
Humans reuse skills effortlessly to learn new tasks - can robots do the same? In our new paper, we show how to pre-train robotic skills and adapt them to new tasks in a kitchen.
tl;dr you’ll have a robot chef soon. 🧑🍳🤖
links / details below
thread 🧵 1/10
tl;dr you’ll have a robot chef soon. 🧑🍳🤖
links / details below
thread 🧵 1/10
Title: Hierarchical Few-Shot Imitation with Skill Transition Models
Paper: arxiv.org/abs/2107.08981
Site: sites.google.com/view/few-shot-…
Main idea: fit generative “skill” model on large offline dataset, adapt it to new tasks
Result: show robot a new task, it will imitate it
2/10
Paper: arxiv.org/abs/2107.08981
Site: sites.google.com/view/few-shot-…
Main idea: fit generative “skill” model on large offline dataset, adapt it to new tasks
Result: show robot a new task, it will imitate it
2/10
We introduce Few-shot Imitation with Skill Transition Models (FIST). FIST first extracts skills from a diverse offline dataset of demonstrations, and then adapts them to the new downstream task. FIST has 3 steps (1) Extraction (2) Adaptation (3) Evaluation.
3/10
3/10
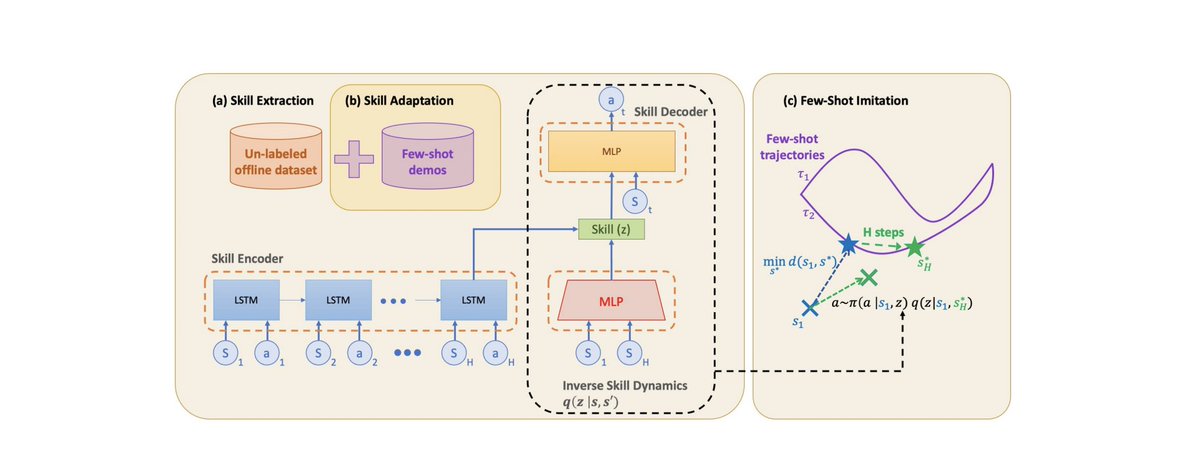
Step 1: Skill Extraction
Here we fit a generative model to encode-decode action sequences into skills "z". We also learn an inverse skill dynamics model p(z|s,s’) and a contrastive distance function d(s,s’) to be used later for imitation.
4/10
Here we fit a generative model to encode-decode action sequences into skills "z". We also learn an inverse skill dynamics model p(z|s,s’) and a contrastive distance function d(s,s’) to be used later for imitation.
4/10
Step 2: Skill Adaptation
Next for new downstream tasks, we quickly finetune the skill network and the inverse model to internalize the task. This part is very data-efficient. We require 1-10 demonstrations.
5/10
Next for new downstream tasks, we quickly finetune the skill network and the inverse model to internalize the task. This part is very data-efficient. We require 1-10 demonstrations.
5/10

Step 3: Semi-Parametric Evaluation
Finally, we use the inverse model p(z|s,s’) to select skills to best imitate the downstream demonstration. Since we don’t know s’ in advance, we use a contrastive distance function d(s,s’) to select the closest s’ from the few-shot demos.
6/10
Finally, we use the inverse model p(z|s,s’) to select skills to best imitate the downstream demonstration. Since we don’t know s’ in advance, we use a contrastive distance function d(s,s’) to select the closest s’ from the few-shot demos.
6/10
With these three steps the FIST agent can generalize to new downstream tasks parts of which have never been seen before. We show results on three long-horizon tasks (including a kitchen robot) that FIST can solve from just 10 demonstrations.
7/10
7/10

We also find that FIST is a strong one-shot learner for in-distribution downstream tasks. 4 pts is the max possible score in the table below. With 1 demo, FIST is able to chain several subtasks together to imitate the long-horizon demo without drifting off-distribution.
8/10
8/10

Along with other recent work, this is an exciting step into pre-training for robotics. Hopefully, we can bring GPT-like capabilities to embodied agents in the future. Was a fun collaboration with @CyrusHakha @RuihanZhao & Albert Zhan who co-led this work and @pabbeel!
9/10
9/10
Also thanks to @KarlPertsch for amazing work on the SPiRL architecture which was used as the backbone to our algorithm.
10/10
10/10
• • •
Missing some Tweet in this thread? You can try to
force a refresh


