
Conversation is a dance, how do we learn? In this systematic review & meta-analysis we thoroughly explore models & evidence for how turn-taking develops and which factors are involved. Comments & suggested pub venues are very welcome. Long thread 1/ psyarxiv.com/3bak6 

This was a brilliant student-led project by Vivian Nguyen & Otto Versyp from Ghent University, who spent their Fall 20 on an internship (aka regularly zooming) with me and @ChrisMMCox 2/
Turn taking is a very fascinating phenomenon. @Evol_of_Com & @Sonja_Vernes argue that it might be a cornerstone for animal communication in a very inspiring paper (royalsocietypublishing.org/doi/full/10.10…) 3/
& I had a very thought-provoking co-supervision w @frantsjensen on turn-taking in pilot whales (joining in more than turn-taking). Amazing methods being developed here which we auspicate should be taken up in cog/dev science, but I digress 4/


Turn taking in humans is also regarded as a reliable cross-cultural phenomenon, with fast average response latency, ranging between 0 ms (Japanese) and 500 ms (Danish, of course, @PuzzleOfDanish ). Here a paper comparing 10 languages: pnas.org/content/106/26… 5/
How do human infants develop their ability to seamlessly engage in turn-taking? Some (journals.sagepub.com/doi/10.1177/14…) assume a set of required socio-cognitive abilities (e.g. theory of mind), others more implicit interpersonal attuning ( pubmed.ncbi.nlm.nih.gov/16615316/) 6/
These models, albeit too underspecified (@chbergma!), provide guidelines to assess the factors at play in turn taking: infant age (proxy for cog & ling development), adult response latency, familiarity of context and interlocutors (easier to predict), atypical development 7/
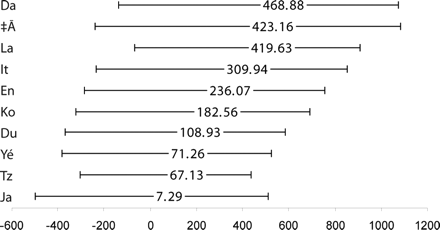
We first perform a systematic search yielding 26 papers with usable estimates and 78 total estimates, often reported as side findings compared to the main goal of the paper, and by far and large focusing on US children. 8/
We assess how similar these papers are in who they cite (left figure) and how well they cite each other (right figure). Perhaps unsurprisingly the field looks very fragmented. 9/

We assess the overall patterns of response latency. Infants tend to take around 1s to respond, on average. My children’s educators keep saying to wait up to 30s to give them time to say something, which seems about right, but the vast majority of turns will be faster. 10/

How about development? The Interaction Engine Hypothesis predicts a slow down as the infants get to produce more complex linguistic vocalizations, followed by a speed up. 11/
This is indeed what we see (but not as pronounced and at a slower pace than predicted in either the original formulation, or subsequent ad hoc corrections). 12/

The other major prediction of response latency in the child is - surprise! - the adult’s response time. The slower the adult, the slower the child, and vice versa. 13/
The data we have access to is terrible (aggregate, cross-sectional, confounded), so we cannot further explore interpersonal adjustment and its interactions with age. 14/
Data in atypical populations is again too sparse to say much except that atypical groups are generally slower. 15/

So what? I always rant that sys revs and m-as are a critical moment of self-reflection for a field, more to provide a way for better future studies than to estimate effects and test hypotheses (which we can and should, but only tentatively, e.g. doi.org/10.1101/2021.0…). 16/
First, there is much to learn by working together, with animal communication researchers, computational modelers, developmental psychologists, conversation analysts, etc. The current fragmented field doesn’t promise well, but we can do better (just use our paper :-P) 17/
Second, we need better data. We need diverse cross-linguistic longitudinal corpora, with turn-by-turn data, and possibly data on the linguistic, cognitive and social development of the child. 18/
Relatedly, not all turn-taking is equal. Different conversational moves & complexity will afford different response latencies. We need better (and less painful) ways to automate our coding of conversational moves (a la @mitjanikolaus @Adinseg & @clairebergey @danyurovsky ). 19/
We also need a higher awareness of organizational sequences (a la @KristenBott and @irisnomikou ) and well, that'll challenge automated attempts at coding, but that's not a reason to give up! 20/
Third, we need better standards and models. @middycasillas works on standard pre-processing for turn-taking data (escholarship.org/uc/item/4rr848…). 21/
We have been working on implementing several models from the animal communication field to more systematically assess the structure of turn taking (not yet available). 22/
But we need more: better specified models of turn taking development, and interpersonal adjustments. They’ll be wrong & reductionists, but we need to put our assumptions out there and test them collectively. Let’s share in the fun and frustration of figuring out turn-taking! 23/
Finally, I should acknowledge all the cool things that R packages like igraph, bibliometrix, ##brms (and @mcmc_stan) allow us to do. Robust regressions with missing data, easy assessment of networks, ad hoc contrast testing. Meta-analyses can be so much more rigorous now!
• • •
Missing some Tweet in this thread? You can try to
force a refresh






