
We can prompt language models for 0-shot learning ... but it's not what they are optimized for😢.
Our #emnlp2021 paper proposes a straightforward fix: "Adapting LMs for 0-shot Learning by Meta-tuning on Dataset and Prompt Collections".
Many Interesting takeaways below 👇
Our #emnlp2021 paper proposes a straightforward fix: "Adapting LMs for 0-shot Learning by Meta-tuning on Dataset and Prompt Collections".
Many Interesting takeaways below 👇
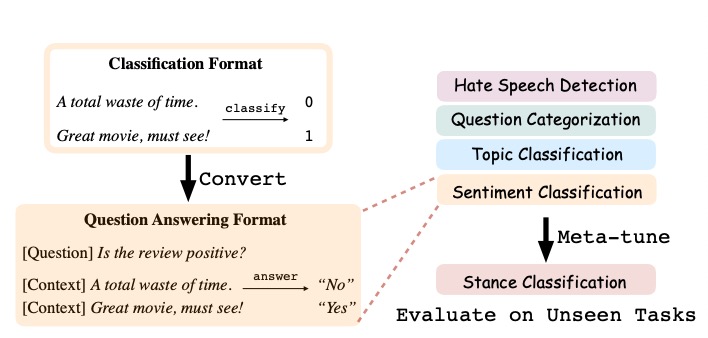
1. Prompting a language model out of the box can be highly suboptimal. For example, GPT-3 (175B parameters) gets 80% on SST-2 zero-shot, while UnifiedQA (700M) get 92% 🤔 so even being adapted to generic question answering can make a 200x smaller model better ...
2. We fix this by directly fine-tuning the model to produce the desired output given the task description and the task inputs. To get the training data, we unified datasets from 43 different sources into the same QA format and wrote 441 task descriptions in total *on our own*.

3. After directly optimizing for 0-shot learning, our model outperforms a same-sized QA model and the previous SOTA based on NLI. Hence, early measurement of GPT-3's ability based on prompting, though impressive already, might still be *broad underestimations* of what it can do
4. Larger models better. No surprise. But T5 with 70M parameters can't beat random baseline, while it suddenly generalizes 0-shot with 220M. The discontinuity is disturbing for research planning and safety - unpredictable properties can emerge in future LMs and catch us off guard
5. Training on more datasets and prompts help, and we as a community should collect and unify more tasks and datasets! Looking forward to BigScience by @huggingface, and tagging some other concurrent unification efforts here: CrossFit @qinyuan_ye , FLEX @turingmusician , etc
6. Dataset unification involves a lot of legwork and is much messier than it seems. What format should we unify towards? What counts as 0-shot generalization? how to split the tasks for train & test? How to weight the accuracy on each task for fair evaluation?
A couple of extensions we didn't work on due to resource constraint (but not necessarily easy-to-implement)
1. we focused on binary classification -> extend to general seq2seq
2. 0-shot -> few-shot
3. meta-tune on larger models
1. we focused on binary classification -> extend to general seq2seq
2. 0-shot -> few-shot
3. meta-tune on larger models
Paper: arxiv.org/abs/2104.04670 . Code: github.com/ruiqi-zhong/Me… . Excited that the above findings get into #emnlp2021 findings! #NLProc
• • •
Missing some Tweet in this thread? You can try to
force a refresh


