
#DataScience Project 4
Customer Segmentation
- Use Machine Learning to create a model that performs Customer Segmentation
Libraries Used
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Scikit learn
Models Trained
- KMeans Clustering
- Hierarchical Clustering
Customer Segmentation
- Use Machine Learning to create a model that performs Customer Segmentation
Libraries Used
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Scikit learn
Models Trained
- KMeans Clustering
- Hierarchical Clustering

Code for this project can be found here 👇
[Please do consider giving an upvote if you find this notebook to be useful 😀]
kaggle.com/piyalbanik/seg…
[Please do consider giving an upvote if you find this notebook to be useful 😀]
kaggle.com/piyalbanik/seg…
1. Business Understanding
The goal of this project is to divide customers into groups based on common characteristics in order to maximize the value of each customer to the business.
The goal of this project is to divide customers into groups based on common characteristics in order to maximize the value of each customer to the business.
2. Analytical Approach
Clustering of Customers based on similar characteristics is an Unsupervised Learning as for each observation we do not have any target variable.
For this project, I will use two Machine Learning models
- KMeans Clustering
- Hierarchical clustering
Clustering of Customers based on similar characteristics is an Unsupervised Learning as for each observation we do not have any target variable.
For this project, I will use two Machine Learning models
- KMeans Clustering
- Hierarchical clustering
3,4. Data Requirements and Data Collection
We would require a dataset that gives us information regarding customers from a market.
For this project, the dataset has been provided to us on Kaggle.
kaggle.com/vjchoudhary7/c…
We would require a dataset that gives us information regarding customers from a market.
For this project, the dataset has been provided to us on Kaggle.
kaggle.com/vjchoudhary7/c…
5. Data Understanding
- There is a total of 200 observations with each having 5 variables.
- The column of the dataset includes CustomerID, Gender, Age, Annual Income, Spending Score.
- There are no missing values 😀
- There is one categorical variable - Gender
- There is a total of 200 observations with each having 5 variables.
- The column of the dataset includes CustomerID, Gender, Age, Annual Income, Spending Score.
- There are no missing values 😀
- There is one categorical variable - Gender

Distribution plots of
- Age
- Annual Income(k$)
- Spending Score (1-100)
- Gender
- Age
- Annual Income(k$)
- Spending Score (1-100)
- Gender




The heatmap shows that there is no strong correlation among variables
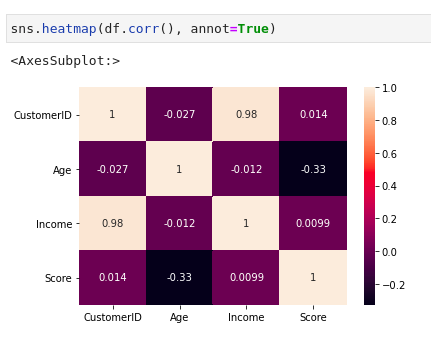
6. Feature Engineering
- Dropped CustomerID (not useful as it is unique for each customer)
- Created Dummy Variable for Gender
- Dropped CustomerID (not useful as it is unique for each customer)
- Created Dummy Variable for Gender

7. Modelling
K Means Clustering
- First, we determine the optimal number of clusters
- Then we determine starting values for each cluster
K Means Clustering
- First, we determine the optimal number of clusters
- Then we determine starting values for each cluster

K Means Clustering Output 👇

Hierarchical clustering
The endpoint is a set of clusters, where each cluster is distinct from the other cluster, and the objects within each cluster are broadly similar to each other.
Output 👇
The endpoint is a set of clusters, where each cluster is distinct from the other cluster, and the objects within each cluster are broadly similar to each other.
Output 👇

That's it for this project 👋
Please do let me know if there is any mistake.
A retweet for the first one would really mean a lot 🙏
If you liked my content and want to get more threads on Data Science, Machine Learning & Python, do follow me @PiyalBanik
Please do let me know if there is any mistake.
A retweet for the first one would really mean a lot 🙏
If you liked my content and want to get more threads on Data Science, Machine Learning & Python, do follow me @PiyalBanik
• • •
Missing some Tweet in this thread? You can try to
force a refresh





