
The mean squared error is probably one of the very first evaluation metrics that you might've used when making machine learning models.
Yet most people don't have a clear intuition about how it works, let's fix that today!
🧵 👇🏻
Yet most people don't have a clear intuition about how it works, let's fix that today!
🧵 👇🏻
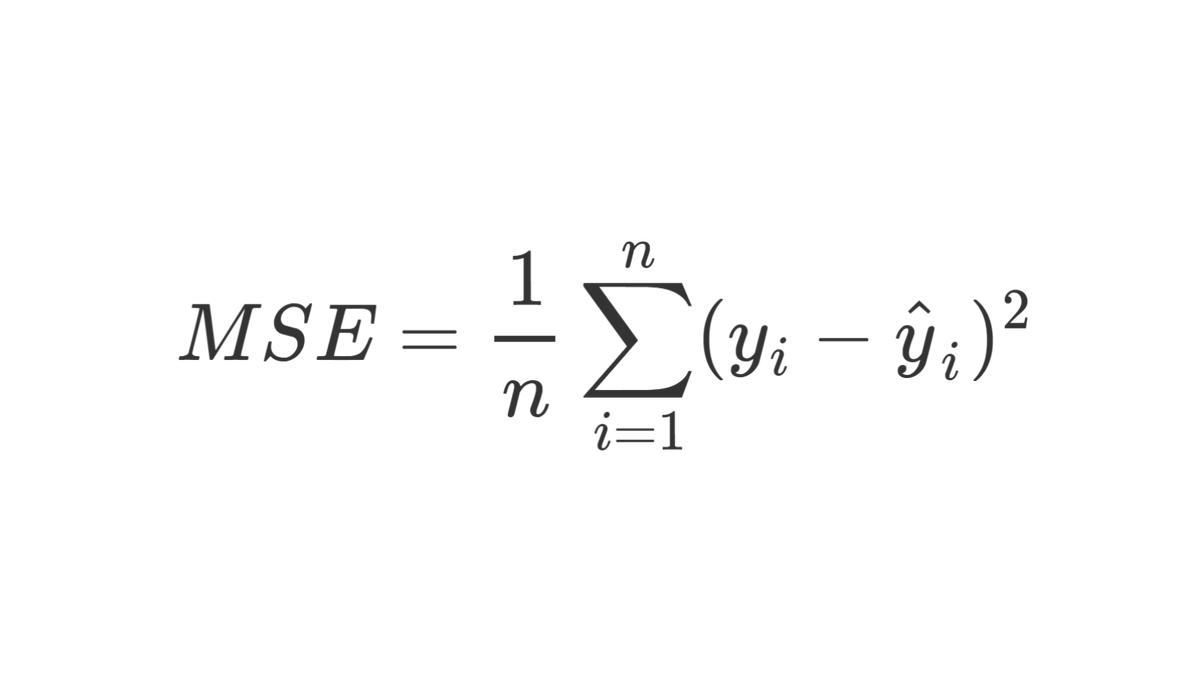
📍 The mean squared error (MSE) is a common loss function used for 'regression' problems.
Regression models are used for predicting quantitave values based on data like the prices of houses in an area, future height growth of a plant etc.
Regression models are used for predicting quantitave values based on data like the prices of houses in an area, future height growth of a plant etc.
📈 MSE is calculated as the sum of the squared difference between the predicted and actual values of the target variable.
Let us break this down with the help of an example 👇🏻
Let us break this down with the help of an example 👇🏻
A linear regression model is trained on some data of plants to predict their lifespan.
This picture shows one of the data points, the height and its corelation to the lifespan along the predicted lifespan according to our linear regression model.
This picture shows one of the data points, the height and its corelation to the lifespan along the predicted lifespan according to our linear regression model.

You can notice how the predicted lifespan does not exactly coincide with the values of the ground truth.
The difference between the predicted value and the actual value is the ‘error’.
The difference between the predicted value and the actual value is the ‘error’.

These errors can be positive for negative, for example:
• If the predicted lifespan is 10 years and the actual lifespan is 5 years, the error is -5 years
• Similarly, if the predicted lifespan is 5 years and the actual lifespan is 10 years, the error is +5 years.
• If the predicted lifespan is 10 years and the actual lifespan is 5 years, the error is -5 years
• Similarly, if the predicted lifespan is 5 years and the actual lifespan is 10 years, the error is +5 years.
⚠️ You will notice that adding these up, we get an error of -5 + 5 = 0, which does not make sense, there is an error but its not being reflected.
Which is why we square these errors and then sum them up so that the error is actually being reflected.
Which is why we square these errors and then sum them up so that the error is actually being reflected.
In the previous case, squaring them (-5² = 25, 5² = 25) then adding them (25+25) gives us 50.
Thi signifies that there is an error unlike just adding them as is which gives us 0.
This is called the residual error and forms a part of the MSE formula.
Thi signifies that there is an error unlike just adding them as is which gives us 0.
This is called the residual error and forms a part of the MSE formula.

We sum up all the residual errors, hence the Summation (Σ) in the formula.
You can read about sigma notation here if you don't know how it works 👇🏻
🔗 mathsisfun.com/algebra/sigma-…
You can read about sigma notation here if you don't know how it works 👇🏻
🔗 mathsisfun.com/algebra/sigma-…

Then we divde this by all the number of data points (1/n) to get the ‘mean’ or average, which gives the MSE.

Let's recap, we're taking the errors (red parts), squaring them and then adding them all up.
Finally we divide all of this with the number of data points giving us the MSE which is how "wrong" our model is.
The lower the MSE, the better the model is.
Finally we divide all of this with the number of data points giving us the MSE which is how "wrong" our model is.
The lower the MSE, the better the model is.

Theoretically lets say the MSE is 0 then the model is perfect, all the predictions will exactly match with the ground truth.
In this example we’ll be able to predict the lifespan of a plant with a linear regression model 100% correctly.
In this example we’ll be able to predict the lifespan of a plant with a linear regression model 100% correctly.
On the other hand if the MSE is very high, then the model is not very accurate, it will predict the lifespan of a plant with a high degree of error.
With all that being said, this metric isn't perfect, there are some caveats when using the MSE 👇🏻
With all that being said, this metric isn't perfect, there are some caveats when using the MSE 👇🏻
1️⃣ Avoiding overfitting
We have to be careful when using this metric, as sometimes when the MSE is low, the model may be overfitting, which means that the model is not able to generalize well to new data.
We have to be careful when using this metric, as sometimes when the MSE is low, the model may be overfitting, which means that the model is not able to generalize well to new data.
2️⃣ Exaggeration because of outliers
Since we are squaring the errors, we can also get a high MSE if even some of the residual errors are high which can be a problem. In order to avoid this, we can use the Root Mean Squared Error (RMSE), which is the square root of the MSE.
Since we are squaring the errors, we can also get a high MSE if even some of the residual errors are high which can be a problem. In order to avoid this, we can use the Root Mean Squared Error (RMSE), which is the square root of the MSE.

If you liked this thread make sure you retweet it and follow @PrasoonPratham.
I make a lot of content about machine learning and web3 that you don't want to miss out on.
I make a lot of content about machine learning and web3 that you don't want to miss out on.
• • •
Missing some Tweet in this thread? You can try to
force a refresh









