
Do you need social media data for your machine learning project?
- Twitter data?
- Reddit data?
- Facebook data?
Where to get it?
- Twitter data?
- Reddit data?
- Facebook data?
Where to get it?
Reddit: Pushshift
Pushshift is a big-data storage and analytics project.
Most people know it for its copy of reddit comments and submissions.
reddit.com/r/pushshift/co…
Pushshift is a big-data storage and analytics project.
Most people know it for its copy of reddit comments and submissions.
reddit.com/r/pushshift/co…
Reddit: Pushshift API
The pushshift.io Reddit API was designed and created by the /r/datasets mod team to help provide enhanced functionality and search capabilities for searching Reddit comments and submissions.
github.com/pushshift/api
The pushshift.io Reddit API was designed and created by the /r/datasets mod team to help provide enhanced functionality and search capabilities for searching Reddit comments and submissions.
github.com/pushshift/api
Reddit: Pushshift file download
Note: The latest data for manual download is from April 2020
files.pushshift.io/reddit/comment…
Note: The latest data for manual download is from April 2020
files.pushshift.io/reddit/comment…
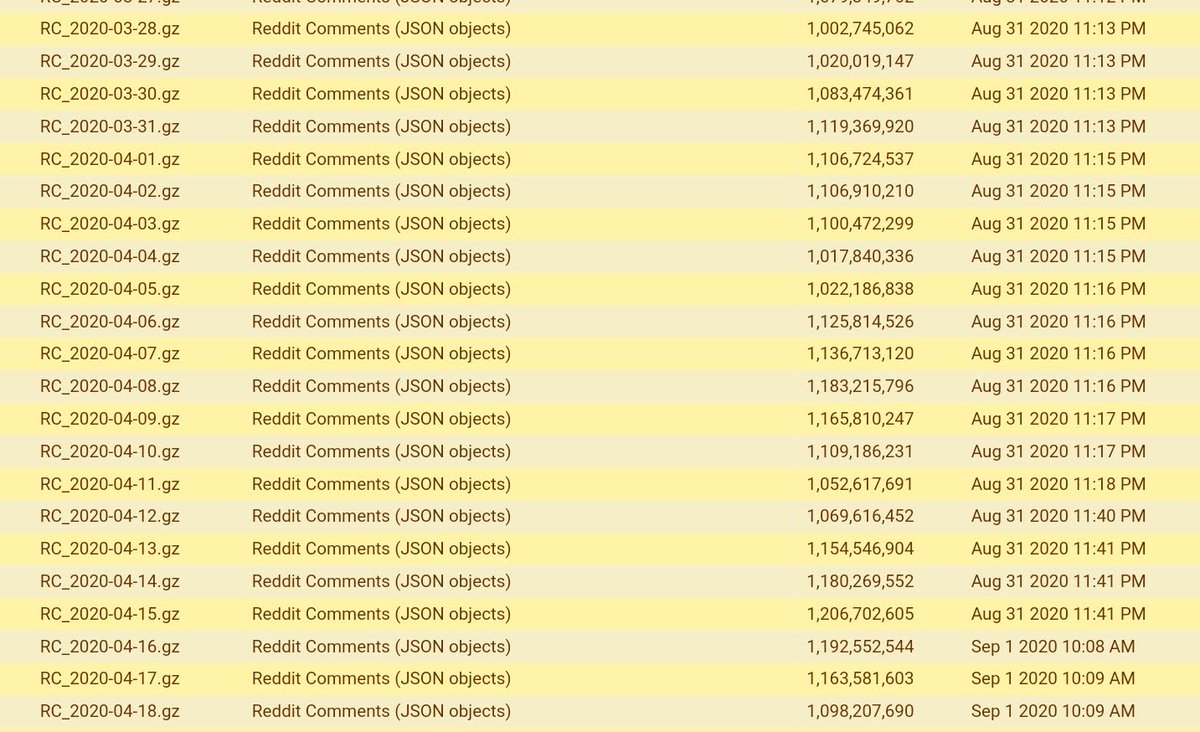
Reddit: PMAW: Pushshift Multithread API Wrapper
PMAW is an ultra minimalist wrapper for the Pushshift API which uses multithreading to retrieve Reddit comments and submissions.
If you pull data via Pushshift use PMAW, highly recommended!
github.com/mattpodolak/pm…
PMAW is an ultra minimalist wrapper for the Pushshift API which uses multithreading to retrieve Reddit comments and submissions.
If you pull data via Pushshift use PMAW, highly recommended!
github.com/mattpodolak/pm…
Reddit: Redditsearch
Frontend which uses Pushshift for detail searches on subreddits or domain
redditsearch.io
Frontend which uses Pushshift for detail searches on subreddits or domain
redditsearch.io
Twitter: Stream as download
The Internet Archive is a digital library of Internet sites and other cultural artifacts in digital form.
Note: The last archived data is from January 2021
archive.org/search.php?que…
The Internet Archive is a digital library of Internet sites and other cultural artifacts in digital form.
Note: The last archived data is from January 2021
archive.org/search.php?que…

Twitter: Tweepy Twitter for Python!
An easy-to-use Python library for accessing the Twitter API.
Note: The downside is the API limitations of Twitter, so you need a lot of time.
github.com/tweepy/tweepy
An easy-to-use Python library for accessing the Twitter API.
Note: The downside is the API limitations of Twitter, so you need a lot of time.
github.com/tweepy/tweepy

Twitter: Script
Most twitter scraper are banned by Twitter or no longer work so here is a simple and unlimited twitter scraper with python and without authentication
Note: Headless mode no longer work and it uses Selenium to access Twitter
github.com/Altimis/Scweet
Most twitter scraper are banned by Twitter or no longer work so here is a simple and unlimited twitter scraper with python and without authentication
Note: Headless mode no longer work and it uses Selenium to access Twitter
github.com/Altimis/Scweet
Facebook: Scrape Facebook public pages without an API key.
$ pip install facebook-scraper
github.com/kevinzg/facebo…
$ pip install facebook-scraper
github.com/kevinzg/facebo…
Facebook: Large Page-Page Network data
Nodes represent official Facebook pages while the links are mutual likes between sites.
Node features are extracted from the site descriptions that the page owners created to summarize the purpose of the site.
snap.stanford.edu/data/facebook-…
Nodes represent official Facebook pages while the links are mutual likes between sites.
Node features are extracted from the site descriptions that the page owners created to summarize the purpose of the site.
snap.stanford.edu/data/facebook-…

Octoparse: Easy Web Scraping for Anyone
Everything you need to automate your web scraping.
Note: It's a paid service.
octoparse.com
Everything you need to automate your web scraping.
Note: It's a paid service.
octoparse.com
we need this edit function. my inner zen isn't balanced every time i spot a typo
• • •
Missing some Tweet in this thread? You can try to
force a refresh








