
An ultra-long read update. Since @circulomics is "no longer available" for @nanopore people might be interested in these protocols from @longreadclub @NininUon and @DrT1973 - a toolkit of options here dx.doi.org/10.17504/proto… including monarch from @NEBiolabs - 🧵below with more.
Ultra-long sequencing (N50s >100kb) jumped in performance in 2020 with new kits from @nanopore and @circulomics giving yields in excess of 20 Gb. In particular massively improved occupancy seemed to be a major benefit. 



However, it's not always possible to start with a specific extraction method and we wanted to explore alternative methods that would give the same or better performance, using as many different approaches as possible. Little did we know that this might become more useful now!
We found that the @NEBiolabs monarch kit could generate great UL DNA to go into a @nanopore ULK-001 but still needed a method to clean up the library.


Aside: This is where Nemo comes in.... Sometimes a small change can make a big difference. If you try the protocol you will find out why we called it Nemo (a small fish!).
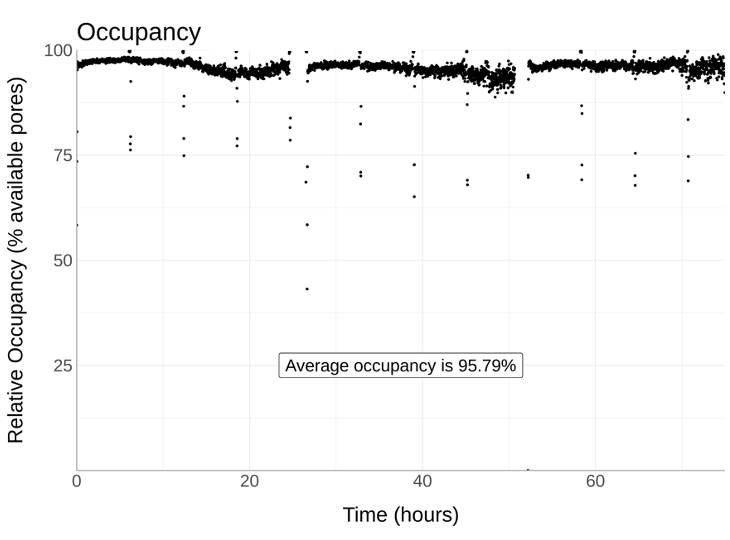
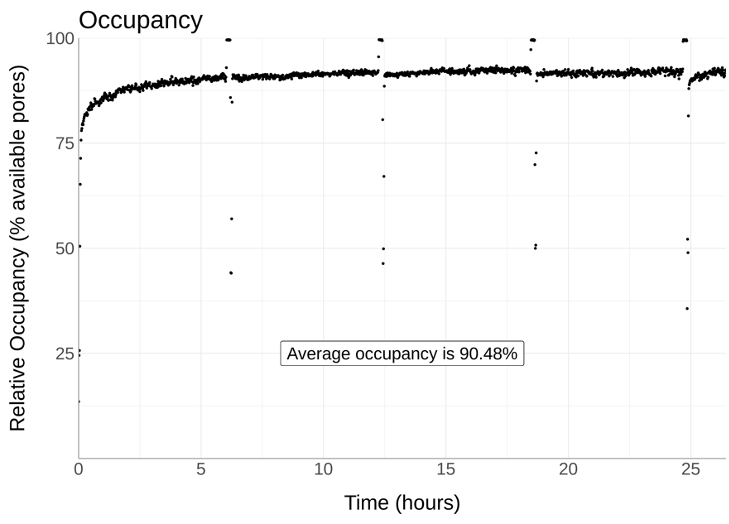
This shows the Nemo library cleanup giving N50s >100kb with high throughput and high occupancy. All these data are from human cell lines.



We even found we could use standard phenol chloroform extraction and Nemo clean up to get great performance - note this is an already used flow cell >9Gb of 119kb N50 from an 800 pore flow cell. (We used to be happy with 1.5 Gb from an amazing flow cell!)



We also have a protocol that will allow you to extract from cells, make an UL library and load in one day (but DNA homogeneity will affect yield). dx.doi.org/10.17504/proto…
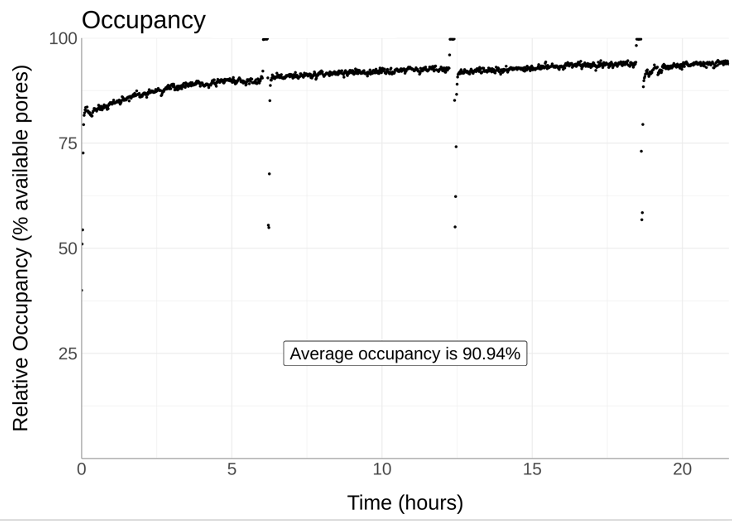
These protocols also work on PromethION and the cells do not have to be from human material. Here is @circulomics extracted non human DNA run using Nemo clean up for 20 hours on a PromethION...
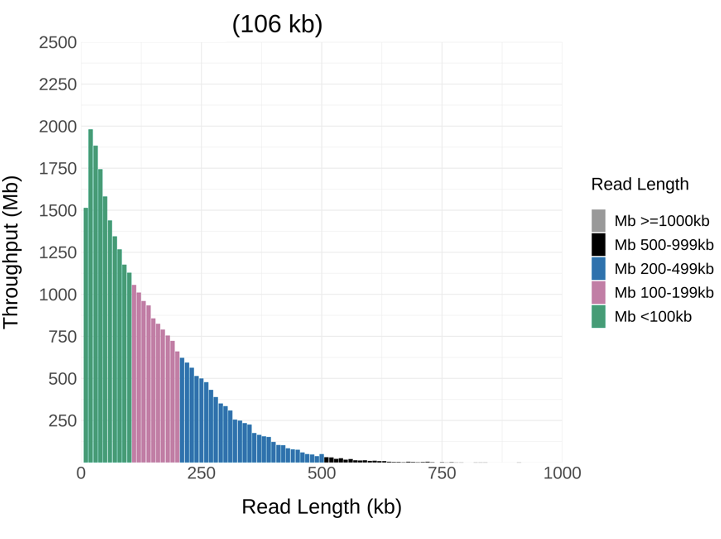
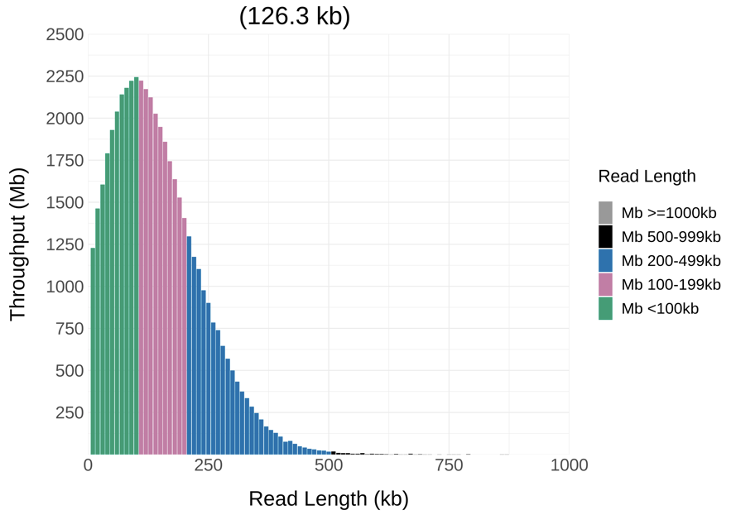
And here are the same cells on the same flow cell but extracted with @NEBiolabs monarch kit and cleaned up using Nemo (similar run time).
Also in these protocols are ways to replicate this performance using RAD004 and additional methods for library prep from @DrT1973 which we hope will help a wide range of users. We find we need to optimise protocols to input type - this is particularly true for tissue.
Preprint with more details on performance to come - we hope these protocols are useful for the wider community. Thanks to @DrT1973 @scalene @pathogenomenick @NininUon @longreadclub @NEBiolabs @circulomics @DeepSeqNotts and @nanopore for all sorts of useful help.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


