
⏱️ Just ten more days until the release of @java 17, the next version with long-term support! To shorten the waiting time a bit, I'll do one tweet per day on a cool feature added since 11 (previous LTS), introducing just some of the changes making worth the upgrade. Let's go 🚀!
🔟 Ambigous null pointer exceptions were a true annoyance in the past. Not a problem any longer since Java 14: Helpful NPEs (JEP 358, openjdk.java.net/jeps/358) now exactly show which variable is null. A very nice improvement to #OpenJDK, previously available only in SAP's JVM. 
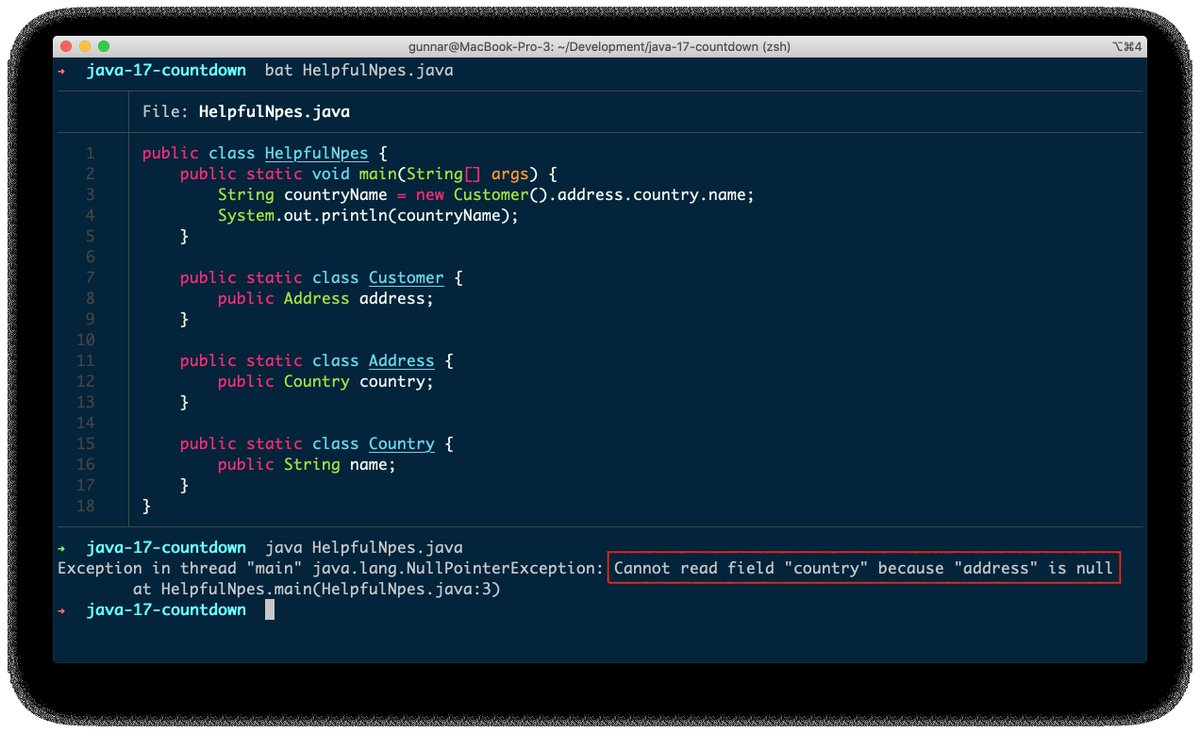
9⃣ Varying load and new app instances must be started up quickly? Check out class-data sharing (CDS), whose dev exp has improved a lot with JEP 350 (Dynamic CDS Archives, Java 13); also way more classes are archiveable since Java 15. More details here: morling.dev/blog/smaller-f…

8⃣ Adding JSON snippets to your Java code, e.g. for tests? Or multi-line SQL queries? Much easier now thanks to text blocks, without any escaping or concatenation. After two preview cycles, text blocks were added as stable language feature in Java 15 (openjdk.java.net/jeps/378).

7⃣ Flight Recorder has changed the game for JVM performance analysis. New since Java 14: JFR event streaming. Either in-process (JEP 349), or out-of-process since Java 16. "health-report", a nice demo of the latter, introduced in this post by @ErikGahlin: egahlin.github.io/2021/05/17/rem…


@ErikGahlin 6⃣ Occasionally, you need to take specific actions depending on the type of a given object -- just one use case for pattern matching. Added in Java 16 via JEP 394, with more kinds of patterns to be supported in the future. Details in this post by @nipafx: nipafx.dev/java-pattern-m….

@ErikGahlin @nipafx 5⃣ Running application and database on the same host? Looking for efficient IPC between the processes of a compartmentalized desktop app? Then check out Unix-Domain Socket Channels (JEP 380), added in Java 16. Discussing several use cases in this post: morling.dev/blog/talking-t…
4⃣ Excited about pattern matching (6⃣)? Then you'll love switch expressions (JEP 361, added in @java 14), and pattern matching for them (brand-new as preview in 17). Super-useful together with sealed classes (finalized in 17). Note how the non-exhaustive switch fails compilation.

3⃣ Vectorization via #SIMD (single instruction, multiple data) can help to significantly speed up certain computations. Now supported in @java (JEP 414, incubating), fully transparent and portable across x64 and AArch64. Even FizzBuzz faster than ever 😜!
morling.dev/blog/fizzbuzz-…
morling.dev/blog/fizzbuzz-…

@java 2⃣ Elastic Metaspace (JEP 387), ZGC and Shenandoah collectors ready for production (377/379), G1 NUMA support (345), G1 quickly uncommitting unused memory (346, some details here:
https://twitter.com/gunnarmorling/status/1271745151585718273) -- Tons of improvements related to GC and memory management since @java 11!
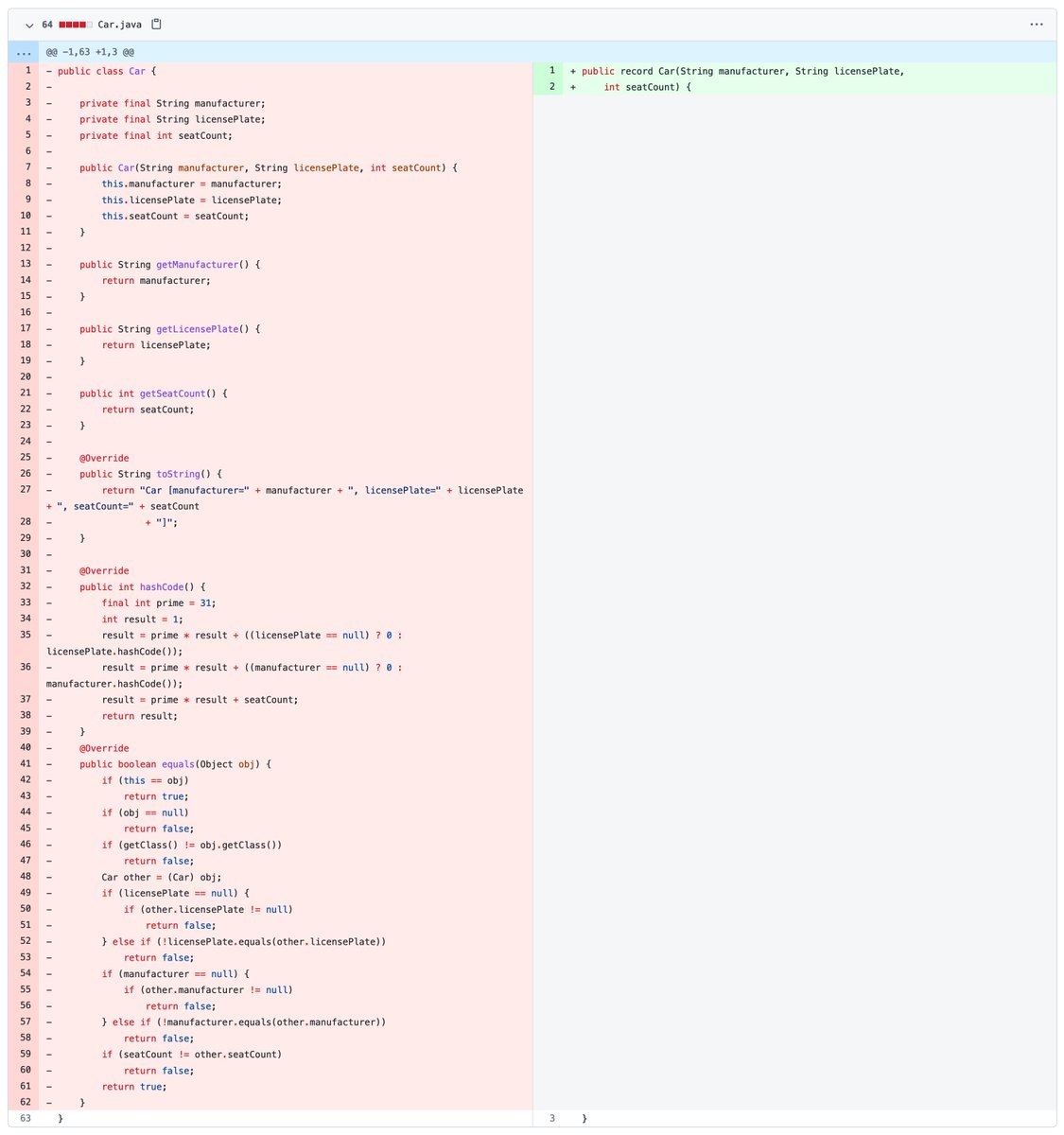
1⃣ Records, oh records! Long-awaited and going through two previews, @java language support for nominal tuples has been finalized in version 16 (JEP 395). Great for immutable data carriers like DTOs. A nice discussion of record semantics here by @nipafx: nipafx.dev/java-record-se….
• • •
Missing some Tweet in this thread? You can try to
force a refresh


