
12 years using @screamingfrog for #SEO audits.
Here's what I believe are the best settings for most site audits.
A thread
Here's what I believe are the best settings for most site audits.
A thread
Firstly, why this thread?
Training people on #ScreamingFrog since 2010, I know:
- The default settings aren’t ideal for full audits.
- Issues may be missed
- New users struggle to understand the best settings
Full guide here: technicalseo.consulting/the-best-screa…
Here's the best bits:
Training people on #ScreamingFrog since 2010, I know:
- The default settings aren’t ideal for full audits.
- Issues may be missed
- New users struggle to understand the best settings
Full guide here: technicalseo.consulting/the-best-screa…
Here's the best bits:
Storage Mode.
If you have an SSD, use Database mode because:
a. It's continually saving to the database. If the Frog or your machine crashes the crawl is autosaved.
b. You can crawl much bigger sites than in RAM mode.
If you have an SSD, use Database mode because:
a. It's continually saving to the database. If the Frog or your machine crashes the crawl is autosaved.
b. You can crawl much bigger sites than in RAM mode.
Memory Allocation.
Allocate as much RAM as you can, but always leave 2GB from your total RAM.
I have 8GB RAM, I’ll allocate 6GB.
Allocate as much RAM as you can, but always leave 2GB from your total RAM.
I have 8GB RAM, I’ll allocate 6GB.
Spider Settings Tabs - Crawl.
By default, there are 4 boxes unticked here that I tick (Green ticks):
By default, there are 4 boxes unticked here that I tick (Green ticks):
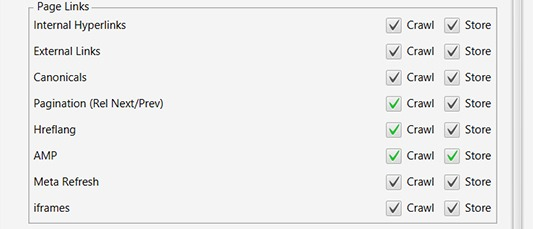
Tick "Pagination(Rel/Prev)"
There could be URLs only linked from deep paginated pages.
Such as PDPs on ecommerce categories, or articles on a publishers site.
We don't want to miss any pages, so tick this.
There could be URLs only linked from deep paginated pages.
Such as PDPs on ecommerce categories, or articles on a publishers site.
We don't want to miss any pages, so tick this.
Tick "Href lang".
The alternate version of URLs may not be linked in the HTML body of the page, only in the href lang tags.
We want to discover all URLs and be able to audit multilingual/local setups, so tick this.
The alternate version of URLs may not be linked in the HTML body of the page, only in the href lang tags.
We want to discover all URLs and be able to audit multilingual/local setups, so tick this.
Tick "AMP."
a. A site could also be using AMP, but you might not realise it.
b. The Frog checks for lots of AMP issues!: screamingfrog.co.uk/how-to-audit-v…
a. A site could also be using AMP, but you might not realise it.
b. The Frog checks for lots of AMP issues!: screamingfrog.co.uk/how-to-audit-v…
Spider Settings Tabs - Crawl Behaviour:
By default, there are 4 boxes unticked here that I tick (Green ticks):
By default, there are 4 boxes unticked here that I tick (Green ticks):
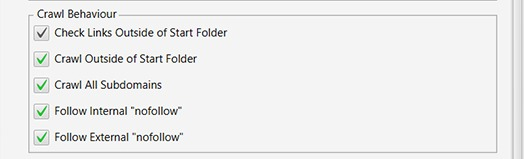
Tick "Crawl All Subdomains"
Leaving this unticked won’t crawl any subdomains the Frog my encounter linked.
I always have this ticked, because if I’m doing a complete audit of a site, I also want to know about any subdomains there are.
Leaving this unticked won’t crawl any subdomains the Frog my encounter linked.
I always have this ticked, because if I’m doing a complete audit of a site, I also want to know about any subdomains there are.
Tick Follow Internal “nofollow”.
a. I want to discover as many URLs as possible
b. I want to know if a site is using ”nofollow” so I can investigate & understand why they are using it on internal links.
a. I want to discover as many URLs as possible
b. I want to know if a site is using ”nofollow” so I can investigate & understand why they are using it on internal links.
Tick "Follow External “nofollow”.
a. I want the Frog to crawl all possible URLs.
b. Otherwise I might miss external URLs which are 404s, miss discovering pages that are participating in link spam or have been hacked.
a. I want the Frog to crawl all possible URLs.
b. Otherwise I might miss external URLs which are 404s, miss discovering pages that are participating in link spam or have been hacked.
Spider Settings Tabs - XML Sitemaps.
By default all 3 options in this section are unticked, I tick them all:
By default all 3 options in this section are unticked, I tick them all:
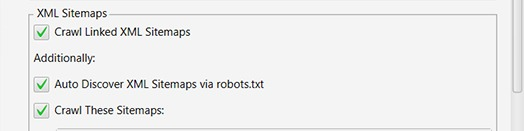
Tick "Crawl Linked XML Sitemaps."
a. Check if all important pages are included in sitemaps
b. Check only valid pages are included. No 404s, redirects, noindexed, canonicalised URLs.
b. Discover any URLs that are linked in XML Sitemaps but aren't linked on the site (orphan pages)
a. Check if all important pages are included in sitemaps
b. Check only valid pages are included. No 404s, redirects, noindexed, canonicalised URLs.
b. Discover any URLs that are linked in XML Sitemaps but aren't linked on the site (orphan pages)
Tick "Auto Discover XML Sitemaps via robots.txt"
As many sites include a link to their XML sitemaps in robots, it’s a no brainer to click this, so you don’t have to manually add the Sitemap URL.
As many sites include a link to their XML sitemaps in robots, it’s a no brainer to click this, so you don’t have to manually add the Sitemap URL.
Tick "Crawl These Sitemaps."
Submit any you know about that aren't listed in the robots.txt
Submit any you know about that aren't listed in the robots.txt
Extraction Tab Settings Tab - Page Details
By default, all these elements are ticked and that’s how I recommend you keep them for most audits.
By default, all these elements are ticked and that’s how I recommend you keep them for most audits.
Extraction Tab Settings Tab - URL Details
I tick one option here over the default settings:
I tick one option here over the default settings:

Tick "HTTP Headers."
Lots of interesting things can be in the headers.
e.g
If a site uses dynamic content serving for desktop vs mobile, it should use the Vary HTTP Header.
Lots of interesting things can be in the headers.
e.g
If a site uses dynamic content serving for desktop vs mobile, it should use the Vary HTTP Header.
Extraction Tab Settings Tab - Structured Data
All the elements in this section are unticked by default, I tick them all:
All the elements in this section are unticked by default, I tick them all:
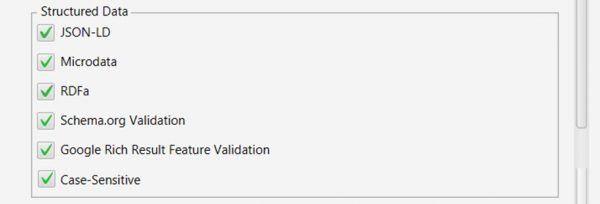
JSON-LD
Microdata
RDFa
I tick all of the above options, so I can fully audit the schema of the site, no matter how it’s implemented.
Microdata
RDFa
I tick all of the above options, so I can fully audit the schema of the site, no matter how it’s implemented.
Tick "Schema org Validation".
A great feature to check all schema validates against the official suggested implementation.
A great feature to check all schema validates against the official suggested implementation.
Tick "Google Rich Results Feature Validation."
Validates the mark-up against Google’s own documentation.
Select both options here, as Google has some specific requirements that aren’t included in the schema org guidelines.
Validates the mark-up against Google’s own documentation.
Select both options here, as Google has some specific requirements that aren’t included in the schema org guidelines.
Extraction Tab Settings Tab - Structured Data
Both the options in this section are unticked by default, I always tick them:
Both the options in this section are unticked by default, I always tick them:

Tick "Store HTML.
The Frog will save the HTML for every page.
This is extremely useful for double-checking any elements Frog reports on.
The Frog will save the HTML for every page.
This is extremely useful for double-checking any elements Frog reports on.
Tick "Store Rendered HTML."
This is useful when auditing JavaScript sites to see the difference between the HTML code sent from the server and what is actually rendered client-side in the browser.
This is useful when auditing JavaScript sites to see the difference between the HTML code sent from the server and what is actually rendered client-side in the browser.
Limits Settings Tab.
Change "Max Redirects to Follow".
This is the only option I change for most crawls in this tab. It’s set to 5 by default, I set it to the max, 20.
Setting the maximum helps me find the final destination in most redirect chains
Change "Max Redirects to Follow".
This is the only option I change for most crawls in this tab. It’s set to 5 by default, I set it to the max, 20.
Setting the maximum helps me find the final destination in most redirect chains
Advanced Settings Tab.
In this settings tab, I tick and untick a few boxes from the default settings:
In this settings tab, I tick and untick a few boxes from the default settings:
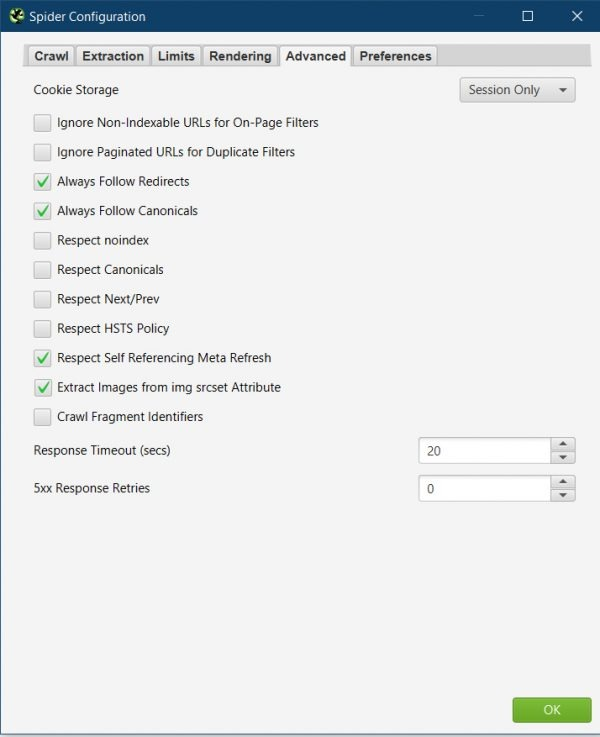
Untick "Ignore Non-indexable URLs for On-Page Filters".
Even if a URL is already non-indexable, I still want to see if there are issues with the page.
There are often times where pages have been set to noindex or canonicalised, but this has been done in error.
Even if a URL is already non-indexable, I still want to see if there are issues with the page.
There are often times where pages have been set to noindex or canonicalised, but this has been done in error.
Tick "Always Follow Redirects" & "Always Follow Canonicals"
I tick both of these, as I want to ensure the Frog discovers all URLs on the site.
There could be URLs that aren’t linked in the HTML of the code but are only linked via a redirect, or a canonical tag.
I tick both of these, as I want to ensure the Frog discovers all URLs on the site.
There could be URLs that aren’t linked in the HTML of the code but are only linked via a redirect, or a canonical tag.
Tick "Extract images from img srcset Attribute."
Google can crawl images implemented in the srcset attribute, so I tick this to ensure the Frog is extracting the same images Google would be.
I can then check how they are optimised. (image file names, alt tags, size)
Google can crawl images implemented in the srcset attribute, so I tick this to ensure the Frog is extracting the same images Google would be.
I can then check how they are optimised. (image file names, alt tags, size)
The following options are unticked by default and I also keep them that way.
These settings are quite important, so I’ll explain the reasoning behind keeping them unticked:
Respect Noindex
Respect Canonicals
Respect next/prev
These settings are quite important, so I’ll explain the reasoning behind keeping them unticked:
Respect Noindex
Respect Canonicals
Respect next/prev

As I want to get a full picture of all the URLs on the site, whether they are indexable or not, I don’t want to tick the options above.
If I did tick them, it means any URLs set to noindex, or canonicalised to a different URL, would not be reported in the Frog.
If I did tick them, it means any URLs set to noindex, or canonicalised to a different URL, would not be reported in the Frog.
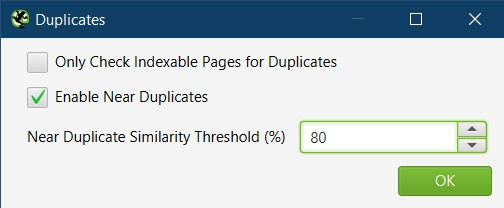
Content > Duplicates Settings:
Untick "Only Check Indexable Pages for Duplicates."
Even if pages are currently set to noindex, I still want to know if they are duplicating content, in case they should be set to index.
Untick "Only Check Indexable Pages for Duplicates."
Even if pages are currently set to noindex, I still want to know if they are duplicating content, in case they should be set to index.
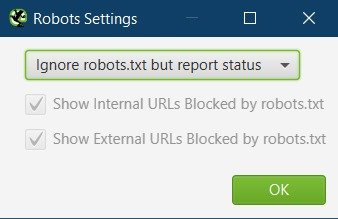
Robots.txt Settings:
Default setting here is:
"Respect robots.txt"
I have this set to:
"Ignore robots.txt but report status."
I can then audit the pages which are blocked, make sure they aren’t blocked in error & report if the URLs need to be removed from robots.txt
Default setting here is:
"Respect robots.txt"
I have this set to:
"Ignore robots.txt but report status."
I can then audit the pages which are blocked, make sure they aren’t blocked in error & report if the URLs need to be removed from robots.txt
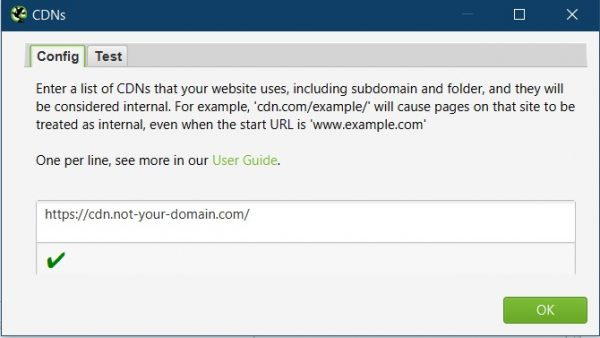
CDNs Settings:
This is very useful if a site uses a CDN for hosting images that is not part of the domain you are crawling.
e.g. cdn.not-your-domain.com/photos-of-cats…
You can add the domain above so Frog counts images on the other CDN domain as internal, then you can audit them.
This is very useful if a site uses a CDN for hosting images that is not part of the domain you are crawling.
e.g. cdn.not-your-domain.com/photos-of-cats…
You can add the domain above so Frog counts images on the other CDN domain as internal, then you can audit them.
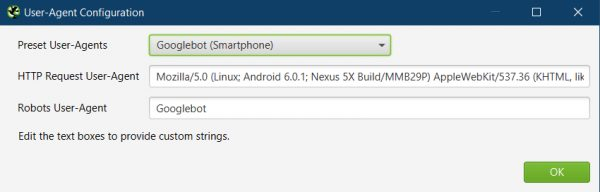
User-Agent Settings:
Set this to Googlebot (Smart Phone) so we see the same code Googles does.
Sites may change things depending on the user agent.
It could be done for valid reasons, it could be done for black hat reasons, or because the site has been hacked.
Set this to Googlebot (Smart Phone) so we see the same code Googles does.
Sites may change things depending on the user agent.
It could be done for valid reasons, it could be done for black hat reasons, or because the site has been hacked.
API Access Settings:
Using API access, we can enrich the crawl data with traffic or backlink data.
For two main reasons:
a. using GSC/GA data is another way to find orphan URLs.
b. Traffic data can help you prioritise the issues in your report
Using API access, we can enrich the crawl data with traffic or backlink data.
For two main reasons:
a. using GSC/GA data is another way to find orphan URLs.
b. Traffic data can help you prioritise the issues in your report
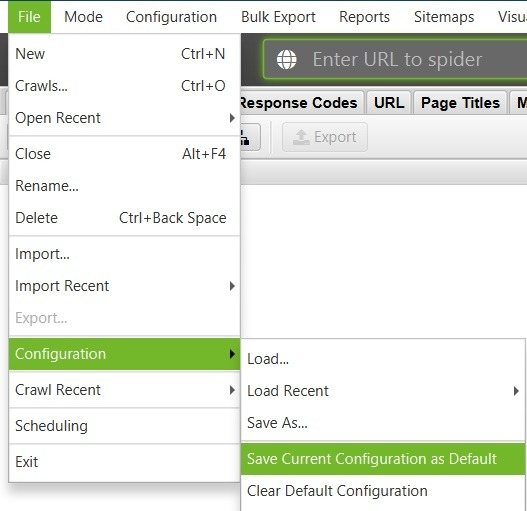
Saving Your Configuration!
Once you have everything set it up, it's time to save it. Otherwise, you will lose them on restart!
Go to file > Configuration > Save current configuration as default.
Once you have everything set it up, it's time to save it. Otherwise, you will lose them on restart!
Go to file > Configuration > Save current configuration as default.
That's the thread!
Hope you found it useful.
For even more settings and insights on the best settings for #screamingfrog check out my full guide here:
technicalseo.consulting/the-best-screa…
Hope you found it useful.
For even more settings and insights on the best settings for #screamingfrog check out my full guide here:
technicalseo.consulting/the-best-screa…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



{kind=link}