
Primer combines L1-BN (arxiv.org/abs/1802.09769), Conformer (arxiv.org/abs/2005.08100) and "Squared ReLU" to reach up to 4x faster convergence at no additional memory cost.

https://twitter.com/ak92501/status/1439751096969334785

This speedup is almost as significant as Switch Transformer's (arxiv.org/abs/2101.03961). It got up to 7x speedups using 64x as many (sparse) parameters.
Primer, however, doesn't use more parameters. It's also orthogonal to Switch, so a combined 32x speedup seems plausible.
Primer, however, doesn't use more parameters. It's also orthogonal to Switch, so a combined 32x speedup seems plausible.


There's just one slight issue: The baseline.
Primer compares itself with a default transformer and has no ablations of individual changes.
Instead, they trained a standard 2B GPT3-XL for 2 trillion tokens, spending well over $1,000,000 on this one figure.
Primer compares itself with a default transformer and has no ablations of individual changes.
Instead, they trained a standard 2B GPT3-XL for 2 trillion tokens, spending well over $1,000,000 on this one figure.

For example, @lucidrains found that depthwise convolution helps, but not as much as token-shift. Similarly, SquaredReLU is worse than GEGLU or SquaredReLU-GLU, but Primer doesn't compare against either.
If you want to stay up-to-date, go join #EleutherAI: discord.gg/ybj3dQPs
If you want to stay up-to-date, go join #EleutherAI: discord.gg/ybj3dQPs
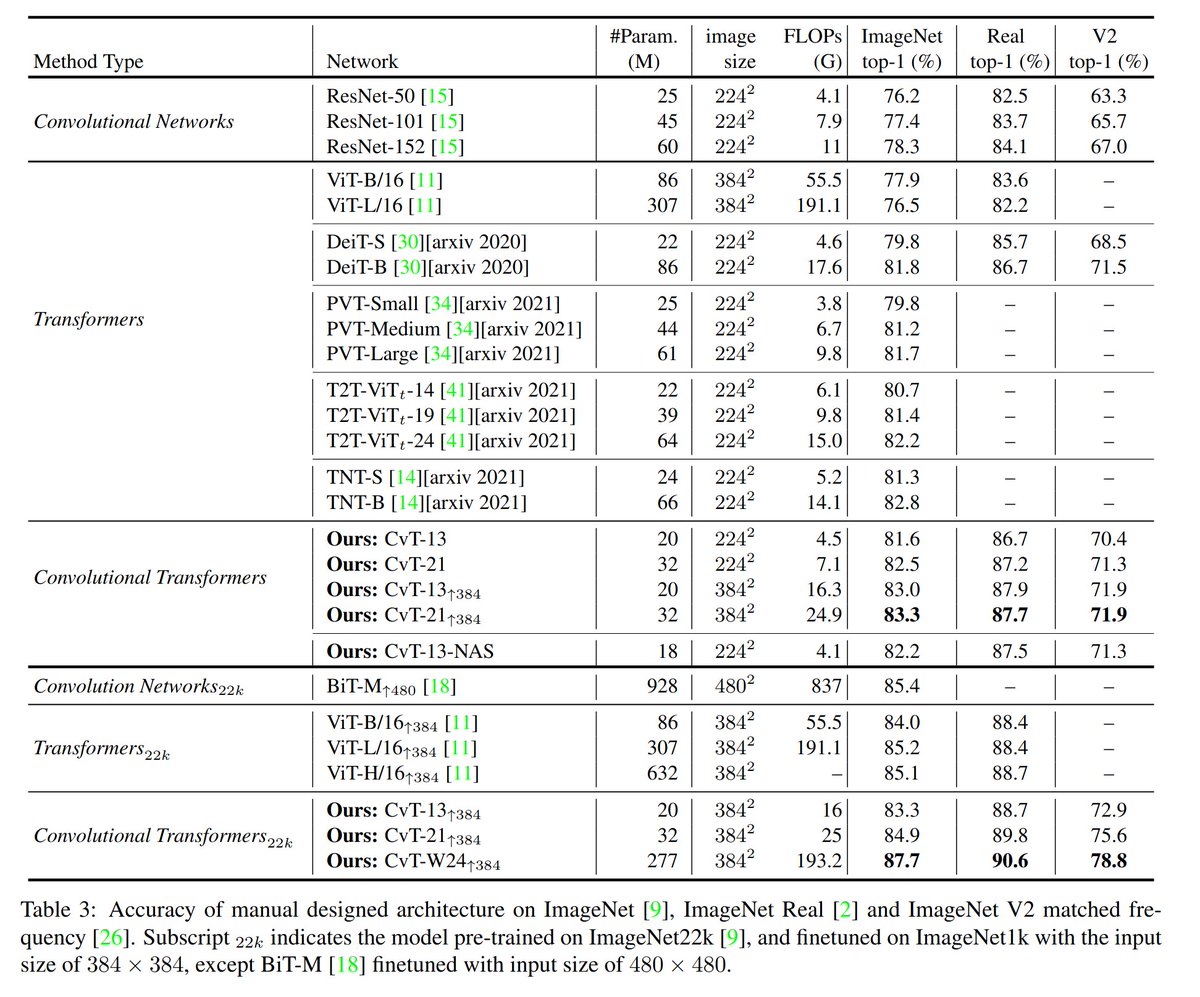
The fact that Convolution + Attention (or Local + Global) is better than pure local or pure global was explored extensively in works like Nytrömformer (arxiv.org/abs/2102.03902), CvT (arxiv.org/abs/2103.15808) and Long-Short Transformer (arxiv.org/abs/2107.02192).
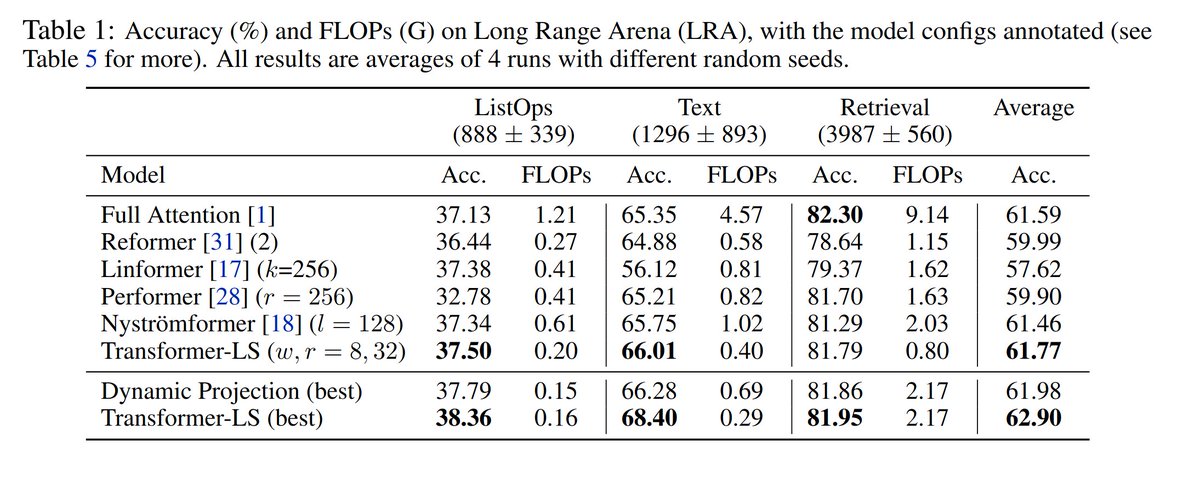
Similarly, L1-Normalization (arxiv.org/abs/1802.09769) showed higher stability and was verified independently (
However, nothing that they found is genuinely novel.
https://twitter.com/wightmanr/status/1435080008129601542). So, if anything, Primer indicates that these modifications might be here to stay.
However, nothing that they found is genuinely novel.

In fairness with Primer, they cite CvT as [43], but the difference is minuscule. CvT uses a regular convolution, while Primer "applies convolution for each head separately".
Separate convolutions can be implemented efficiently by simply adding groups to CvT's convolution.
Separate convolutions can be implemented efficiently by simply adding groups to CvT's convolution.

• • •
Missing some Tweet in this thread? You can try to
force a refresh













