
Presenting "QVHighlights": 10K YouTube videos dataset annotated w. human written queries, clip-wise relevance, highlightness/saliency scores & Moment-DETR model for joint moment localization + highlight/saliency prediction
arxiv.org/abs/2107.09609
tlberg @mohitban47 @uncnlp
1/n
arxiv.org/abs/2107.09609
tlberg @mohitban47 @uncnlp
1/n

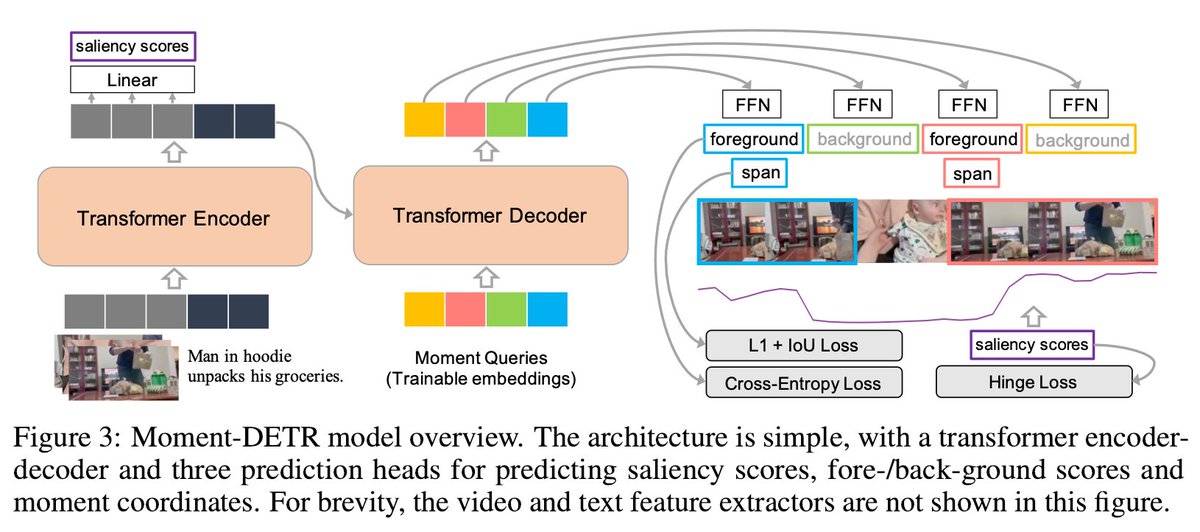


Detecting customized moments & highlight saliencies from videos given NL user queries is an important but under-studied topic. One of the challenges in pursuing this direction is lack of annotated data. Thus, we present Query-based Video Highlights (QVHighlights) dataset!
2/n
2/n

10K YouTube videos, covering everyday activities+travel in lifestyle vlog videos to social+political activities in news. Each video is annotated w. (1) human free-form NL query (2) relevant moments in video wrt query (3) 5-point scale saliency scores for all query-relevant clips

We also present a strong baseline Moment-DETR: transformer enc-dec model that views moment retrieval as a direct set prediction problem, taking extracted video &query representations (SlowFast, CLIP) as inputs and predicting moment coordinates and saliency scores end-to-end
4/n
4/n
While our model does not utilize any human prior, we show that it performs competitively wrt well-engineered architectures. With weakly supervised pretraining using ASR captions, Moment-DETR strongly outperforms previous methods. We also present several ablations+visualizations.

Data and code is publicly available at: github.com/jayleicn/momen…
Our evaluation is hosted on CodaLab, come try your latest video+language models on this new important+challenging task!
Our evaluation is hosted on CodaLab, come try your latest video+language models on this new important+challenging task!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


