically claimed the whole program as its copyrighted work, and thereafter, gamers who streamed themselves playing that game got automated takedowns from NBC.
old.reddit.com/r/beatsaber/co…
28/
old.reddit.com/r/beatsaber/co…
28/
The relentless expansion of proprietary rights over our virtual and physical world raises the stakes for filter errors. The new Notre Dame spire will be a copyrighted work - will filters block videos of protests in front of the cathedral?
techdirt.com/articles/20190…
29/
techdirt.com/articles/20190…
29/
And ever since the US's 1976 Copyright Act abolished a registration requirement, it's gotten harder to figure out who controls the rights to any work, so that even the "royalty free" music for Youtubers to safely use turned out to be copyrighted:
torrentfreak.com/royalty-free-m…
30/
torrentfreak.com/royalty-free-m…
30/
We need a new deal for content removal, one that favors working creators over wage-thieves who have the time and energy to master the crufty, complex private legal systems each platform grows for itself.
eff.org/deeplinks/2019…
31/
eff.org/deeplinks/2019…
31/
Back in 2019, @FutureTenseNow commissioned me to write an sf story about how this stuff might work out in the coming years. The result, "Affordances," is sadly still relevant today:
slate.com/technology/201…
Here's a podcast of the story as well:
ia803108.us.archive.org/3/items/Cory_D…
32/
slate.com/technology/201…
Here's a podcast of the story as well:
ia803108.us.archive.org/3/items/Cory_D…
32/
Meanwhile, governments from Australia to the UK to Canada are adopting #HarmfulContent rules that are poised to vastly expand the filternet, insisting that it's better than the alternative.
cbc.ca/news/politics/…
eof/
cbc.ca/news/politics/…
eof/
• • •
Missing some Tweet in this thread? You can try to
force a refresh









