
Both these images have NeuralHash: 1e986d5d29ed011a579bfdea
Just a reminder that visually similar images are not necessarily semantically similar images.
Just a reminder that visually similar images are not necessarily semantically similar images.


Love playing games like "Are these, technically, semantically similar images"?
All these images have NeuralHash: ba9f4edd1233a856784b2dc4
All these images have NeuralHash: ba9f4edd1233a856784b2dc4



Hashes generated using the instructions / script found here: github.com/AsuharietYgvar…
As I said, finding specific (funny) collisions is trivial for perceptual hashes.
To be fair to Apple NeuralHash does seem at least somewhat resistant to -random- collisions (over the small set of tens of thousands of images I've thrown at it today...).
To be fair to Apple NeuralHash does seem at least somewhat resistant to -random- collisions (over the small set of tens of thousands of images I've thrown at it today...).
https://twitter.com/SarahJamieLewis/status/1428004811849404428
I let NeuralHash run most of the day in the background processing ~200K images. Didn't find any absolute "random" hashes (a few were 2-3 bits close) - but did find a few sets like this - sets of burst photos which match
All have the same hash: 75bbd25662074bdc7ac97677
All have the same hash: 75bbd25662074bdc7ac97677



NeuralHash seems to fail pretty easily on photos with small difference across a mostly static background - burst photos (and comic strips) being a common way of achieving this.
Interesting because all these would count as different photos in the context of a system.
Interesting because all these would count as different photos in the context of a system.
The Apple system dedupes photos, but burst shots are semantically *different* photos with the same subject - and an unlucky match on a burst shot could lead to multiple match events on the back end if the system isn't implemented to defend against that.
I also wonder about the "everyone takes the same instagram photos" meme and how that winds it's way into all of this.
During experimentation today I ended up with a couple of very near matches so I've been playing with this great little tool (
Here is 11f6794bacf037d93aced8e0
https://twitter.com/anishathalye/status/1428164089231069187) to see what it takes to mash them together.
Here is 11f6794bacf037d93aced8e0


Fun to note that because the originals were already near each (15fc79cfaef00d997ac65ce0 vs 15fc79cfaef01df9aecf7ee0) other it only took a few seconds each to modify them both to collide.
Here are another two: a852759b6dc0e748f04bf567
(Started off as: a852759b6dc0e708fbcbf767 vs aa52759b6de0cf8db01bb545 )
(Started off as: a852759b6dc0e708fbcbf767 vs aa52759b6de0cf8db01bb545 )


I can do faces too: 152d7772a8d47e156ef90a22


Those two started off as 152d77722cd02e3f66fb8a22 and 152e6e1508d0fe11ae59c9f0 and took a little more massaging to lower the obvious artefact - I think it could probably be better.
These are clearly the same image :) 72cb88a3e718d8c3c22cd118


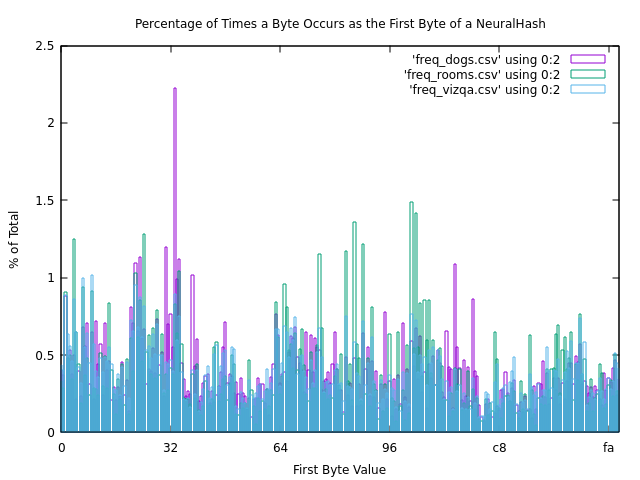
Could be a dataset limitation, but after amassing a few hundred thousand samples I suspect at this point that not all 12 byte sequences are viable NeuralHashes.
Some naturally occurring collisions found by @braddwyer in ImageNet which have the same features as above (static background, smaller subject).
blog.roboflow.com/nerualhash-col…
blog.roboflow.com/nerualhash-col…
I have things to do today but later this evening I will write this up in more depth because there is a lot of misconceptions flying around about what is and isn't interesting/relevant.
Until then check out my last post on the whole Apple PSI system: pseudorandom.resistant.tech/ftpsi-paramete…
Until then check out my last post on the whole Apple PSI system: pseudorandom.resistant.tech/ftpsi-paramete…
Write up is here:
https://twitter.com/SarahJamieLewis/status/1428496216615047173
• • •
Missing some Tweet in this thread? You can try to
force a refresh


