
Where to get data for your next machine learning project?
An overview of 8 amazing resources to accelerate your next project with data!
- Google Datasets
- Big Bad NLP Datasets
- Hugging Face Datasets
- Papers with Code Datasets
- Open Data on AWS
- Awesome Public Datasets
An overview of 8 amazing resources to accelerate your next project with data!
- Google Datasets
- Big Bad NLP Datasets
- Hugging Face Datasets
- Papers with Code Datasets
- Open Data on AWS
- Awesome Public Datasets
Hugging Face Datasets
Mainly for NLP but the good news Hugging Face is expanding and we can be sure that they will add datasets for visual machine learning soon!
@huggingface
huggingface.co/datasets
Mainly for NLP but the good news Hugging Face is expanding and we can be sure that they will add datasets for visual machine learning soon!
@huggingface
huggingface.co/datasets

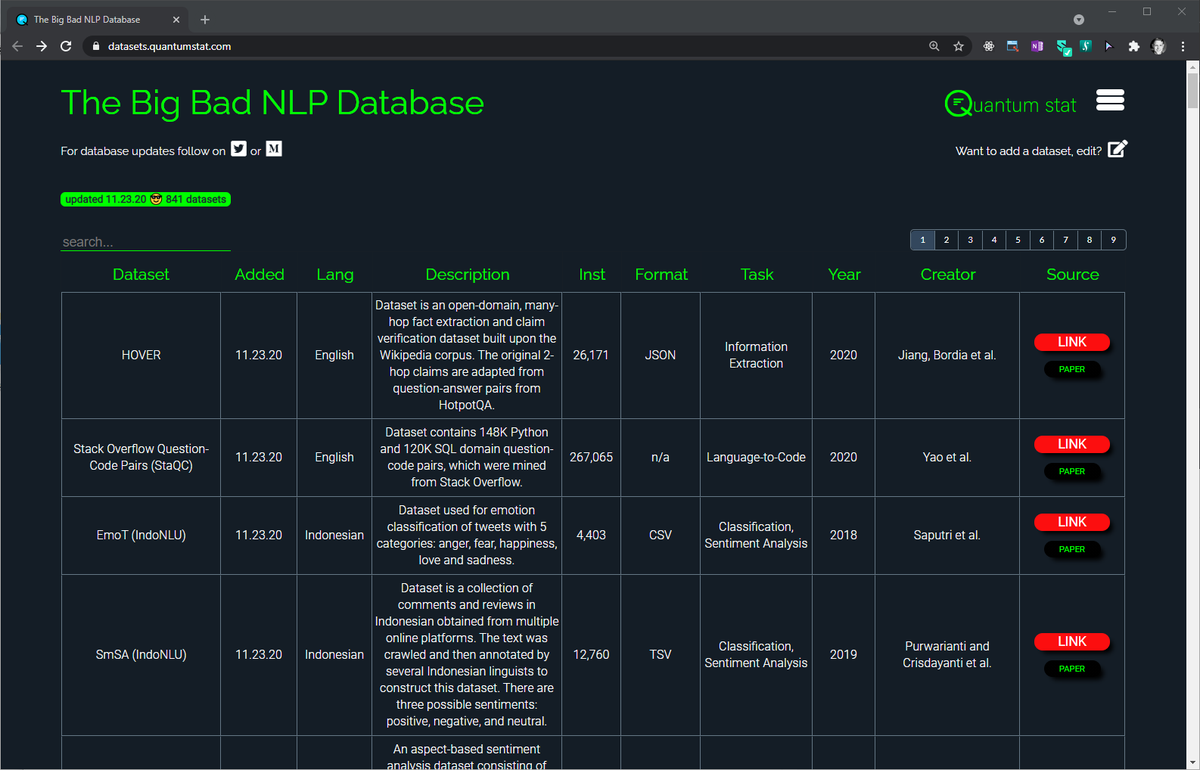
Big Bad NLP Datasets
One of the best sources for sophisticated Natural Language Processing datasets
@Quantum_Stat
datasets.quantumstat.com
One of the best sources for sophisticated Natural Language Processing datasets
@Quantum_Stat
datasets.quantumstat.com
Papers with Code Datasets
3,830 machine learning datasets with a supreme search and a good composition of datasets
@paperswithdata
paperswithcode.com/datasets
3,830 machine learning datasets with a supreme search and a good composition of datasets
@paperswithdata
paperswithcode.com/datasets

Registry of Open Data on AWS
This registry exists to help people discover and share datasets that are available via AWS resources
registry.opendata.aws
This registry exists to help people discover and share datasets that are available via AWS resources
registry.opendata.aws

Azure public data sets
Public data sets for testing and prototyping
A bit outdated but a credible source
docs.microsoft.com/en-us/azure/az…
Public data sets for testing and prototyping
A bit outdated but a credible source
docs.microsoft.com/en-us/azure/az…

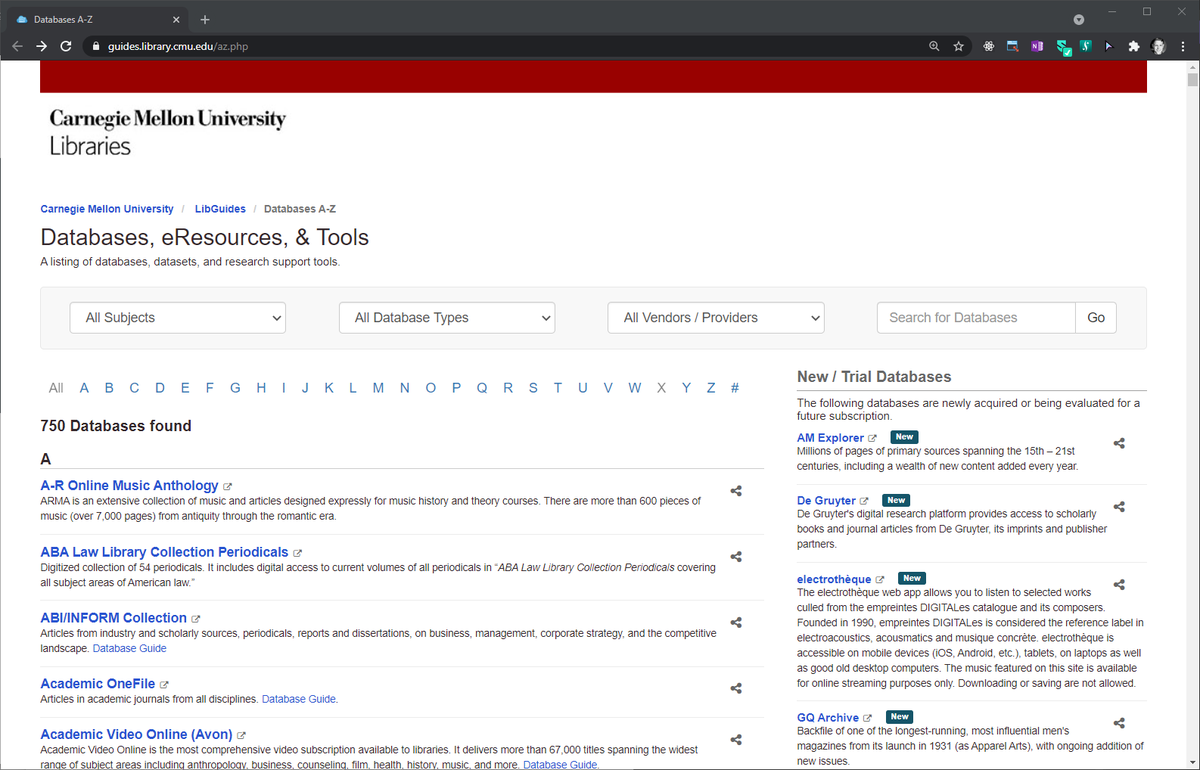
Carnegie Mellon University
A listing of 750 databases, datasets, and research support tools.
guides.library.cmu.edu/az.php
A listing of 750 databases, datasets, and research support tools.
guides.library.cmu.edu/az.php
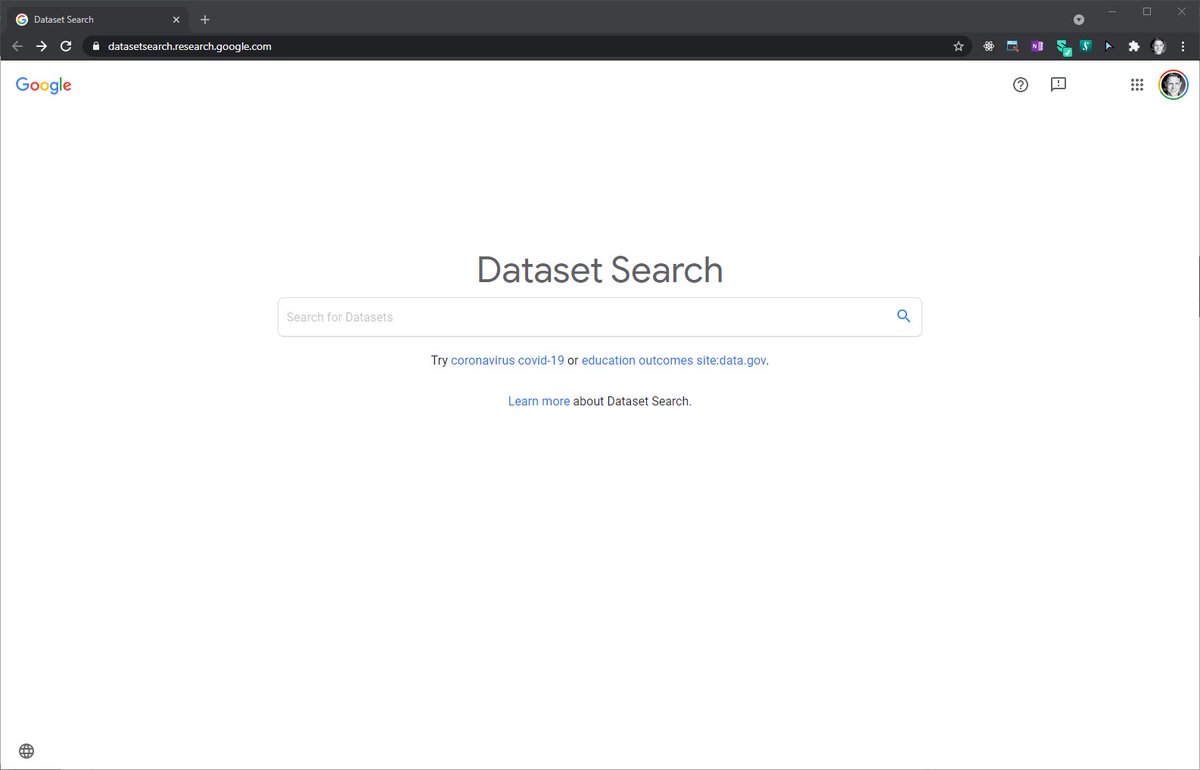
Google Datasets
It is as simple to search Datasets on Google Dataset Search as it is to search for anything on Google Search! You just enter the topic on which you need to find a Dataset
datasetsearch.research.google.com
It is as simple to search Datasets on Google Dataset Search as it is to search for anything on Google Search! You just enter the topic on which you need to find a Dataset
datasetsearch.research.google.com


The home of the U.S. Government’s open data
Here you will find data, tools, and resources to conduct research, develop web and mobile applications, design data visualizations
data.gov
Here you will find data, tools, and resources to conduct research, develop web and mobile applications, design data visualizations
data.gov

• • •
Missing some Tweet in this thread? You can try to
force a refresh




